Als ich mit PHP anfing war es noch Alltag, dass man wenn eine Datenbank-Abfrage notwendig war diese auch einfach direkt an Ort und Stelle einbaute. Kapselung in einer eigenen Funktion oder Klasse war nicht wirklich verbreitet. Es wurde meistens direkt mit den entsprechenden Datenbank Funktionen gearbeitet und keine Abstraktion verwendet.
Nur in großen Anwendungen war es anders. Vorher hatte ich mit Java, JDBC und DataSources im Tomcat gearbeitet, wo es am Ende egal war welche Datenbank dahinter lief und man dies nur beim Anlegen der DataSource abgeben musste. Zuhause war ich auf Oracle Datenbanken und hatte nur so am Rande mit MySQL zu tun. Ich sollte ein Projekt von MySQL auf Oracle portieren und merkte schnell wie doof es war keine Abstraktion zu haben. Also nahm ich mir vor, sollte ich mal ein PHP anfangen, dass ich es besser machen würde. Genau so einfach wie mit einem Tomcat und den DataSources.
Dann kam in der Berufsschule das Thema Datenbanken, dass wir mit einer XAMPP-Installation bearbeiten sollten. Ein kleines Shop-"System". CRUD, eine Liste laden und wenn wir voll gut waren sogar Joins oder mal ein COUNT mit GROUP BY.. also alles was die meistens aus ihrem normalen Arbeitstag in und auswendig kannten. Ich wollte es dann auch gerne so schreiben, dass ich SQL über eine zentrale Klasse ausführen konnte und Schleifen einfach ausführen konnte und das Problem das bei Oracle ein Array so aussah [column]<()tr> und nicht wie bei MySQL <()tr>[column] direkt dort in der Implementierung ausgeglichen wurde und man so einfach zwischen den beiden Systemen switchen kontne ohne Code ändern zu müssen.
So entstand PDBC.
Aber fangen wir mal an. Zuerst erstellen wir uns eine einfache Datenbank Tabelle mit ein paar Daten. Diese werden dann im Verlaufe dieses Artikels mit PDBC aus der Datenbank laden und einmal ausgeben. Unsere Tabelle sieht wie folgt aus:
CREATE TABLE tests (
test_id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
test_name VARCHAR(255) NOT NULL,
PRIMARY KEY (test_id)
);
INSERT INTO tests(test_name) VALUES ('TEST_01');
INSERT INTO tests(test_name) VALUES ('TEST_02');
INSERT INTO tests(test_name) VALUES ('TEST_03');
INSERT INTO tests(test_name) VALUES ('TEST_04');
INSERT INTO tests(test_name) VALUES ('TEST_05');
Diese Tabelle repräsentiert Daten für eine einfache Klasse mit einer Id und einem Namen. Also das Grundmodel auf dem bestimmt fast 98% aller Entitäten basieren. Das normale vorgehen wäre jetzt diese Daten über ein einfaches SQL Query einzulesen. Dabei enthält man ein ResultSet oder Array mit allen Zeilen, die man dann in einer Schleife durchläuft. Während jedem Durchlauf erzeugt man ein neues Objekt der Klasse und befühlt dieses über die Setter mit den Daten aus dem Zeilen Array.
$result=array();
foreach($data as $row){
$obj=new Test();
$obj->setId($row["test_id"]);
$obj->setName($row["test_name"]);
$result[]=$obj;
}
Man muss viel per Hand schreiben, was sehr zeitintensiv, stupide und fehleranfällig ist. Wenn man an mehreren Stellen so lädt z.B. einmal laden eines Objekt anhand der Id, einmal die Liste und noch die Liste mit einem Pattern für den Namen, muss man alle Methoden und Funktionen wo man die Daten in das Objekt füllt ändern, wenn man mal eine Column der Datenbank hinzufügt, ändert oder entfernt.
Wenn man diesen Teil nun automatisiert, erleichtert einen das Leben schon sehr. Bei einer Klasse mit 10 Attributen sind es dann nicht mehr 12 Zeilen Code sondern nur noch 2. PDBC erledigt für einen diese Schritte. Vom erzeugen der Objekt, die Abfrage der Daten und dann das befüllen der Objekte.
Um nun zu wissen, welches Datenfeld aus der Datenbank in welches Klassen-Attribute gehört werden Annotationen genutzt. Es ist ganz leicht JPA und Hibernate beeinflusst. Wobei PDBC sehr viel weniger kann.
FKs werden nicht in Objekte abgebildet, also ein lazy oder eager Loading. Es werden nur wirklich Daten kopiert. Das SQL muss man komplett per Hand schreiben, was ich aber als Vorteil sehe, weil HQL/JPQL doch mich immer sehr eingeschränkt haben und viele wichtige SQL-Funktionen wie Nested-Queries und gute Joins oft nicht möglich waren. SQL bietet dort sehr viel mehr und performantere Möglichkeiten.
Aber hier geht es erst einmal um einfaches und schnelles Laden der Datensätze.
Dafür brauchen wir erst einmal unsere Klasse mit den entsprechenden Annotationen, die bestimmen zu welcher Column das Klassen-Attribute gehört. Das Schlüsselwort hierbei ist "@dbcolumn". Diese Annotationen werden mit Hilfe der Refelection Klassen von PHP und den DocComments gelesen und dann geparst.
Code-Auszug zum Lesen der Annotationen:
private function getColumnName($prop){
$result=null;
$doc=$prop->getDocComment();
if(preg_match("/@dbcolumn=[a-zA-Z0-9_]+/",$doc)){
$result=preg_replace("/^.+@dbcolumn=([a-zA-Z0-9_]+)\s.+$/Uis","$1",trim($doc));
}
return $result;
}
Damit man hier performant bleibt werden die Properties einmal pro Klasse eingelesen und in einer Map gespeichert, so was man schnell über den Column-Name zum Property gelangt. Wenn man dann für die nächste Klasse die Zuordnung braucht hat man diese schon. Da die Map static ist, geschieht das Einlesen auch nur einmal pro Request für eine Klasse.
private function loadProperties($ref){
if(isset(self::$cache[$ref->getName()])){
return self::$cache[$ref->getName()];
}
else{
$props=$ref->getProperties();
$map=array();
foreach($props as $prop){
$prop->setAccessible(true);
$map[$this->getColumnName($prop)]=$prop;
}
self::$cache[$ref->getName()]=$map;
return self::$cache[$ref->getName()];
}
}
setAccessible(true) ist hier sehr wichtig, weil wir so private Attribute lesen und schreiben können und dazu bringt es noch einem wirklich spürbaren Performance-Vorteil. Ja.. auch bei PHP. Bei Java gilt genau das Selbe. Die Reflection-Klassen von PHP sind von den Bezeichnungen und Methoden auch sehr an Java angelehnt und wer mit den Relfections in Java sich auskennt, kann sofort in PHP weiter machen, da die wichtigen Methodennamen wirklich zu 100% übereinstimmen.
Hier also unsere Test-Klasse:
class Test{
/**
* @dbcolumn=test_id
*/
private $id=0;
/**
* @dbcolumn=test_name
*/
private $name="";
public function __construct(){
}
public function getId(){
return $this->id;
}
public function setId($id){
$this->id=$id;
}
public function getName(){
return $this->name;
}
public function setName($name){
$this->name=$name;
}
}
Man sieht hier die Annotationen an den Attributen der Klasse. Die Werte werden direkt in die Attribute geschrieben. Die Nutzung der Getter und Setter ist hier nicht implementiert. Wobei das große Vorteile hätte da man so z.B. eine "1" aus der Datenbank auf ein "true" mappen könnte. Dafür werde ich mal eine Implementierung mit eignen Properties schreiben, die zusammen mit dem Property auch die Accessor-Methoden mitliefert, wenn diese vorhanden sind.
Jetzt geht es aber weiter mit dem konkreten Beispiel. Zuerst werden wir uns unsere Datenbank-Klasse holen. Dafür muss die Datenbankverbindung in der Config-Datei angegeben sein. Der Name muss eindeutig sein und mit dessen Hilfe wird die Datenquelle auch identifiziert. Die Bezeichnungen in der Config-Datei orientieren sich Oracle, so nennt sich ein Feld "SID", also Service-ID, das entspricht bei MySQL dem Datenbanknamen. Sollte hier der Standard-Port von MySQL verwendet werden, ist dieser normaler weise nicht anzugeben.
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="datasources.xsl"?>
<datasources>
<datasource name="ds_test" type="DBMySQLi">
<host>localhost</host>
<port>3306</port>
<sid>test</sid>
<username>root</username>
<userpassword>bitnami</userpassword>
</datasource>
</datasources>
Wir haben hier also unsere Datasource (wie im Tomcat) unter dem Namen "ds_test", die auch die lokale MySQL-Instanz und die Datenbank verweist. Wie man am Passwort schon vermuten kann, habe ich bei mir einfach den Bitnami WAMP-Stack verwendet, aber XAMPP oder eine vollständige Installation gehen natürlich genau so gut.
Wir müssen noch angeben wo die Config-Datei und wo die Datenbank-Klassen zu finden sind.
include_once("system/PDBC/PDBCDBFactory.php");
PDBCDBFactory::init("system/PDBC/dbclasses/","system/PDBC/conffiles/");
Wenn man PDBC in sein System integrieren will, kann man so die Config-Datei einfach mit im Config-Verzeichnis des Systems unterbringen.
Nun folgt ein kleines und einfaches SQL-Statement:
$sql="SELECT test_id,test_name FROM tests ORDER BY test_name ASC";
Und nun beginnt der spannende Teil, wir übergeben unser Datebank-Object, den SQL-String und den Klassennamen an den PDBCObjectMapper. Dieser nutzt das Interface der DB-Klasse, weswegen ihm egal ist welche Implementation verwendet wird. Dann wird die Klasse analysiert und deren Properties eingelesen und die passenden Spalten wie schon weiter oben beschrieben eingelesen. Der Rest ist eigentlich relativ primitiv. Erst wird eine Instanz der Klasse erzeugt und dann das Array mit dem Datensatz des Resultsets wir mit $key (Spaltenname) und $value (Wert aus der DB) durchlaufen.
Wird ein Property zu dem $key gefunden wird in dieses das $value geschrieben.
private function fillObject($row,$ref){
$obj=$ref->newInstance();
$props=$this->loadProperties($ref);
foreach($row as $key => $value){
if(isset($props[$key])){
$props[$key]->setValue($obj,$value);
}
}
return $obj;
}
public function queryList($db,$sql,$className){
$db->executeQuery($sql);
$ref=new ReflectionClass($className);
$result=array();
for($i=0;$i<$db->getCount();$i++){
$result[count($result)]=$this->fillObject($db->getRow($i),$ref);
}
return $result;
}
Die loadProperties-Methode habe ich ja weiter oben schon beschrieben. Hier wieder sich daran erinnern, dass wir setAccessible(true) für jedes Properties gesetzt haben und somit ohne Probleme in private-Properties schreiben können.
Im Aufruf sieht das ganze dann so aus:
$mapper=new PDBCObjectMapper();
$tests=$mapper->queryList($db, $sql, "Test");
"Test" ist unser Klassename, $sql unser String mit dem Query-Statement und $db unsere oben in der config-Datei definierten Datasource.
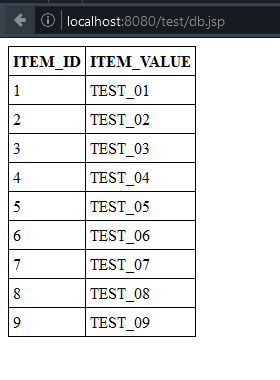
Als Rückgabe erhalten wir, wie alle schon sicher richtig vermutet haben, ein Array mit unseren gefüllten Test-Objekten. Um zusehen, dass alles richtig befüllt wurde, geben wir diese einfach mal aus.
foreach($tests as $test){
echo $test->getId()." - ".$test->getName()."<br>\n";
}
Der gesamte Code für unser kleines Test-Script sieht dann also so aus:
include_once("system/PDBC/PDBCDBFactory.php");
PDBCDBFactory::init("system/PDBC/dbclasses/","system/PDBC/conffiles/");
class Test{
/**
* @dbcolumn=test_id
*/
private $id=0;
/**
* @dbcolumn=test_name
*/
private $name="";
public function __construct(){
}
public function getId(){
return $this->id;
}
public function setId($id){
$this->id=$id;
}
public function getName(){
return $this->name;
}
public function setName($name){
$this->name=$name;
}
}
$db=PDBCCache::getInstance()->getDB("ds_test");
$sql="SELECT test_id,test_name FROM tests ORDER BY test_name ASC";
$mapper=new PDBCObjectMapper();
$tests=$mapper->queryList($db, $sql, "Test");
foreach($tests as $test){
echo $test->getId()." - ".$test->getName()."<br>\n";
}
Eine passende PDBC-Version ist hier zu finden.
Ich hoffe ich konnte einen kleinen Einblick geben, wie man sich die Arbeit mit Datenbanken in PHP einfacher machen kann und einen Teil der Konzepte aus der Java-Welt in PHP implementieren kann. Man kann natürlich noch sehr viel mehr implementieren und ein kompletes und komplexes ORM-System hier draus bauen, aber das würde hier zu weit führen und ich brauchte es auch so erst einmal nicht. Auch Inserts und Updates darüber zu realisieren und Getter und Setter benutzen zu können wäre toll und steht noch auf dem Plan, aber wohl alles erst im Laufe von 2016.
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: