 bezahlt von
bezahlt von IDE Einrichten für Einsteiger - Teil 3 - eine Datenbank hinzufügen
Bevor es dann wirklich mal um die Installation von PDT in Eclipse geht, wollen wir uns erst einmal eine MySQL Datenbank einrichten, damit wir auch richtige kleine Anwendungen schreiben können und nur ganz selten kommt man da ohne Datenbank aus. Auch wenn NoSQL Datenbanken wie Neo4J wirklich toll und momentan sehr in sind, bleiben wir bei einem klassischen RDBMS. Weil MySQL gerade im Web sehr verbreitet ist und sich einfach lokal einrichten lässt, bleiben wir auch bei MySQL.
Wer ein Linux benutzt, kann MySQL immer ganz einfach über den Paket-Mananger installieren. Für Windows kann man schnell zu XAMPP greifen. XAMPP enthält alles vom Apache, PHP7 und MySQL bzw MariaDB.
XAMPP funktioniert am Besten wenn man es direkt unter C:\ installiert.

Zum Verwalten der Server-Anwendungen von XAMPP gibt es das XAMPP Control Panel. Hier müssen nur der Apache und der MySQL Server gestartet
werden.
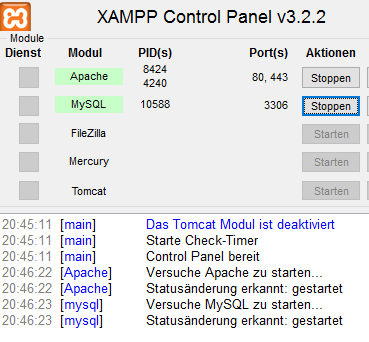
Damit auf die Datenbank zugegriffen werden kann bringt XAMPP phpMyAdmin mit. phpMyAdmin ist eine Datenbankverwaltung die in PHP geschrieben ist und auch von den meisten Hostern angeboten wird.. wenn nicht sogar von allen. Man kann direkt über die URL http://localhost/phpmyadmin darauf zugreifen.
Zuerst erstellen wir eine Datenbank mit dem Namen blog_test.
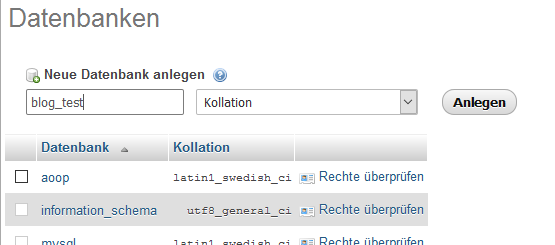
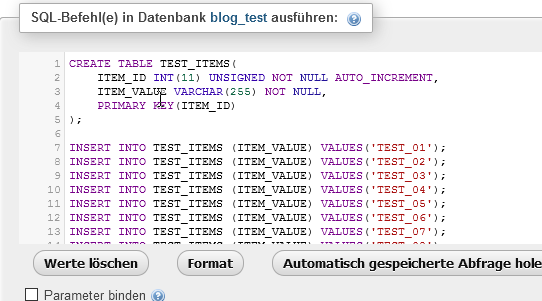
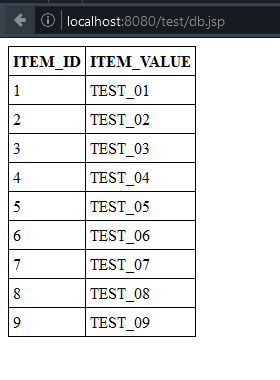
Damit wir ein paar Daten haben, legen wir uns eine Tabelle mit ein paar wenigen Daten an. Hier ist das SQL-Script dafür:
CREATE TABLE TEST_ITEMS(
ITEM_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
ITEM_VALUE VARCHAR(255) NOT NULL,
PRIMARY KEY(ITEM_ID)
);
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_01');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_02');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_03');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_04');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_05');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_06');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_07');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_08');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_09');
Die IDs werden automatisch hochgezählt und müssen deswegen nicht extra angegeben werden.
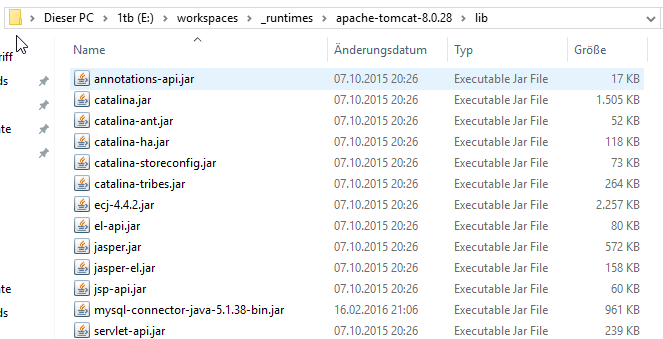
Nun gehen wir wieder in Eclipse zurück und erstellen uns eine kleine JSP mit einer Datenbankabfrage. Und hier wird es etwas komplizierter mit den verschiedenen ClassLoader des Tomcats und den verschiedenen Config-Dateien. Ich hab die einfachste aber nicht beste Variante gewählt. Die JAR-Datei mit dem JDBC-Treiber kommt direkt in das lib-Verzeichnis des Tomcat und wir passen die zentrale context.xml Datei, die uns von Eclipse zur Verfügung gestellt wird.
Die aktuelle JAR mit dem MySQL-Treiber findet man auf dev.mysql.com.
In die Context-Datei definierten wir die DataSource als Resource.
<Resource name="jdbc/TestDB" auth="Container" type="javax.sql.DataSource"
maxTotal="100" maxIdle="30" maxWaitMillis="10000"
username="root" password="" driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/blog_test"/>
Und in der web.xml die im WEB-INF Verzeichnis des Content-Bereich des Projekts liegt, referenzieren wir diese Resource.
<resource-ref>
<description>DB Connection</description>
<res-ref-name>jdbc/TestDB</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
Nun können wir über JNDI uns diese DataSource in eine JSP holen. Wir erstellen eine ganz einfach Abfrage. Das Ergebnis liefert uns ein Statement in Form eines ResultSets. Ich benutzt hier die Methode über den Index die Ergebnisse zu bekommen, z.B. getString(1) wobei aber auch getString("ITEM_ID") funktioniert und für den zielgerichteten Einsatz sehr viel besser ist, weil man so das SQL-Statement ändern kann und auch die Reihenfolge der Columns ändern, ohne dabei auf den Java-Code achten zu müssen. Hier wird aber nicht zielgerichtet ein Wert ausgelesen und z.B. in ein anderes Object geschrieben sondern einfach alles ausgegeben. Deswegen auch nur getString() und keine anderen Methoden, die einen passenden Datentyp zurück liefern und ein eigenes Casten der Werte unnötig machen.
<%@page import="java.sql.ResultSetMetaData"%>
<%@page import="java.sql.ResultSet"%>
<%@page import="java.sql.Statement"%>
<%@page import="java.sql.Connection"%>
<%@page import="javax.sql.DataSource"%>
<%@page import="javax.naming.InitialContext"%>
<%@page import="javax.naming.Context"%>
<html>
<head>
<title>Blog Test DB</title>
<style type="text/css">
table{
border-collapse:collapse;
}
td, th{
border:1px solid #000000;
padding:4px;
}
th{
font-weight:bold;
}
</style>
</head>
<body>
<table>
<%
try{
//get DataSource
Context ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup("java:/comp/env/jdbc/TestDB");
//prepare SQL
String sql="SELECT * FROM TEST_ITEMS";
//Query database
Connection conn=ds.getConnection();
Statement stmt=conn.createStatement();
ResultSet rset=stmt.executeQuery(sql);
ResultSetMetaData rsetM=rset.getMetaData();
//output
%>
<tr>
<%
for(int i=1; i<=rsetM.getColumnCount();i++){
%>
<th><%=rsetM.getColumnName(i) %></th>
<%
}
%>
</tr>
<%
while(rset.next()){
%>
<tr>
<%
for(int i=1; i<=rsetM.getColumnCount();i++){
%>
<td><%=rset.getString(i) %></td>
<%
}
%>
</tr>
<%
}
//close all resources
rset.close();
stmt.close();
conn.close();
}
catch(Exception e){
e.printStackTrace();
}
%>
</table>
</body>
</html>
Der Vorteil die Connection über eine DataSource zu bekommen und nicht jedes mal selbst zu initiieren ist, dass die DataSource ein Pooling der Connections vornimmt und Datenbankverbindungen zur Wiederverwendung offen hält, um den Overhead für Verbindungsaufbauten zu verringern.
SQL-Abfragen direkt in einer JSP-Seite zu ist aber eine schlechte und man sollte so etwas in DAO-Klassen auslagern und in der JSP nur die Ansicht mit schon fertigen Objekten erstellen, die dann vom DAO geliefert werden.
Außerdem werden immer mehr JPA verwendet, wo die SQL-Statements automatisch erzeugt werden. Handgeschriebenes SQL ist in komplexen Fällen meistens schneller und besser, aber ORM-Frameworks erleichtern einen die Arbeit schon sehr und man sollte sich JPA auf jeden Fall einmal
ansehen, bevor man noch direkt mit JDBC und SQL arbeitet.
Im nächsten Teil geht es dann wirklich mit PHP weiter.
Wer ein Linux benutzt, kann MySQL immer ganz einfach über den Paket-Mananger installieren. Für Windows kann man schnell zu XAMPP greifen. XAMPP enthält alles vom Apache, PHP7 und MySQL bzw MariaDB.
XAMPP funktioniert am Besten wenn man es direkt unter C:\ installiert.
Zum Verwalten der Server-Anwendungen von XAMPP gibt es das XAMPP Control Panel. Hier müssen nur der Apache und der MySQL Server gestartet
werden.
Damit auf die Datenbank zugegriffen werden kann bringt XAMPP phpMyAdmin mit. phpMyAdmin ist eine Datenbankverwaltung die in PHP geschrieben ist und auch von den meisten Hostern angeboten wird.. wenn nicht sogar von allen. Man kann direkt über die URL http://localhost/phpmyadmin darauf zugreifen.
Zuerst erstellen wir eine Datenbank mit dem Namen blog_test.
Damit wir ein paar Daten haben, legen wir uns eine Tabelle mit ein paar wenigen Daten an. Hier ist das SQL-Script dafür:
CREATE TABLE TEST_ITEMS(
ITEM_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
ITEM_VALUE VARCHAR(255) NOT NULL,
PRIMARY KEY(ITEM_ID)
);
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_01');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_02');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_03');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_04');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_05');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_06');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_07');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_08');
INSERT INTO TEST_ITEMS (ITEM_VALUE) VALUES('TEST_09');
Die IDs werden automatisch hochgezählt und müssen deswegen nicht extra angegeben werden.
Nun gehen wir wieder in Eclipse zurück und erstellen uns eine kleine JSP mit einer Datenbankabfrage. Und hier wird es etwas komplizierter mit den verschiedenen ClassLoader des Tomcats und den verschiedenen Config-Dateien. Ich hab die einfachste aber nicht beste Variante gewählt. Die JAR-Datei mit dem JDBC-Treiber kommt direkt in das lib-Verzeichnis des Tomcat und wir passen die zentrale context.xml Datei, die uns von Eclipse zur Verfügung gestellt wird.
Die aktuelle JAR mit dem MySQL-Treiber findet man auf dev.mysql.com.
In die Context-Datei definierten wir die DataSource als Resource.
<Resource name="jdbc/TestDB" auth="Container" type="javax.sql.DataSource"
maxTotal="100" maxIdle="30" maxWaitMillis="10000"
username="root" password="" driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/blog_test"/>
Und in der web.xml die im WEB-INF Verzeichnis des Content-Bereich des Projekts liegt, referenzieren wir diese Resource.
<resource-ref>
<description>DB Connection</description>
<res-ref-name>jdbc/TestDB</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
Nun können wir über JNDI uns diese DataSource in eine JSP holen. Wir erstellen eine ganz einfach Abfrage. Das Ergebnis liefert uns ein Statement in Form eines ResultSets. Ich benutzt hier die Methode über den Index die Ergebnisse zu bekommen, z.B. getString(1) wobei aber auch getString("ITEM_ID") funktioniert und für den zielgerichteten Einsatz sehr viel besser ist, weil man so das SQL-Statement ändern kann und auch die Reihenfolge der Columns ändern, ohne dabei auf den Java-Code achten zu müssen. Hier wird aber nicht zielgerichtet ein Wert ausgelesen und z.B. in ein anderes Object geschrieben sondern einfach alles ausgegeben. Deswegen auch nur getString() und keine anderen Methoden, die einen passenden Datentyp zurück liefern und ein eigenes Casten der Werte unnötig machen.
<%@page import="java.sql.ResultSetMetaData"%>
<%@page import="java.sql.ResultSet"%>
<%@page import="java.sql.Statement"%>
<%@page import="java.sql.Connection"%>
<%@page import="javax.sql.DataSource"%>
<%@page import="javax.naming.InitialContext"%>
<%@page import="javax.naming.Context"%>
<html>
<head>
<title>Blog Test DB</title>
<style type="text/css">
table{
border-collapse:collapse;
}
td, th{
border:1px solid #000000;
padding:4px;
}
th{
font-weight:bold;
}
</style>
</head>
<body>
<table>
<%
try{
//get DataSource
Context ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup("java:/comp/env/jdbc/TestDB");
//prepare SQL
String sql="SELECT * FROM TEST_ITEMS";
//Query database
Connection conn=ds.getConnection();
Statement stmt=conn.createStatement();
ResultSet rset=stmt.executeQuery(sql);
ResultSetMetaData rsetM=rset.getMetaData();
//output
%>
<tr>
<%
for(int i=1; i<=rsetM.getColumnCount();i++){
%>
<th><%=rsetM.getColumnName(i) %></th>
<%
}
%>
</tr>
<%
while(rset.next()){
%>
<tr>
<%
for(int i=1; i<=rsetM.getColumnCount();i++){
%>
<td><%=rset.getString(i) %></td>
<%
}
%>
</tr>
<%
}
//close all resources
rset.close();
stmt.close();
conn.close();
}
catch(Exception e){
e.printStackTrace();
}
%>
</table>
</body>
</html>
Der Vorteil die Connection über eine DataSource zu bekommen und nicht jedes mal selbst zu initiieren ist, dass die DataSource ein Pooling der Connections vornimmt und Datenbankverbindungen zur Wiederverwendung offen hält, um den Overhead für Verbindungsaufbauten zu verringern.
SQL-Abfragen direkt in einer JSP-Seite zu ist aber eine schlechte und man sollte so etwas in DAO-Klassen auslagern und in der JSP nur die Ansicht mit schon fertigen Objekten erstellen, die dann vom DAO geliefert werden.
Außerdem werden immer mehr JPA verwendet, wo die SQL-Statements automatisch erzeugt werden. Handgeschriebenes SQL ist in komplexen Fällen meistens schneller und besser, aber ORM-Frameworks erleichtern einen die Arbeit schon sehr und man sollte sich JPA auf jeden Fall einmal
ansehen, bevor man noch direkt mit JDBC und SQL arbeitet.
Im nächsten Teil geht es dann wirklich mit PHP weiter.
| User | annonyme | 2016-05-10 21:46 |
anleitung, database, datasource, eclipse, einrichten, hannes pries, ide, jdbc, jsp, mysql, resultset, sql, tomcat, tutorial, xampp
 write comment:
write comment: