An sich geht es ganz einfach. In der Administration geht man auf Update, bestätigt alles, die Plugins werden deaktiviert (vielleicht auch das Language-Pack) und dann startet der Installer und .. läuft in einen Fehler und dann läuft garnichts mehr. Scheint jeden Falls öfters mal so zu passieren.
Ich hab mir ein Script gebastelt mit dem man sich eine Kopie des Shops auf die neue Version updaten kann und dann später auf diese Kopie switchen kann.
Man muss nicht alle Plugins deaktiveren, aber einfacher ist es. Also eine Kopie (Dateien und Datenbank) anlegen und da alles Plugins deaktiveren. Per SQL-Statement geht es recht schnell und einfach.
Der original Shop liegt in shop/ und der neue in shop65/. Die .env der Kopie (wegen DATABASE_URL) wird in shop_shared/ abgelegt und um LOCK_DSN="flock" und SHOPWARE_SKIP_WEBINSTALLER=1 ergänzen.
Dann das Script laufen lassen.. oder besser Zeile für Zeile per Hand ausführen.
cd ~/public_html/shop65 && composer update
cd ~/public_html/shop65 && bin/console system:update:finish
cd ~/public_html/shop65/vendor/shopware/administration/Resources/app/administration && npm install && cd ~/public_html/shop65
Ziel ist es wieder in die Administration zu kommen und dort alle Plugins zu aktualisieren. Wenn das gelungen ist, dann alle nach und nach wieder aktivieren und wieder die Themes in den SalesChannels einrichten.
Wenn Fehler auftreten immer mal wieder bin/console aufrufen, weil dann die Exceptions meistens ganz gut dargestellt wird.
So kommt man auch sehr gut ohne den Installer zu seinem aktuellen Shopware und räumt auch direkt noch etwas auf.
Arbeiten mit Dateien ist in Shopware 6 an sich recht einfach, gerade seit die Media-Entity und deren Thumbnails ein Path-Feld haben, in dem der relative Pfad direkt angegeben werden kann. Wenn man den hat muss man nur noch den absoluten Pfad bauen. Wenn man z.B. in das public/ Verzeichnis will um dort etwas zu hinterlegen oder ein Media-File zu lesen kann man sich die Umgebungsvariable mit Symfony Project Root per Dependency Injection direkt in den Constructor seines Services geben und von da aus dahin navigieren. Von der aktuellen PHP-Datei aus ist es nicht so toll, da man nicht immer weiß wo das Plugin sich befindet. Z.B: kann es im custom-Folder oder irgendwo in vendor/ sich befinden.
<argument>%kernel.project_dir%</argument>
Und was ist wenn man die Dateien in einem Cluster-Betrieb über ein S3-Bucket an die Cluster-Nodes verteilt? Shopware 6.5 hat zum Glück nicht nur Flysystem dabei, sondern nutzt es auch richtig. Man kann sich direkt per Dependency Injection das privater oder das öffentliche Dateisystem geben lassen und dann ist es egal ob es auf einem FTP, in einem S3 Bucket oder im lokalen Dateisystem liegt.
namespace HPr\FSTest\Services;
use League\Flysystem\FilesystemOperator;
use Shopware\Core\Content\Media\MediaEntity;
class MediaTest {
public function __construct(private FilesystemOperator $filesystem){}
/**
* @throws FilesystemException
*/
public function md5Media(MediaEntity $media): string {
return md5($this->filesystem->read($media->getPath()));
}
}
Um nun das passende Dateisystem zu bekommen ist nicht viel nötig.
Public ist das öffentliche Verzeichnis, das man für Product-Bilder, CMS-Media oder auch andere Downloads nutzen kann, die jeder sehen darf. Dann gibt es auch das private Dateisystem, wo man alles wie Rechnungen und Dinge ablegt, die nicht jeder sahen darf und wo man den Zugriff am besten durch einen eigenen Controller kapselt. Die MediaEntity hat einen private-Flag, um anzugeben in welchem Dateisystem man die Datei findet.
Das Dateisystem selbst kann man in einer YAML-Datei in config/packages/ definieren. Wie man da z.B. seine Dateien in einem MinIO S3 Bucket ablegen kann, habe ich in einem Post vorher schon erklärt.
Da man beim einfachen Entwickeln nicht ein AWS S3-Bucket für die Entwickler bereit stellen möchte, kann man hier sehr gut MinIO verwenden. Es lässt sich schnell in docker-compose einbinden und die FileSystems von Shopware können den normalen S3-Adapter verwenden.
Manchmal braucht einfach Imagick. Z. B. wenn man eine Bildvorschau einer PDF erzeugen will oder einfach mehr Power bei der Bildbearbeitung in PHP oder in Scripten braucht.
Während die Installation die meisten Anleitungen für Docker und Imagick mit den default PHP Docker-Image super funktionieren ist es bei Dockware anders, weil es eine volle Ubuntu-Umgebung mitbringt.
Zu beachten ist, dass man für alle PHP-Versionen die Erweiterung installieren muss.
Manchmal funktionieren ein paar Snippets nicht. Ich vermute es liegt daran wie ein Theme über nicht immer sehr gradlinige Wege überschrieben und erweitert wurde.
Z.B. steht dann "orion.footer.certificates" auf der Seite, obwohl die Snippets korrekt für alle Sprachen in der Administration gefunden werden. Also an sich sollte es dann ja funktionieren.
Lösung: Einmal den Übersetzungen ein 'X' anhängen, speichern, das 'X' wieder entfernen und erneut speichern. Dann sind sie in der Storefront auch richtig.
Weil sie dann aus der Datenbank geladen werden und nicht aus dem Theme/Plugin/App.
Zum 2024-01-01 hat One-DC Teile ihrer Dropshipping-Services abgeschaltet. Man kann immer noch Bestellungen dort per API aufgeben und diese direkt an seine Shopkunden senden, aber es gibt keine Feeds mit Produkten, Beständen und Preisen mehr. Der Sinne erschließt sich mir überhaupt nicht, da Dropshipping ja doch irgendwie weiterhin möglich ist und elektronische Katalogdaten auch für PIMs und Kassensysteme der Kunden wichtig ist. Hätte man den Versand an die Endkunden eingestellt würde ich es ja noch verstehen, aber so macht es für mich keinen Sinn. Falls jemand mehr Weiß oder eine Möglichkeit kennt Katalogdaten weiterhin zu erhalten, bitte sich per Email bei mir melden.
Import2Shop stellt deren Anbindung zu EDC auch ein und die Shops sitzen jetzt und versuchen möglichst schnell zu einem anderen Anbieter zu wechseln. Meine Plugins bleiben weiter online, erhalten aber keine Weiterentwicklung mehr und gelten ab sofort als EOL, wenn nicht sich doch noch was neues ergeben sollte.
Bei in Java bei XML ist die bekannteste Lösung manchmal nicht die Lösung, die man gerade braucht. Groß, komplex und kann alles. Dependencies machen dann aber Probleme und wenn man nur eine Datei schnell und einfach lesen möchte, braucht man nicht irgend eine HTML-Lib, die nur in ganz bestimmten Fällen nötig wäre.
Beim Lesen von Excel-Dateien in PHP ist es genau so. HTML-Lib machte Probleme beim Installieren über Composer, aber ich will ga rkeine HTML-Sachen damit machen. Cool das es gehen würde, aber ich will nur schnell und einfach die Daten der Tabelle auslesen. CSV hätte ja gereicht, aber es kommt eben eine Excel-Datei.
Viele erinnern sich noch an Zeiten, wo man direkt auf einem Webserver seinen HTML-Seiten und Scripts geschrieben und getestet hat. HTML ging meistens schon lokal, aber wenn es um PHP oder anderes ging brauchte man einen Server. Dann schwenkte man auf XAMPP um, wo man einen lokalen Apache nutze. Linux brachte den Apache und PHP direkt mit. Aber man hatte oft kein Linux und half sich mit VirtualPC oder VirtualBox, so man entweder eine shared Speicher hatte oder ganz klassisch per FTP oder später SCP/SSH seine Dateien aus der IDE ins Zielsystem bekam. Dann kam Docker und die Welt wurde gut.. über all gut? Nein, dann erstaunlich viele gerade im Agentur-Bereich arbeiten immer noch mit einem Server und einem FTP-Sync. Gut heute oft mit SFTP oder SCP, aber ohne Docker oder lokalen Webserver.
Während ich klassische vServer mit Apache und ohne Reverse-Proxy und Docker für veraltet halte, sind sie noch öfter Realität als Docker-/K8n-Umgebungen. Selbst shared-Hosting für produktive Umgebungen sind noch öfters anzutreffen.
Nach einem Gespräch, wo noch direkt auf dem Server gearbeitet wurde und nicht mal eine lokale IDE einen Sync in Richtung Server vornahm sondern direkt die Datei vom Server aus geöffnet wurde (da kann man fast direkt mit vi auf dem Server arbeiten...), hier eine einfache kostenlose Lösung, wo man wenigstens die Dateien lokal hat und so auch ohne Probleme mit Git arbeiten kann.
Genutzt wird VisualStudio Code (die Intellij-IDEs bringen so einen Sync direkt von Haus aus mit, kosten aber in den meisten Varianten Geld).
Ein Plugin installieren:
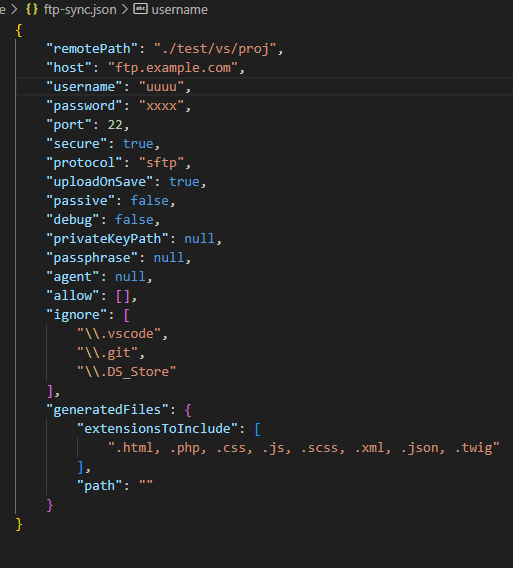
FTP-Config anlegen (wird geöffnet nach dem ersten Sync-Versuch):
Wenn uploadOnSave aktiviert ist am Besten die IDE noch mal neustarten.
Geht auf jeden Fall besser als WinSCP parallel zum Sync laufen zu lassen.
Würde ich so entwickeln wollen? Nein. Besonders wenn mehr als ein Entwickler an einem Projekt arbeiten, geht nichts über Docker. Für Shopware habe ich gute Images oder man nimmt Dockware, was gerade für Entwickler an sich vollkommen reicht.
Wie man eine eigene Entity in die Suche integriert hatte ich schon erklärt. Was aber wenn man eine vorhandene Entity um weitere durchsuchbare Felder erweitern will? Das geht auch relativ einfach.
if (module?.manifest?.defaultSearchConfiguration) {
module.manifest.defaultSearchConfiguration = {
...module.manifest.defaultSearchConfiguration,
extensions: {
// In case some other plugin has already done this trick; we do not want to remove theirs.
...(module.manifest.defaultSearchConfiguration.extensions ?? {}),
// Add our extension fields to the omnisearch
customFields: {
customer_debitor_set_number: {
_searchable: true,
_score: searchRankingPoint.HIGH_SEARCH_RANKING,
},
}
},
};
}
Auch wenn dort die Felder hierarchisch angegeben werden, sind diese bei den Snippets flach strukturiert.
In einem Cart-Validator sollte man vermeiden vom Cat-Service die getCart()-Methode zu verwenden. Ich habe einen Service der mir für den Validator benötigte Daten lieferte und dabei auch einen Wert aus dem Cart generierte. getCart() triggert aber wieder den Validator.. Endlossschleife! Also am besten wirklich nur das in die Validator-Methode rein gereichte Cart-Object verwenden.
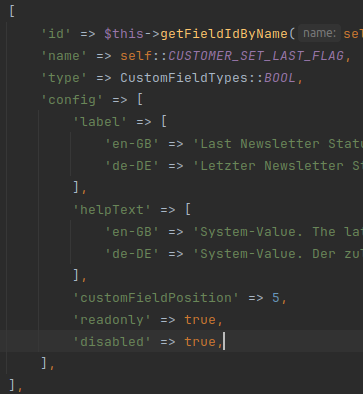
Es gibt manchmal CustomFields in denen man Daten wie externe Ids, ein Import- oder Export-Datum oder ein einfaches Bool-Flag speichern möchte. Der normale Admin-Benutzer darf diese Daten gerne sehen sollte sie aber nicht ändern, weil er oder sie nicht das nötige Wissen über die internen Abläufe des Plugins hat, um genau zu wissen, welche Auswirkungen so eine Änderung hat.
Deswegen ist es gut so ein CustomField readonly zu machen und am Besten komplett zu disablen. Das ist über die config des CustomFields sehr einfach möglich. In der Manifest einer App kann dass leider schon wieder ganz anders sein, weil dort sowas nicht vorgesehen ist.
Oft ist es sehr viel einfacher direkt etwas in die Suche der Administration einzugeben, als umständlich eine Seite zu öffnen und etwas aus der Liste per Hand oder Browser-Suche heraus zu suchen.
Eigene oder fehlende Entitäten dort zu integrieren ist an sich recht einfach und logisch. Es gibt hier eine Anleitung die aber leider so für mich nicht funktioniert hat, weil ein wichtiger Teil fehlte.
Routennamen sind hier erstmal nur Beispiel haft vergeben.
Step 1 Ich gehe davon aus das ein Plugin existiert mit einem JS-Module, das mindestens eine Route hat und dessen Name nach dem Schema {vendor}-{name} aufgebaut ist. Zum Module müssen wir wie beschrieben
einige wenige Dinge ergänzen:
{
...
entity: 'ce_my_entity',
...
}
hier kommt später noch was dazu!
Step 2
Den Type (der Entität) hinzufügen. Der Name muss nicht dem Namen der Entität entsprechen, ist aber nicht verkehrt es so zu machen.
Damit kennt die Suche nun den neuen Type und dann theoretisch schon danach suchen.
Step 3
Jetzt müssen wir festlegen wie unsere Entität bei den Ergebnissen dargestellt werden soll. Dafür erweitern wir ein Template und machen es der Suche bekannt.
Was noch fehlt Soweit ist alles gut und nach Anleitung. Aber es funktionierte einfach nicht. Es wurde nach allen möglichen Entitäten gesucht nur nicht nach der eigenen. Nach viel Gesuche kam ich dann darauf, dass bei den Preferences, die für die Liste der Entities genutzt wird, meine eigene garnicht aufgelistet wurde. Warum? Weil ich natürlich keine Preferences dafür hinterlegt hatte, weil es nirgendwo angegeben war.
Diese Preferences findet man im Profile seine Admin-Users und kann es dort alles noch genauer anpassen, wie die Suche suchen soll. Hier werden nun die Felder name und description angeboten und auch direkt aktiviert.
Damit funktionierte die Suche dann auch sofort wie gewünscht.
Wenn man sich in einer Shopware 6 SaaS Umgebung und Apps bewegt, hat man nicht mehr die Möglichkeit Rules im PageLoader zu prüfen und ein bool-Value rein zu reichen, weil man nun alles via Twig machen muss. Entweder im Template oder in den App Scripts, die die PageLoader-Events ersetzt haben.
Geht zum Glück an ganz einfach auch wenn es kein array_intersect gibt.
{% set hideBuyButton = false %}
{% set checkRuleIds = config('MyApp.config.checkRules') %}
{% set intersect = checkRuleIds|filter((rule) => rule in context.context.ruleIds) %}
{% if intersect|length > 0 %}
{% set hideBuyButton = true %}
{% endif %}
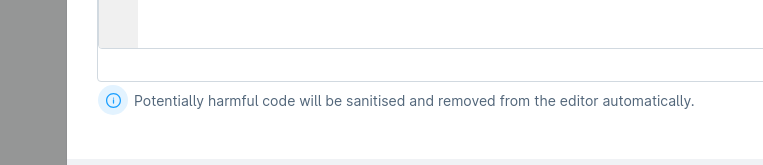
Während man in 6.4 noch beliebigen eigenen HTML-Code in z.B. CMS-Elementen oder Snippets eingeben konnte, filtert 6.5 Teile dieses Codes nun heraus. Er gilt als möglicherweise unsicher. Wenn man nun von 6.4 auf 6.5 migriert und z.B. style-Tags entfernt werden, wäre es sehr aufwendig alles nun in SCSS und dem Theme unterzubringen. Einfacher ist es den Sanitizer zu deaktivieren und das selbe Verhalten wie bei 6.4 wieder zu haben.
In der config/packages/shopware.yaml kann den Sanitizer einfach deaktiveren.
shopware:
html_sanitizer:
enabled: false
Older posts:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von