Die neue Version vom automatischen XML Order-Export, nutzt für openTrans2.1 XSLT und keinen PHP-Code mehr. Der Vorteil davon ist, dass so für jeden Anpassungen an der Ausgabe sehr viel einfacher werden. Man kopiert sich die vorhandene XSLT-Datei und kann die Kopie so anpassen wie man will. Im Plugin kann man die Datei dann angeben und diese anstelle der originalen XSLT-Datei verwenden.
Wenn man z.B. ein Attribute-Field zusätzlich als offiziellen openTRANS2.1 XML-Tag einbinden:
Irgendwann kommt jeder zu dem Punkt wo die Festplatte gegen voll tendiert. Dann bekommt man Nachtrichten: "Hilfe, bei C sind nur noch 11% frei!!!!". Erstens ist das vollkommen OK. Leerer Festplattenspeicher nutzt niemanden was. Man sollte immer einen Puffer für temporäre Dateien haben, aber wenn die Festplatte wirklich zu 100% gefüllt sein sollte, wird das System weiterhin noch funktionieren. Also kein Grund zur Panik.
Man hat aber eben viele Daten, Spiele, Fotos, Videos und so was alles, was nicht zwingend auf C: liegen muss und selbst die Verzeichnisse des Benutzerprofils kann man auf andere Laufwerke auslagern. Wenn man viele Sims, Dragon Age oder andere Mods in "Dokumente" liegen hat, kann man den Dokumente-Order auf eine andere Festplatte verschieben. Wenn C: eine SSD ist, kommt man schnell in die Situation, dass man Daten gerne auf einem anderen Laufwerk speichern möchte, um die SSD zu schonen und dort Programme und Spiele zu haben, wo man die Geschwindigkeit einer SSD auch merklich spürt.
Mein PC als Beispiel-PC
Ich erkläre hier wie man ganz einfach eine zusätzliche HDD (es ist das selbe Vorgehen bei einer SSD) in seinen PC einbaut und auch was man bei den Anschlüssen und Kabeln achten muss. Ich benutze dabei meinen PC (ein einfacher Standard-PC mit 2x 6C L5639 Xeon CPUs, 16GB RAM, 1x 240GB SSD, 1x 1TB HDD, usw) und eine refurbished 2TB SAS HDD.
An sich ist das alles ganz einfach. Früher musste man im BIOS noch die Festplatten einstellen oder erkennen lassen, aber das ist heute alles nicht mehr nötig. Es gibt grundlegend zwei Bauformen für Festplatten:
- 3,5 Zoll
- 2,5 Zoll
moderne Gehäuse bieten Slots für beide Bauformen oder es liegen Adapter bei. Zur Not kann man sich auch einen Adapter für wenige Euro bei Amazon kaufen. Ich hab hier eine 3,5 Zoll HDD an der ich den Einbau zeigen werde.
Neben der Bauform gibt es auch zwei verschiedene Arten von Anschlüssen (SSDs kennen noch U.2 und M.2 die komplett anders arbeiten):
- SATA (der Nachfolger von IDE)
- SAS (der Nachfolger von SCSI)
Der Vorteil von SAS Anschlüssen ist, dass man dort auch SATA-Festplatten anschließen kann. SAS an SATA geht nicht. Der Nachteil von SAS ist, dass man speziellere Kabel oder Adapter braucht, weil der Anschluss der SAS Festplatte für das einfache Einstecken über Rahmen in die Front von Servern optimiert wurde. Bei normalen PCs braucht man zumeist so einen Adapter, um die Festplatte per SATA-Kabel anschließen zu
können.
SATA
SAS
Der benötigte SAS-Adapter
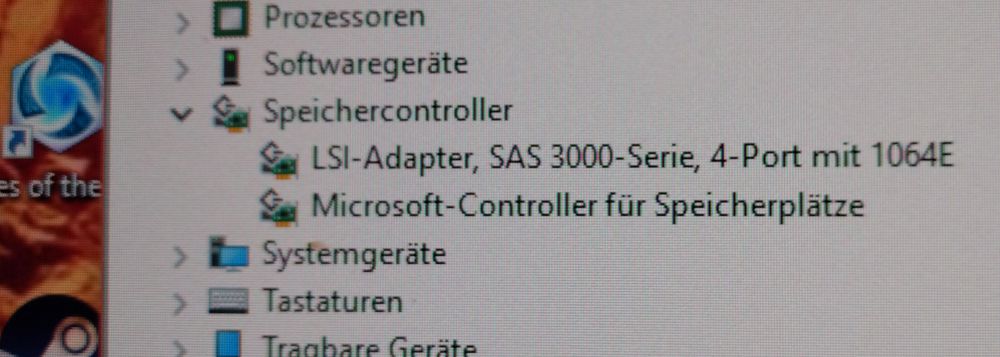
Oft sehen die SATA- und SAS-Anschlüsse komplett gleich aus und haben nur unterschiedliche Farben. Da hilft nur die Beschriftung auf dem Mainboard. Viele Boards haben aber nur SATA-Anschlüsse. Ob man überhaupt SAS-Anschlüsse hat verrät einen ein Blick in den Gerätemanager von Windows.
Wenn dort ein SAS-Hostadapter aufgeführt ist hat man welche sonst muss man sich keine Gedanken machen, kann aber auch nur SATA-Festplatten verbauen.
Ich bin günstig an eine SAS-Festplatte gekommen und habe mir einen entsprechenden Adapter gekauft. Nun kommt der schwierigste Teil für den man viel Geduld und oft auch etwas mehr Zeit braucht. Das SATA-Kabel durch den Wulst vorhandener Kabel und dem Festplattenkäfig, der sowie so immer dabei im Weg ist, egal welches Gehäuse man hat, in den Anschluss des Mainboard zu stecken. Ruhig bleiben und eine zusätzliche Lichtquelle helfen hier weiter.
Festplatten kann man meist mit Hilfe eines Rahmens oder Schienen direkt in den Slot stecken und braucht keine Schrauben mehr.
SATA-Kabel an den Adapter. Dann das Stromkabel ranstecken und den Adapter an die Festplatte stecken. Fertig!
die neue 2TB HDD über der alten 1TB HDD
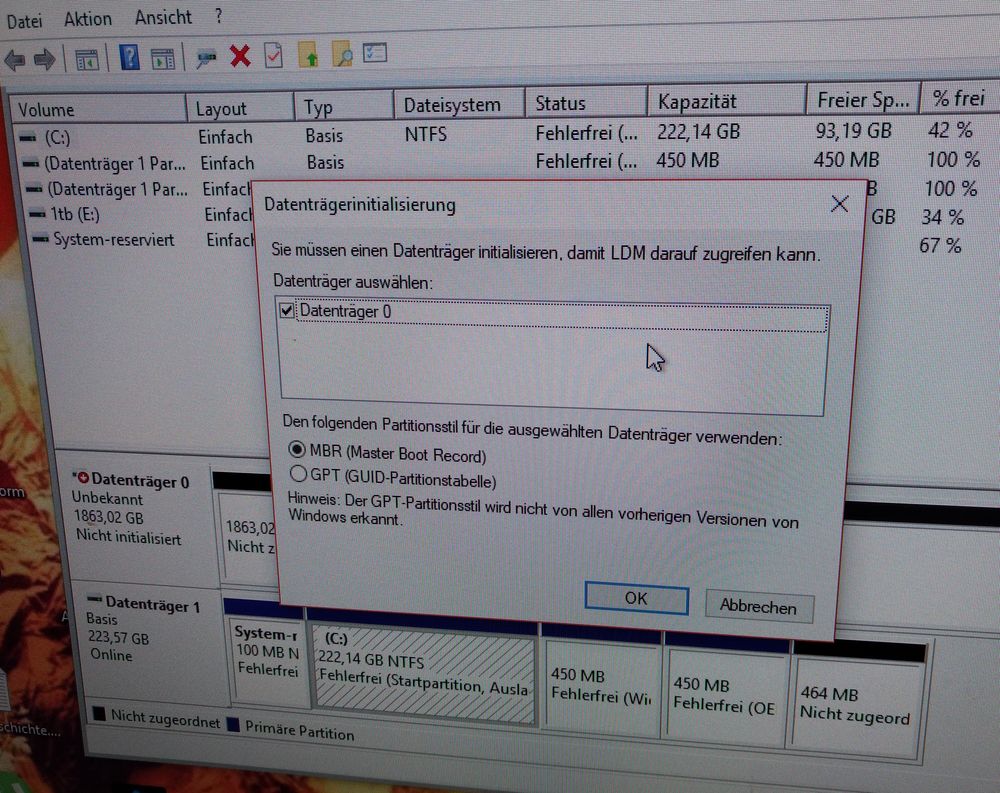
Nun den PC einschalten und Windows starten. Entweder wird die Festplatte schon angezeigt oder man muss über die Datenträgerverwaltung noch ein Volume einrichten (einfaches Volumen.. RAIDs sind komplizierter...).
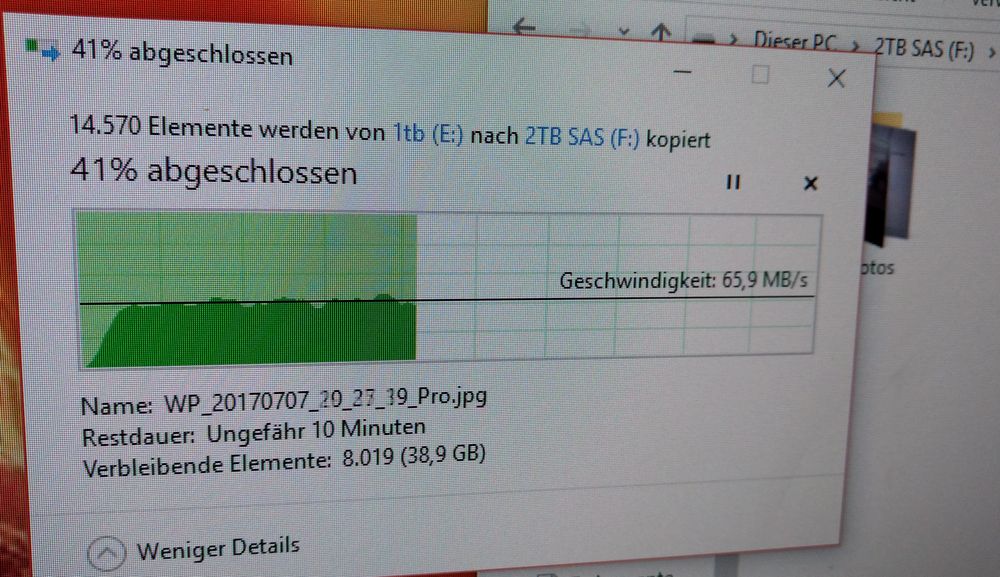
Nun ist die Festplatte da und man dann anfangen Daten zu kopieren.
Die Daten von der alten Festplatte sollte man immer noch etwas dort behalten, falls die Festplatte doch Zicken machen sollte, dann muss man nicht aufwendig das Backup raus suchen, sondern hat die Daten direkt noch. Ich geh immer davon aus, dass wenn eine Komponente 2 Wochen fehlerfrei lief, dass man erst einmal davon ausgehen kann, dass kein Hardware-Defekt vorliegen kann und wenn dann was kaputt geht, es nicht vorhersagbar war.
Meine meisten Email-Adressen sind ja nur Weiterleitungen. Beim Umzug meiner Domains auf meinen Server habe ich auch erst einmal alle umgezogen, die keine Email-Adressen haben. Das waren ein paar, aber dann war ich schnell bei denen mit Email-Adressen.
Damit ich nun auch hier einen sehr weichen Umzug hinbekomme, waren nun alle dran, die nur Weiterleitungen hatten.
Weiterleitungen sind mit Postfix wirklich einfach umgesetzt. Die DNS Einträge hat Netcup bei mir immer gleich schon mit eingerichtet, so dass ich dort nichts weiter machen musste.
Zu erst muss natürlich Postfix instaliert werden.
sudo apt-get install postfix
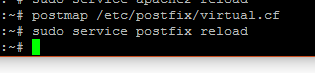
Danach einfach die Config-Datei von Postfix editieren. Die Datei findet man jeden Falls unter Ubuntu
hier:
Das King Pigeon RTU5023 ist ein Gerät zum Messen von Temperatur und Luftfeuchtigkeit. Der Vorteil ist, dass das Gerät diese Messungen dann auch über das Handy-Netz (Quad-Band) per SMS verschicken kann. Mit dem sehr stabilen Gehäuse und dem Anschluss für den Senor kann man damit also ohne Probleme Transporte mit LKWs oder Zügen von einem Standort aus überwachen. Mit einer SMS-Flat entstehen auch kaum zusätzliche Kosten. Die SIM-Karte darf keinen PIN haben, da man an dem Gerät keine PIN eingeben kann und die Programmierung rein über Commands erfolgt, die man dem Gerät per SMS schickt. Antworten tut das Gerät auch über SMS.
Ich habe das Gerät von der Switch GmbH bekommen, um mal heraus zu finden wie es funktioniert und wie man es in vorhandene Systeme integrieren kann.
Das Problem ist, erst einmal etwas über das Gerät heraus zu finden. Bei chinesischen Geräten ist das ja immer das Problem, dass man zwar viele Seiten findet wo man das Gerät kaufen kann, aber kaum Seiten vom Hersteller oder mit Anleitungen. Das ist auch hier so. Die Infos zu den SMS Commands ist schwer zu finden und auch nicht gerade übersichtlich oder gut erklärt.
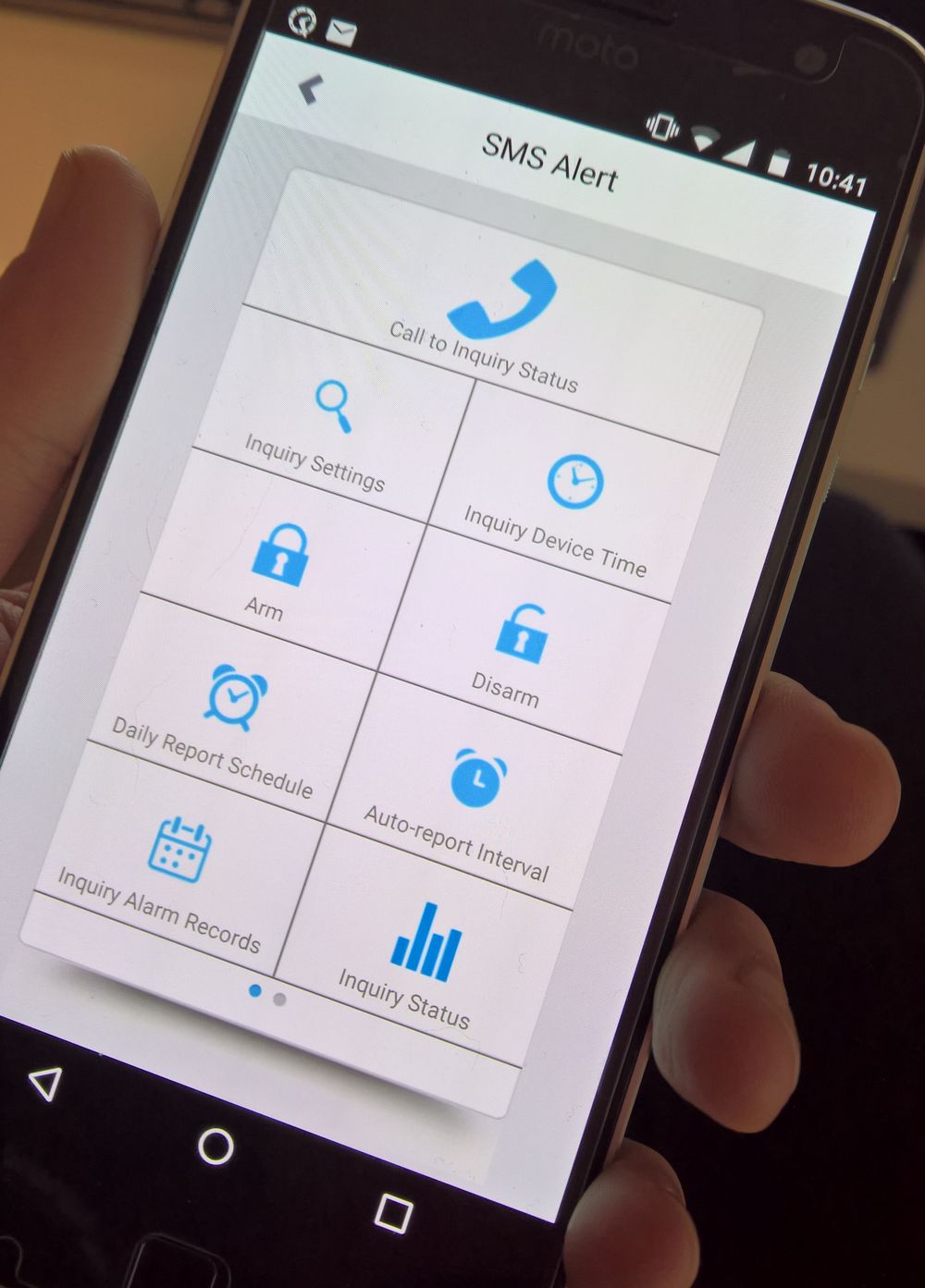
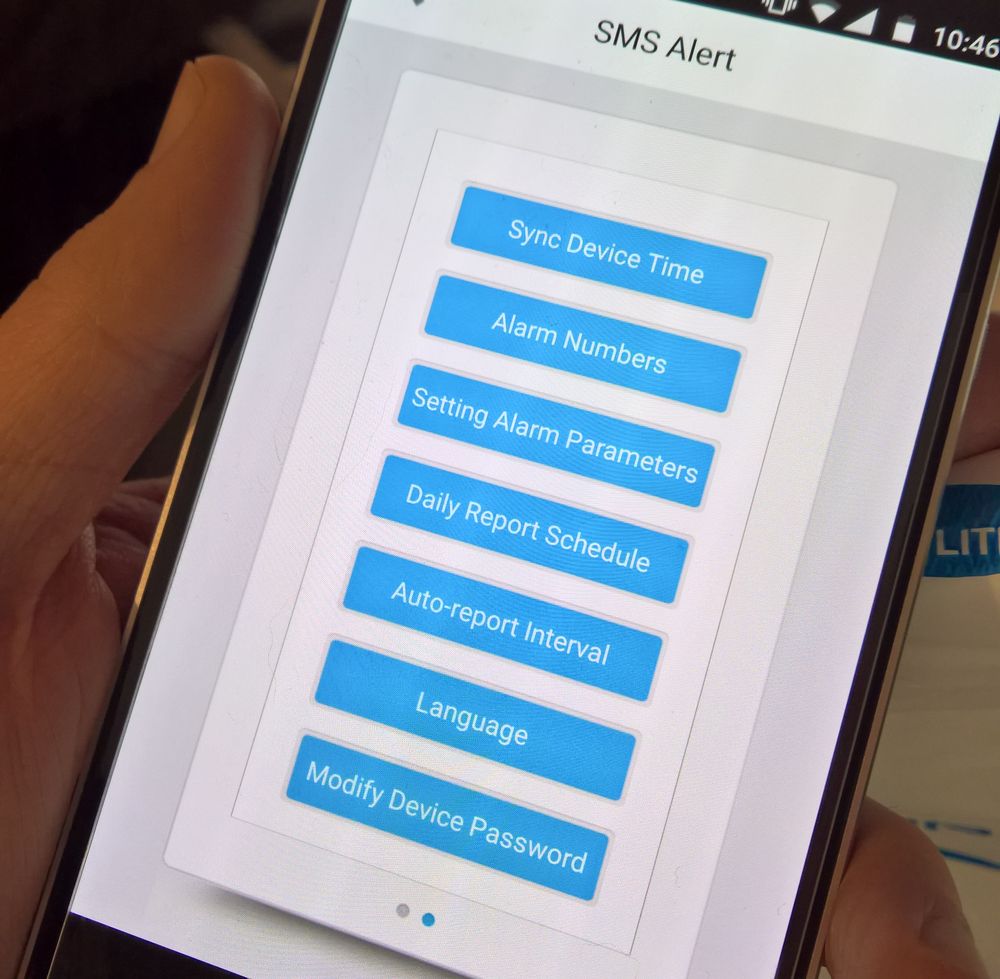
ABER es gibt einen Vorteil und dieser ist die Android-App im Google Play-Store. Diese macht an sich nichts andere als Eingaben in die App per SMS zu verschicken. Antworten kommen per SMS und werden dort wieder eingetragen.
Also einfach das Gerät anschließen und die App installieren. Als erstes muss man das Gerät anmelden. Nummer eingeben, das default Passwort ist 1234 und den Rest nach belieben ausfüllen und speichern.
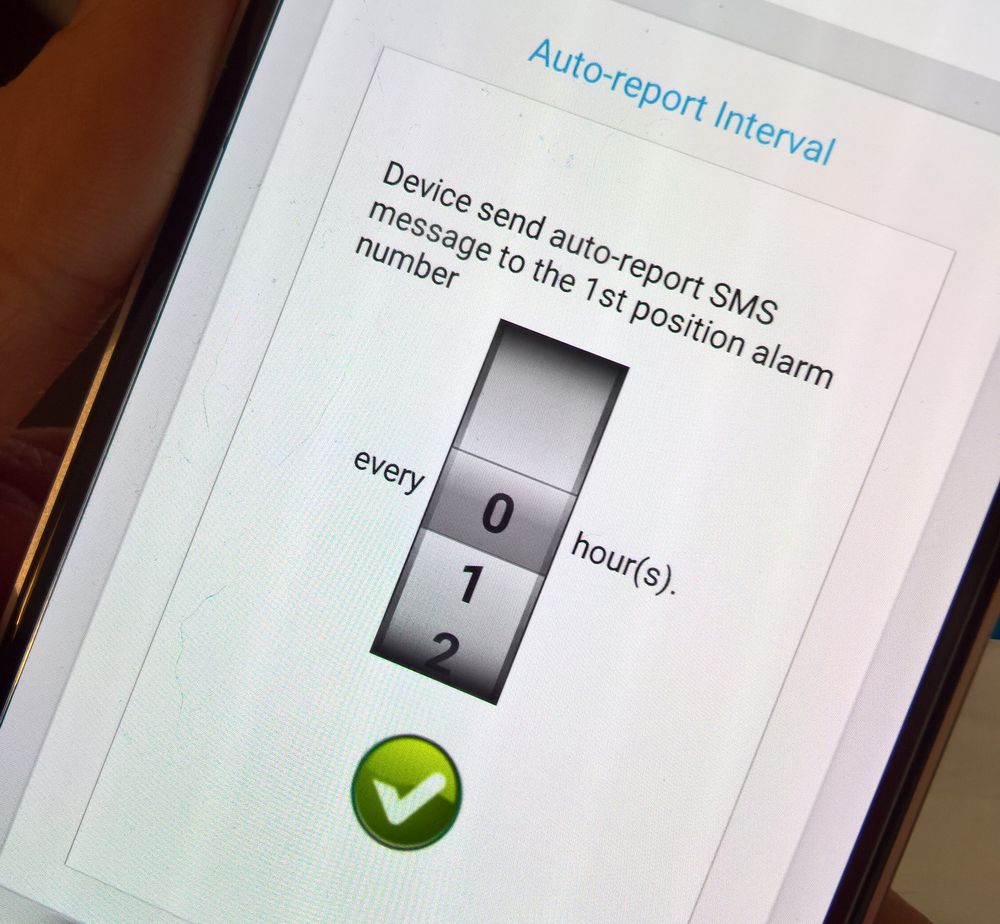
Ich wurde erst einmal mit SMS voll gespamt. Meistens dass die Report-Time auf 999 stehen würde. Also diese erst einmal auf 1h gestellt und schon hörte es auf. Man kann sich stündlich Reports der Messungen zusenden lassen oder Alarm SMS, falls die Tempartur- oder Luftfeuchtigkeit-Range über oder unter schritten wird.
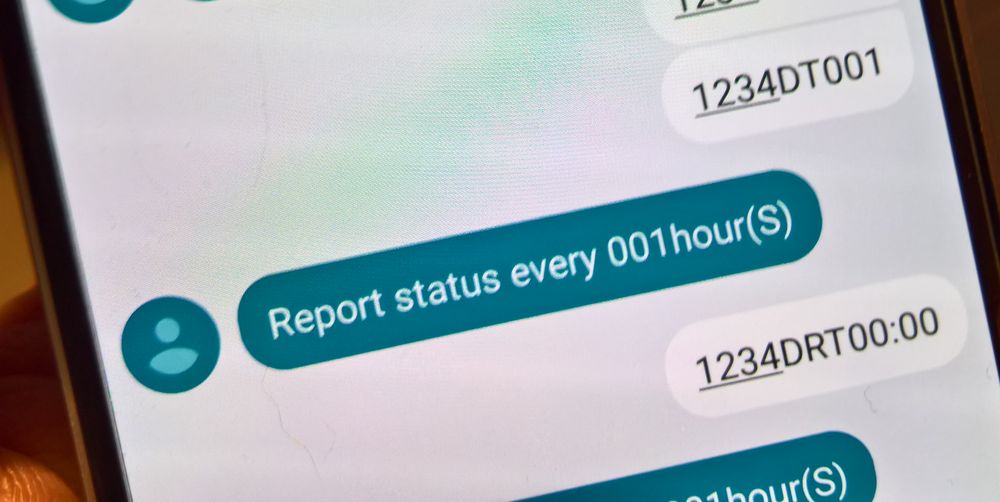
Das Tolle ist, dass die SMS natürlich auch einfach im Handy vorliegen. Da kann man dann anhand der Zuordnungen von Befehl und Antwort sich die meistens Commands einfach so erarbeiten.
1234DT001
Das setzt die Report-Time auf 1h.
Als nächstes geht es nun darum SMS zu empfangen und deren Inhalt auszuwerten. Davon ist wohl das Empfangen das Problem, wobei ich noch einen UMTS-Stick rumliegen habe und es da wohl entsprechende Java-Libs gibt.
Damit kann man sich dann ein SMS-Gate bauen und die eingehenden SMS parsen und weiterleiten. Aber das kommt dann nächste Woche.
Ich bin jetzt auch mit MP4toGIF.com auf meinen Server bei netcup umgezogen. Einer der Hauptgründe von dem Hostingpacket von 1&1 auf einen eigenen Server umzuziehen war neben den günstigeren Betriebskosten für Server und Domains auch die Möglichkeit SSL-Zertifikate von Let's Encrypt verwenden zu können. Also keine 2,99 mehr pro Domain, um https nutzen zu können.
Let's Encrypt ist auch sehr einfach zu verwenden. Hier ist eine Anleitung für Ubuntu 16.04 LTS.
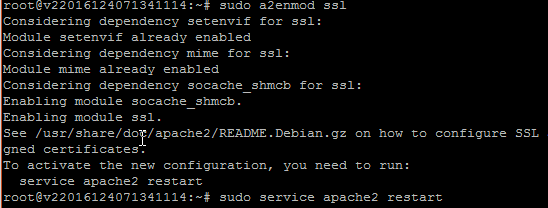
Zu erst, um nicht erst in kryptische Fehler zu laufen, aktivieren wir SSL für den Apache.
Dann startet der Client und man muss den Anweisungen folgen. Bei mir brach er mitten drin ab weil 'sudo apache2ctl configtest'
einen Fehler meldete, der wohl auf das bei mir noch nicht aktive SSL-Module zurück zu führen war.
ABER es ist sehr einfach den Rest per Hand einzurichten.
Zuerst die conf-Datei in sites-available mit dem Zusatz "-ssl" doppeln. Also zum Beispiel mp4togif.conf in mp4togif-ssl.conf doppel.
Dann in der neuen Datei den Port von 80 auf 443 ändern und dies hier einfügen.
Include /etc/letsencrypt/options-ssl-apache.conf
SSLCertificateFile /etc/letsencrypt/live/mp4togif.com/cert.pem
SSLCertificateKeyFile /etc/letsencrypt/live/mp4togif.com/privkey.pem
SSLCertificateChainFile /etc/letsencrypt/live/mp4togif.com/fullchain.pem
Nun nur die site aktivieren mit
sudo a2ensite mp4togif-ssl
und den Apache neuladen
sudo service apache2 reload
und schon sind wir fertig und https sollte funktionieren.
Bevor es dann wirklich mal um die Installation von PDT in Eclipse geht, wollen wir uns erst einmal eine MySQL Datenbank einrichten, damit wir auch richtige kleine Anwendungen schreiben können und nur ganz selten kommt man da ohne Datenbank aus. Auch wenn NoSQL Datenbanken wie Neo4J wirklich toll und momentan sehr in sind, bleiben wir bei einem klassischen RDBMS. Weil MySQL gerade im Web sehr verbreitet ist und sich einfach lokal einrichten lässt, bleiben wir auch bei MySQL.
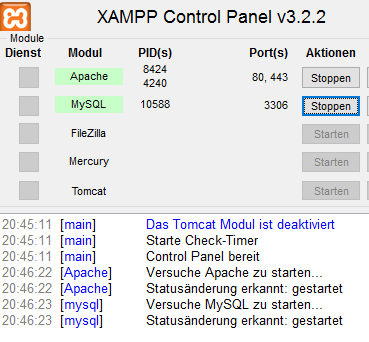
Wer ein Linux benutzt, kann MySQL immer ganz einfach über den Paket-Mananger installieren. Für Windows kann man schnell zu XAMPP greifen. XAMPP enthält alles vom Apache, PHP7 und MySQL bzw MariaDB.
XAMPP funktioniert am Besten wenn man es direkt unter C:\ installiert.
Zum Verwalten der Server-Anwendungen von XAMPP gibt es das XAMPP Control Panel. Hier müssen nur der Apache und der MySQL Server gestartet
werden.
Damit auf die Datenbank zugegriffen werden kann bringt XAMPP phpMyAdmin mit. phpMyAdmin ist eine Datenbankverwaltung die in PHP geschrieben ist und auch von den meisten Hostern angeboten wird.. wenn nicht sogar von allen. Man kann direkt über die URL http://localhost/phpmyadmin darauf zugreifen.
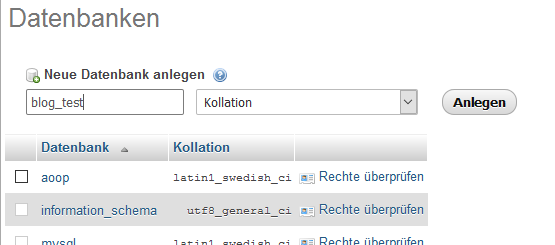
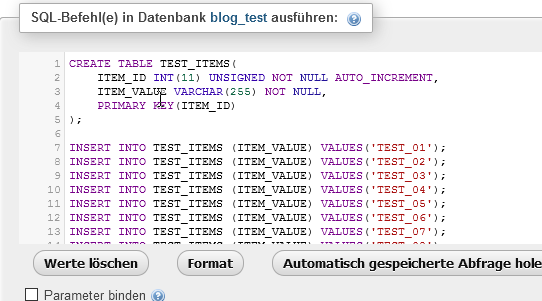
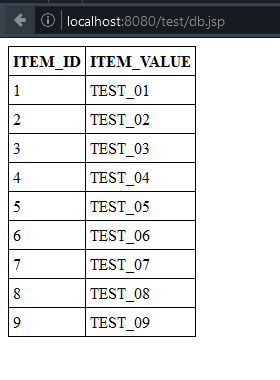
Zuerst erstellen wir eine Datenbank mit dem Namen blog_test.
Damit wir ein paar Daten haben, legen wir uns eine Tabelle mit ein paar wenigen Daten an. Hier ist das SQL-Script dafür:
CREATE TABLE TEST_ITEMS(
ITEM_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
ITEM_VALUE VARCHAR(255) NOT NULL,
PRIMARY KEY(ITEM_ID)
);
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_01');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_02');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_03');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_04');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_05');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_06');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_07');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_08');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_09');
Die IDs werden automatisch hochgezählt und müssen deswegen nicht extra angegeben werden.
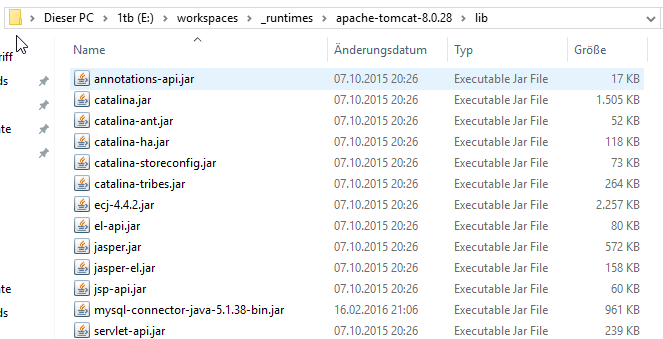
Nun gehen wir wieder in Eclipse zurück und erstellen uns eine kleine JSP mit einer Datenbankabfrage. Und hier wird es etwas komplizierter mit den verschiedenen ClassLoader des Tomcats und den verschiedenen Config-Dateien. Ich hab die einfachste aber nicht beste Variante gewählt. Die JAR-Datei mit dem JDBC-Treiber kommt direkt in das lib-Verzeichnis des Tomcat und wir passen die zentrale context.xml Datei, die uns von Eclipse zur Verfügung gestellt wird.
Die aktuelle JAR mit dem MySQL-Treiber findet man auf dev.mysql.com.
In die Context-Datei definierten wir die DataSource als Resource.
Nun können wir über JNDI uns diese DataSource in eine JSP holen. Wir erstellen eine ganz einfach Abfrage. Das Ergebnis liefert uns ein Statement in Form eines ResultSets. Ich benutzt hier die Methode über den Index die Ergebnisse zu bekommen, z.B. getString(1) wobei aber auch getString("ITEM_ID") funktioniert und für den zielgerichteten Einsatz sehr viel besser ist, weil man so das SQL-Statement ändern kann und auch die Reihenfolge der Columns ändern, ohne dabei auf den Java-Code achten zu müssen. Hier wird aber nicht zielgerichtet ein Wert ausgelesen und z.B. in ein anderes Object geschrieben sondern einfach alles ausgegeben. Deswegen auch nur getString() und keine anderen Methoden, die einen passenden Datentyp zurück liefern und ein eigenes Casten der Werte unnötig machen.
Der Vorteil die Connection über eine DataSource zu bekommen und nicht jedes mal selbst zu initiieren ist, dass die DataSource ein Pooling der Connections vornimmt und Datenbankverbindungen zur Wiederverwendung offen hält, um den Overhead für Verbindungsaufbauten zu verringern.
SQL-Abfragen direkt in einer JSP-Seite zu ist aber eine schlechte und man sollte so etwas in DAO-Klassen auslagern und in der JSP nur die Ansicht mit schon fertigen Objekten erstellen, die dann vom DAO geliefert werden.
Außerdem werden immer mehr JPA verwendet, wo die SQL-Statements automatisch erzeugt werden. Handgeschriebenes SQL ist in komplexen Fällen meistens schneller und besser, aber ORM-Frameworks erleichtern einen die Arbeit schon sehr und man sollte sich JPA auf jeden Fall einmal
ansehen, bevor man noch direkt mit JDBC und SQL arbeitet.
Im nächsten Teil geht es dann wirklich mit PHP weiter.
Bald ist wieder die Zeit der Bewerbungstest und -gespräche für Fachinformatiker AE(=Anwendungsentwicklung) Ausbildungsstellen oder man ist noch in der Schule und überlegt sich, ob man sich den Abi-Stress wirklich antun soll. In beiden Fällen hat man sich wohl schon einige Gedanken gemacht und wollte sich schon mal ein Bild davon machen wie Programmieren in de, Beruf aussieht. Privat zu entwickeln ist doch immer etwas anderes als anderes.
In den meisten Fällen wird man sich seinen Ausbildungsplatz nicht danach aussuchen, welche Programmiersprachen in der jeweiligen Firma verwendet werden. Man wird nehmen was man bekommt. Wenn man sich aber mal grob auf ein Gespräch vorbereiten will und man in eine neue Sprache hinein schnuppern möchte, muss man sich erst einmal eine Umgebung einrichten. Es gibt genug Tutorials dazu.. deswegen möchte ich in nichts nachstehen.
Ich musste damals mir auf die Schnelle alles einrichten um ein C-Programm unter Linux zu schreiben und zu compilieren. Mit Hilfe des Internets ging es auch ganz gut. Aber für C bringt Linux auch alles.
Ich zeige hier aber einfach mal, was man alles braucht, um mit Java, PHP und JavaScript ein kleines "Hello World" Programm zu schreiben. Wobei die Einrichtung der Umgebung im Vordergrund steht und nicht das kleine Programm.
Java (Teil 1) Java Umgebungen sind nicht immer das einfachste. Wenn man eine Webanwendung schreiben möchte, hat man schon relativ viel zu konfigurieren. Deswegen erst einmal ein kleine und einfache Anwendung.
Als erstes brauchen wir Java. Für die Entwicklung mit Java benutzt man am Besten das JDK (Java SE Development Kit). Es enthält zusätzliche Werkzeuge und den Source-Code zu den Java-Klassen. Außerdem wird keine komische Ask-Toolbar mit installiert. Das JRE ist mit dabei, so dass man mit dem JDK allein auskommt.
Die aktuelle Version der 8er Reihe findet man hier: Oracle Java 8 JDK
Man könnte jetzt theoretisch schon mit einem Text-Editor sein erstes Java-Programm schreiben und mit dem Java-Compiler compilieren. In einem Text-Editor zu schreiben ist aber alles andere als angenehm und man hat keine Syntax-Highlighting, Code-Vervollständigung oder automatische Anzeige von Fehlern. So eine Integrierte Entwicklungsumgebung (IDE) erleichtert einen schon sehr viel.
Die IDE meiner Wahl ist Eclipse. Man kann aber auch NetBeans oder IntelliJ verwenden. Das Grundprinzip ist bei allen gleich. Aber hier nehmen wir Eclipse.
Hier findet man den Download von Eclpise J2EE. Die J2EE-Version, weil da alles mit dabei ist, was man so braucht. Auch alles was man braucht, um ein einfaches Web-Project mit einem Tomcat zu realisieren.
Bei Eclipse einfach die Zip-Datei downloaden und entpacken. Beim ersten Start wird ein Workspace angelegt. Der Workspace ist ein Verzeichnis in dem die Projekte abgelegt werden.
Man kann beliebig viele Workspaces haben und auch mehrere Eclipse Instanzen mit verschiedenen Workspaces gleichzeitig geöffnet haben.
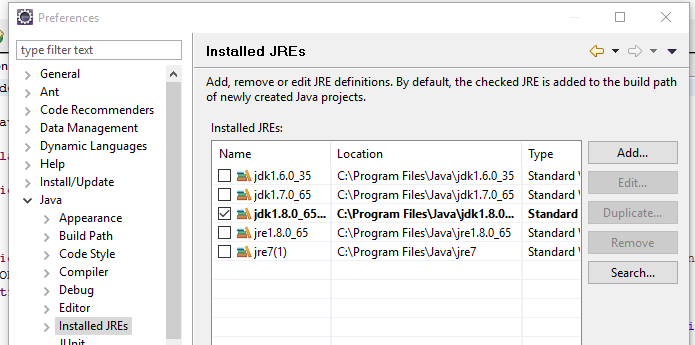
Sollte man schonvorher eine Java-Version installtiert gehabt haben, sollte man nun das neu installierte JDK auswählen. Dazu geht man im Menu in den Menüpunkt.
Window -- Preferences -- Java -- Installed JREs
Dort mit Hilfe der Search... Funktion nach dem neuen JDK suchen lassen. Wenn es gefunden wurde dieses mit dem Hacken vorne als default JRE definieren. Dann wird es automatisch für jedes Projekt verwendet, dass keine eigenen Einstellungen für JRE-Libs hat. Aber das ist jetzt erst einmal nicht so wichtig. Für uns ist nur wichtig, dass unser neues Project das JDK verwendet.
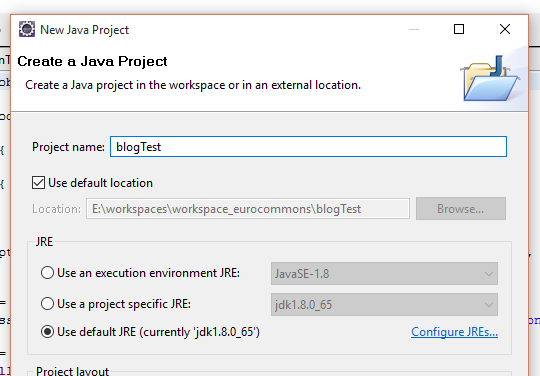
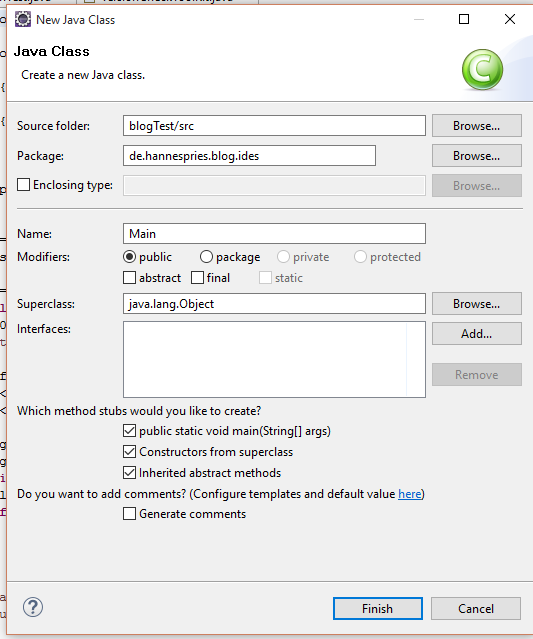
Wenn wir unser JDK eingebunden haben können wir nun unser Project erstellen.
Wir geben dem Project einen Namen. Hier kann man auch gleich sehen, ob unser JDK die default JRE ist. Hier könnten wir auch ein abweichendes JRE auswählen.
Weitere Einstellungen nehmen wir nicht vor und klicken einfach auf finish.
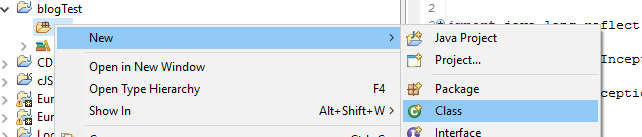
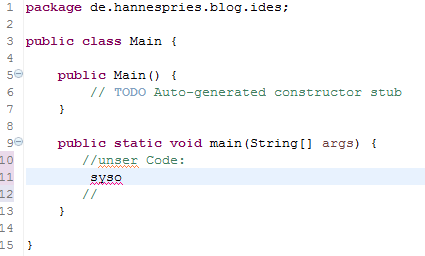
Das Project wird angelegt und wir legen uns unsere Klasse an, die unser Haupt-Programm enthalten wird. Die Klasse ist Main und wird im Package de.hannespries.blog.ides liegen. Packages sind so etwas wie Verzeichnisse, um die Klassen zu strukturieren, aber auch nur ähnlich, weil ein Package über mehrere JAR-Dateien verteilt sein können.
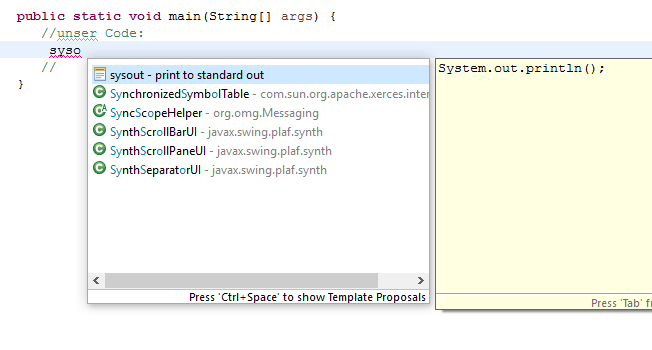
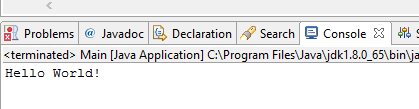
In die Main Methode kommt unser Code. Da wir schreibfaul sind und jetzt eine tolle IDE haben geben wir nur syso ein
jetzt drücken wir Strg+Space und nutzen unser syso zu einem System.out.println() zumachen. Das geht so sehr viel schneller als wenn man alles per Hand schreiben würde, wie man es in einem Text-Editor machen müsste.
package de.hannespries.blog.ides;
public class Main {
public Main() {
// TODO Auto-generated constructor stub
}
Nun wollen wir den Code einmal testen. Erst einmal Speichern. Dann öffnen wir mit einem Rechtsclick das Context-Menü, wählen Run as und dann Java-Application.
Damit wir immer die Console direkt anzeigt bekommen, wenn eine Ausgabe kommt, selbst, wenn wir einen anderen Tab gerade offenen hatten, nehmen wir noch folgende Einstellung vor.
Wenn man das Programm dann mal mit anderen Teilen möchten, kann man über die Export-Funktion eine JAR-Datei erstellen. Wichtig dabei ist, dass man die main-Methode der entsprechenden Klasse auswählt, damit das Programm direkt gestartet werden kann. Die Manifest-Datei ist aber sehr komplex und ist an sich einen eigenen Artikel wert.
Damit haben wir Java und Eclipse installiert. Der Test lief auch. Im nächsten Teil werden wir dieser Installation einen Tomcat hinzufügen und unsere erste kleine JSP-Seite erstellen und im Browser anzeigen lassen.
Eine der Stärken bei Java sind die Threads und die ExecutorServices, die die Workloads auf einen festen Pool von Threads verteilen und dann die Ergebnisse Sammeln (Future<...>). Man kann natürlich auch alles in einer großen Schleife erledigen. Bei JavaScript hat man aber das Problem, dass nicht stoppende Scripte sehr schnell gestoppt werden. Das mit Timeouts zu lösen scheitert ganz schnell wenn einzelne Workloads zu lange dauern. Aus diesem Grund wurden die WebWorker entwickelt, die es erlauben nebenläufige Vorgänge in JavaScript zu realisieren und somit auch diese Probleme mit Timeouts von Scripts zu umgehen.
WebWorker und das Hauptscript kommunizieren dabei über Nachrichten, die hin und her geschickt werden. WebWorker können dabei entweder die ganze Zeit existieren oder man kann diese auch direkt nach dem erledigen der Aufgabe wieder beenden. In den meisten Fällen ist
dieses Verhalten wohl das Beste.
Man kann z.B. auch in einem Spiel AI-Gegner mit WebWorkern realisieren. Dann muss der WebWorker natürlich nach dem Starten so lange existieren bis er von außen die Nachricht erhält sich zu beenden.
Man schreibt einen WebWorker, der gegen einen zweiten antritt und versucht möglichst viel Fläche des Spielfeldes mit seiner Farbe zu markieren. Die Kommunikation ist sehr einfach. Der WebWorker gibt über postMessage() in einen JavaScript-Object eine Direction an das Hauptscript zurück und bekommt im nächsten Schritt das Ergebnis ob der letzte Schritt funktioniert hat. Anhang dieses Ergebnisses muss der WebWorker seinen nächsten Schritt planen. Der eigentliche WebWorker ist in der onmessage-Function gekapselt.
Also schickt das Hauptscript eine Message, onmessage des Workers reagiert und darin wird mit postMessage ein Ergebnis zurück geschickt.
Das ist die Struktur nach der WebWorker funktionieren.
Die Kommunikation hat natürlich Grenzen. Ein Element aus dem DOM an einen WebWorker zu über geben und dann dort zu ändern funktioniert (wie man wohl schon erwartet hat) nicht. Wenn man mit einem Canvas etwas machen will muss man die getImageData() Methode bemühen.
Wenn man mit einem WebWorker arbeitet hat man oft den Wunsch auch hier mit Scripten aus externen JS-Files zu arbeiten. Die klassische Variante mit den <script>-Tags funktioniert hier natürlich nicht. Dafür gibt es die importScripts-Function. Der Pfad ist relativ zur Datei des
WebWorkers anzugeben.
Beispiel:
importScripts('../lib/libwebp-0.1.3.demin.js');
Anstelle von onmessage direkt im Script kann man die Haupt-Function auch natürlich über addEventListener setzen, was sehr viel sauberer
aussieht.
Es sollte sowie so beim WebWorker immer "self" verwendet werden.
Die an den WebWorker übermittelten Daten erhält man ganz klassisch über das Event.
var data=event.data;
Was in den Daten drin steht hat man ja selbst bestimmt.
Am Ende der Haupt-Function wird dann das Ergebnis zurück geschickt und wenn gewünscht der WebWorker von sich heraus auch beendet. Der WebWorker kann auch von außen beendet werden, aber es ist wohl sicherer, wenn er sich selbst schließt.
So. Nachdem wir nun wissen wie der WebWorder intern funktioniert, bleibt am Ende eigentlich nur noch die Frage, wie man nun so einen WebWorker aus dem Haupt-Script heraus startet und wie man die Ergebnisse entgegen nehmen kann. Das ist aber an sich nicht wirklich kompliziert und da alles ja auch Event-Listener und Events setzt, ist nicht schwer zu erraten wie zurück geschickt Messages verarbeitet werden können.
function func(controller){
return function(event){
controller.doSomeThing(event.data);
};
};
var worker = new Worker('./controllers/webpWorker.js');
worker.addEventListener('message', func(this), false);
worker.postMessage(post);
Das Closure der Funktion ist noch das komplexeste hier dran. Der Code hier wird in einer Methode des Controllers ausgeführt und um die Verarbeitung des Ergebnisses in einer anderen Methode des Controllers durch zu führen muss eben der Controller der Function mit einem Binding an das WebWorker-Object im Hauptscript bekannt sein. Closures sind sehr wichtig und ohne diese JavaScript zu schreiben ist extrem umständlich und depremierent. Also wenn das Konzept noch nicht kennt, sich das als erstes erst einmal ansehen!
Die in "post" übergeben Daten findet man im Event im WebWorker unter event.data wieder.
Das hier war jetzt doch relativ kurz gehalten, aber zeigt hoffentlich die Hauptstrukturen sehr gut und reicht für erste Experimente.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von 



 Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: