In HTML gibt es die Möglichkeit Inputs auch außerhalb einer Form zu haben und diese mit einer Form zu verknüpfen. Dazu nutzt man das form-Attribute. Gerade im Checkout von Shopware 6 ist es echt praktisch. Beim DatePicker besteht aber das Problem, dass das Input, dass man selbst definiert durch ein neues Input-Feld ersetzt wird, wenn Flatpickr sich initialisiert. Diesem neuen Input muss man auch das form-Attribute geben.
Tut man es nicht, funktioniert z.B. das required-Flag am DatePicker nicht.
An sich geht es ganz einfach. In der Administration geht man auf Update, bestätigt alles, die Plugins werden deaktiviert (vielleicht auch das Language-Pack) und dann startet der Installer und .. läuft in einen Fehler und dann läuft garnichts mehr. Scheint jeden Falls öfters mal so zu passieren.
Ich hab mir ein Script gebastelt mit dem man sich eine Kopie des Shops auf die neue Version updaten kann und dann später auf diese Kopie switchen kann.
Man muss nicht alle Plugins deaktiveren, aber einfacher ist es. Also eine Kopie (Dateien und Datenbank) anlegen und da alles Plugins deaktiveren. Per SQL-Statement geht es recht schnell und einfach.
Der original Shop liegt in shop/ und der neue in shop65/. Die .env der Kopie (wegen DATABASE_URL) wird in shop_shared/ abgelegt und um LOCK_DSN="flock" und SHOPWARE_SKIP_WEBINSTALLER=1 ergänzen.
Dann das Script laufen lassen.. oder besser Zeile für Zeile per Hand ausführen.
cd ~/public_html/shop65 && composer update
cd ~/public_html/shop65 && bin/console system:update:finish
cd ~/public_html/shop65/vendor/shopware/administration/Resources/app/administration && npm install && cd ~/public_html/shop65
Ziel ist es wieder in die Administration zu kommen und dort alle Plugins zu aktualisieren. Wenn das gelungen ist, dann alle nach und nach wieder aktivieren und wieder die Themes in den SalesChannels einrichten.
Wenn Fehler auftreten immer mal wieder bin/console aufrufen, weil dann die Exceptions meistens ganz gut dargestellt wird.
So kommt man auch sehr gut ohne den Installer zu seinem aktuellen Shopware und räumt auch direkt noch etwas auf.
Wie man eine eigene Entity in die Suche integriert hatte ich schon erklärt. Was aber wenn man eine vorhandene Entity um weitere durchsuchbare Felder erweitern will? Das geht auch relativ einfach.
if (module?.manifest?.defaultSearchConfiguration) {
module.manifest.defaultSearchConfiguration = {
...module.manifest.defaultSearchConfiguration,
extensions: {
// In case some other plugin has already done this trick; we do not want to remove theirs.
...(module.manifest.defaultSearchConfiguration.extensions ?? {}),
// Add our extension fields to the omnisearch
customFields: {
customer_debitor_set_number: {
_searchable: true,
_score: searchRankingPoint.HIGH_SEARCH_RANKING,
},
}
},
};
}
Auch wenn dort die Felder hierarchisch angegeben werden, sind diese bei den Snippets flach strukturiert.
In einem Cart-Validator sollte man vermeiden vom Cat-Service die getCart()-Methode zu verwenden. Ich habe einen Service der mir für den Validator benötigte Daten lieferte und dabei auch einen Wert aus dem Cart generierte. getCart() triggert aber wieder den Validator.. Endlossschleife! Also am besten wirklich nur das in die Validator-Methode rein gereichte Cart-Object verwenden.
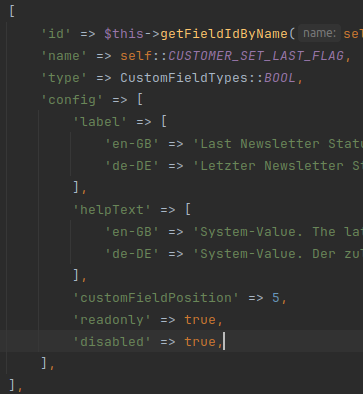
Es gibt manchmal CustomFields in denen man Daten wie externe Ids, ein Import- oder Export-Datum oder ein einfaches Bool-Flag speichern möchte. Der normale Admin-Benutzer darf diese Daten gerne sehen sollte sie aber nicht ändern, weil er oder sie nicht das nötige Wissen über die internen Abläufe des Plugins hat, um genau zu wissen, welche Auswirkungen so eine Änderung hat.
Deswegen ist es gut so ein CustomField readonly zu machen und am Besten komplett zu disablen. Das ist über die config des CustomFields sehr einfach möglich. In der Manifest einer App kann dass leider schon wieder ganz anders sein, weil dort sowas nicht vorgesehen ist.
Oft ist es sehr viel einfacher direkt etwas in die Suche der Administration einzugeben, als umständlich eine Seite zu öffnen und etwas aus der Liste per Hand oder Browser-Suche heraus zu suchen.
Eigene oder fehlende Entitäten dort zu integrieren ist an sich recht einfach und logisch. Es gibt hier eine Anleitung die aber leider so für mich nicht funktioniert hat, weil ein wichtiger Teil fehlte.
Routennamen sind hier erstmal nur Beispiel haft vergeben.
Step 1 Ich gehe davon aus das ein Plugin existiert mit einem JS-Module, das mindestens eine Route hat und dessen Name nach dem Schema {vendor}-{name} aufgebaut ist. Zum Module müssen wir wie beschrieben
einige wenige Dinge ergänzen:
{
...
entity: 'ce_my_entity',
...
}
hier kommt später noch was dazu!
Step 2
Den Type (der Entität) hinzufügen. Der Name muss nicht dem Namen der Entität entsprechen, ist aber nicht verkehrt es so zu machen.
Damit kennt die Suche nun den neuen Type und dann theoretisch schon danach suchen.
Step 3
Jetzt müssen wir festlegen wie unsere Entität bei den Ergebnissen dargestellt werden soll. Dafür erweitern wir ein Template und machen es der Suche bekannt.
Was noch fehlt Soweit ist alles gut und nach Anleitung. Aber es funktionierte einfach nicht. Es wurde nach allen möglichen Entitäten gesucht nur nicht nach der eigenen. Nach viel Gesuche kam ich dann darauf, dass bei den Preferences, die für die Liste der Entities genutzt wird, meine eigene garnicht aufgelistet wurde. Warum? Weil ich natürlich keine Preferences dafür hinterlegt hatte, weil es nirgendwo angegeben war.
Diese Preferences findet man im Profile seine Admin-Users und kann es dort alles noch genauer anpassen, wie die Suche suchen soll. Hier werden nun die Felder name und description angeboten und auch direkt aktiviert.
Damit funktionierte die Suche dann auch sofort wie gewünscht.
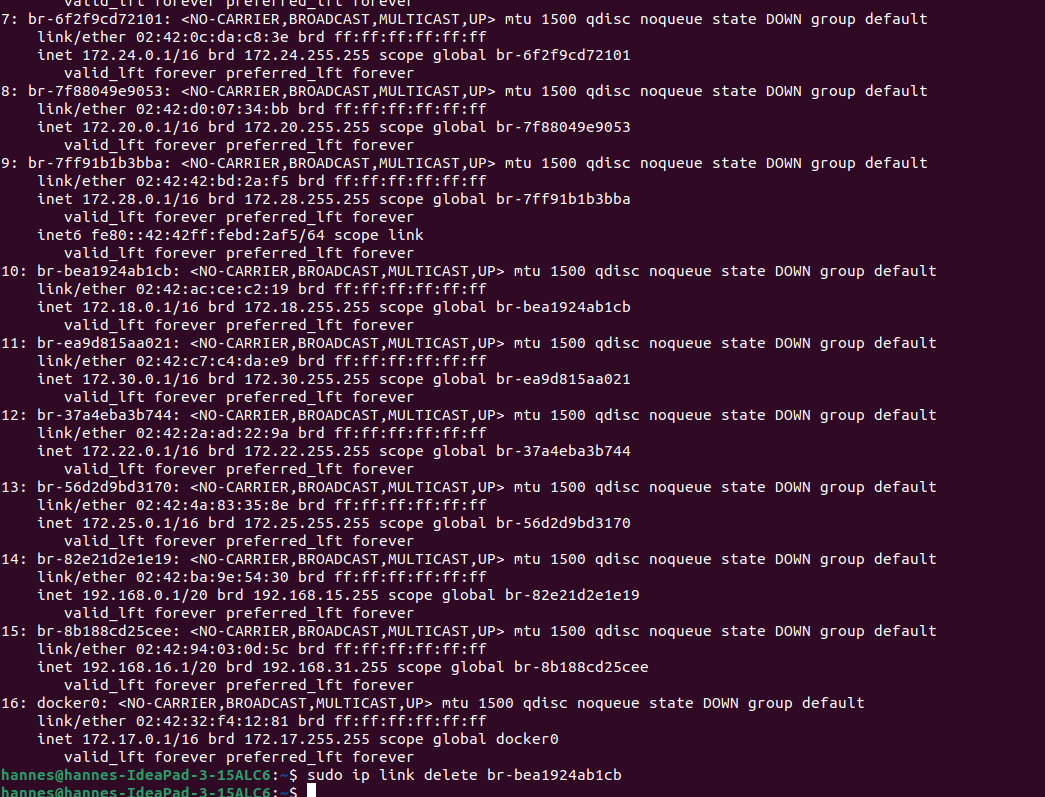
Während die Intenetnutzung im ICE mit dem Smartphone ohne Probleme geht, kann es mit Linux schnell zu Problemen kommen. Das liegt am IP-Bereich und Docker. Zwar kann sich das Gerät mit Linux ohne Probleme mit dem eigentlichen Netzwerk verbinden, aber dann kann die Seite zum bestätigen der AGBs nicht geladen werden.
Anleitung: - Mit dem WLAN verbinden
- prüfen welcher IP-Bereich zu gewiesen wurde
-
ip addr
- gucken welcher Eintrag mit dem Bereich kolliedert
- diesen Eintrag entfernen
-
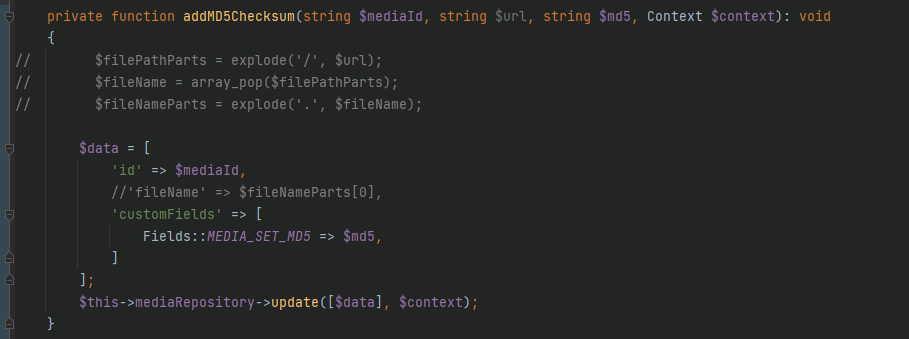
Meine erste Lösung war es den MD5-Hash als Dateiname zu nehmen. Dann später kam wollte ich doch lieber ein CustomField dafür nutzen (wie ich auch schon in der Shopware 5 Version ein Attribute genutzt hatte). Funktionierte alles super bis ich dann auf ein System kam, das nicht im dev-Mode lief. Am fileName hängt wohl mehr als man denkt und ich habe gelernt, dass man in einem produktiven Shopware 6 nicht den fileName ändern sollte. Kommt mit auf meine Liste der ganz großen Shopware 6 Nein-Nein's.
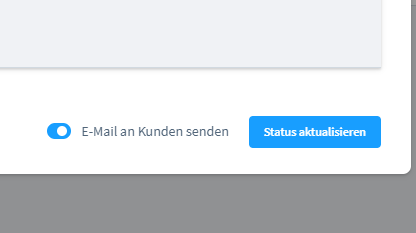
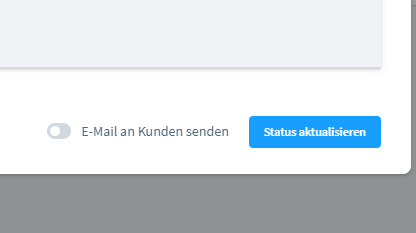
Oft will man einfach nur den Status der Stellung anpassen, weil irgendwas mit der Bestellung nicht stimmt oder man sie auf abgeschlossen setzen will, aber der Rest über das ERP/die WaWi läuft. Man will keine Mail an den Kunden senden. Leider ist die Mail immer direkt aktiviert und man muss immer daran denken diese zu deaktivieren.
Nervig.. also ein tolles kleines (wirklich kleines) Plugin-Projekt:
Gerade in Migrations kommt man manchmal in darum herum mit den UUIDs arbeiten zu müssen. Da es binary-Daten sind muss man etwas mit den anstellen, um die aus Shopware 6 bekannte Darstellung zu erreichen und auch um diese wieder die in Datenbank zu bekommen.
Lesen der Id: Um die aus Shopware 6 gewohnte Darstellung zu bekommen muss man in MySQL die HEX-Function verwenden. Zusätzlich muss der String noch in Kleinbuchstaben umgewandelt werden.
Schreiben der Id: Zuerst wieder alles in Großbuchstaben umwandelnt. Dann muss mit der MySQL-Function UNHEX der Hex-String wieder in binary Data umgewandelt werden.
Es bleibt zwar etwas umständlich, aber ist damit durch aus handhabbar. Da es in dem Sinne kein Autoincrement gibt für die UUIDs hilft dann dort Uuid::randomHex().
Gerade wenn man ein Produkt konfigurieren kann, ist es wichtig, dass CartItems nicht einfach aufaddiert werden, sondern jede Konfiguration als eigenes CartItem im Warenkorb abgelegt wird. Das CartItem von Shopware 6 hat auch ein stackable-Flag. Nun könnte man glauben, wenn man dieses auf false setzt, dass nicht das vorhandene CartItem geändert sondern ein neues angelegt wird, wenn erkannt wird, dass das vorhandene nicht stackable ist. Falsch! Man bekommt eine Exception.
Die Lösung ist zum Glück sehr einfach. Man muss selbst die Id des CartItems ändern um ein neues anzulegen. Also wenn man setStackable(false) setzt auch gleich die Id neu setzen. Oder man baut sich ein allgemeines Plugin, dass es macht.
BeforeLineItemAddedEvent:
if (!$event->getLineItem()->isStackable()) {
$event->getLineItem()->setId(Uuid::randomHex());
}
Manchmal sind ganz einfache Dinge sehr komplex. CSS-Ellipsis ist an sich einfach. Aber mit Flexbox kann es plötzlich dazu kommen, dass es einfach nicht funktioniert. Alles funktioniert nur die "..." sind nicht zusehen, weil es einfach alles zur Seite rausragt und die Breite hält.
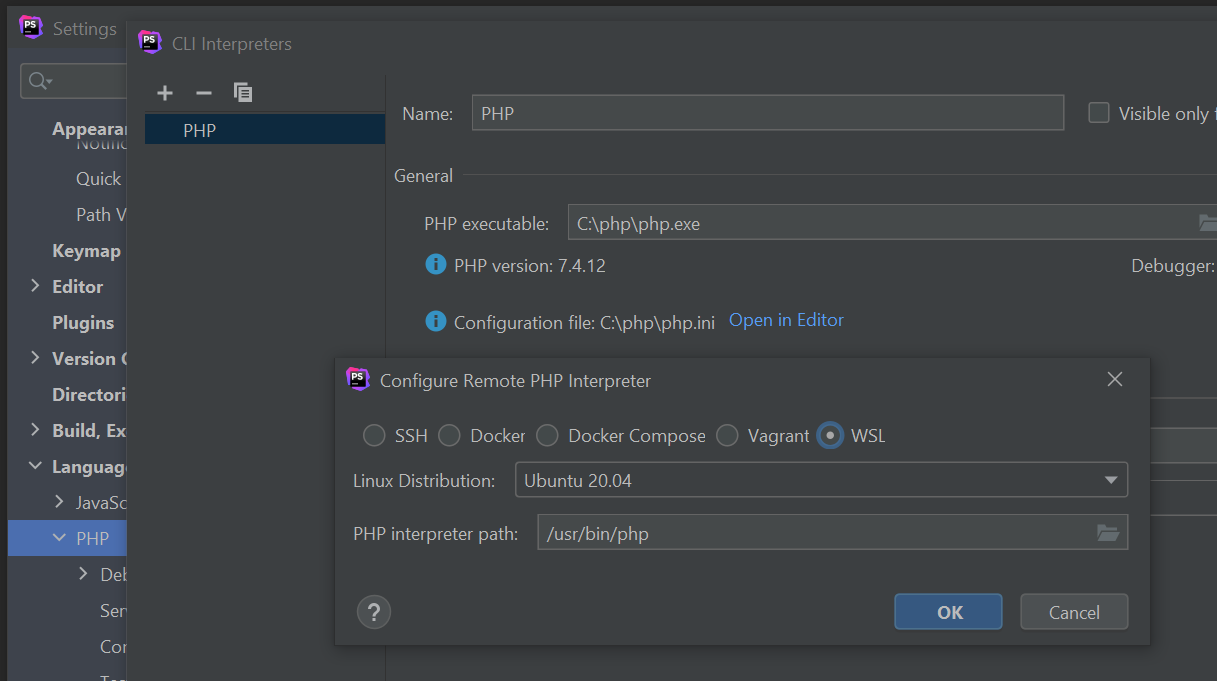
Das meiste findet man immer nur für die Bash. Aber wenn man Docker für Windows verwendet braucht man vieles für die PS. Ich habe hier mal ein paar kleine Dinge zusammen getragen.
Wenn man mit Windows arbeitet und dort PHPStorm nutzt hat man oft im Terminal die Bash offen, um die unter Windows geschriebenen PHP-Script unter WSL laufen zu lassen.
Aber Jetbrains war ja schlau und hat direkt in PHPStorm eingebaut die PHP-Runtime aus WSL als CLI-Rutime nutzen zu können. Genauso wie man eine Runtime nutzen kann die in einem Docker-Container läuft.
Diese einzurichten ist auch in einem Bild erklärt (wie man PHP unter Linux installiert wird ja an sich jedem PHP-Entwickler klar sein...).
Ich hatte das Problem, dass egal was ich versucht habe den Daten einer CSV sich nicht nach der Spalte mit dem Datum sortieren lassen wollten. Ich hab versucht die Spalte als Datum zu formatieren, aber das hat nicht geholfen. Am Ende war die Lösung:
Die Datum-Daten markieren. Suchen und Ersetzen aufrufen.
Suchen nach:
^.*$
Ersetzen durch:
$
und noch auswählen, dass nur im markierten Bereich gesucht werden soll und natürlich dass das ein RegEx-Ausdruck ist.
Ich hatte das Problem, dass der Befehl 'bash' nicht mehr mir die Bash meines WSL Ubuntu geöffnet hat sondern irgendwas machte und dann wieder in die Powershell zurück wechselte ohne was anzuzeigen. Das Problem kam wohl daher, dass ich Docker mit WSL vor Ubuntu installiert hatte. Also kein Hyper-V und kein Ubuntu. Daher war der 'bash' Befehl auf Docker gemappt und nicht auf das Ubuntu.
Man kann einen Update-Endpoint für Bestellungen definieren, der angesprochen, wenn sich der Status einer Bestellung bei EDC-Wholesale ändert. Problem ist, dass das nicht immer funktioniert und Hilfe auch nicht immer kommt. Aber man hat Mail die man parsen kann. Die wichtigsten Regex dafür sind:
Betreff:
/Auslieferung Ihrer Bestellung/
Body-Trackingcode:
/>(\d+)<\/b>/
Body-Ordernumber:
/Kontrollnummer:<\/b>\s*(\d+)<br/
Damit kann man alle Daten bekommen und seine Bestellungen updaten. Mit einer Shopware 5 Lösung kann ich gerne auf Anfrage helfen.
Manchmal muss man auch heute noch prüfen ob der Benutzer JavaScript
auf der Seite erlaubt hat oder ob ein Framework wie JQuery korrekt geladen und nicht geblockt wurde.
Prinzip ist einfach. Man versucht die Meldung mit JavaScript nach dem Laden der Seite auszublenden. Wenn es nicht klappt, liegt ein Problem vor und die Meldung ist für den Benutzer sichtbar.
Hier wird erklärt wie man im Chrome bewußt JavaScript deaktiviert, damit man solche Fälle testen kann.
Nach dem ich durch meinen neuen PC von einer 2TB SAS auf eine 2TB SATA HDD umgestiegen war, störten mich doch die Laufgeräusche sehr. DAs ist durch aus beachtlich da ich früher auch kein Problem mit 9GB Baracuda SCSI Festplatten hatte.. die 3,5 mit doppelter Bauhöhe.
Aber man wird älter und stört sich daran, wenn man die Festplatte beim Anlaufen hört.
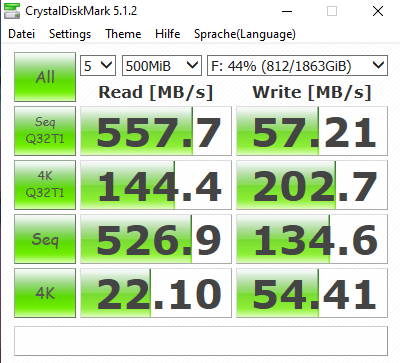
Die Crucial BX500 2TB ist ist relativ günstig. Aber man liest sehr viel negatives in den Kommentaren. Meine Benchmarks zeigen jetzt auch keine Werte wo man aus dem kleinen Haus wäre, aber als Ersatz für eine einfache Daten-Festplatte mehr als gut.
Das Kopieren der Daten von der HDD auf die SSD lief fast durchgehend konstant mit 200MB/s. Normales arbeiten mit PHPStorm läuft auch gut. Selbst das Project mit Shopware 5 und den paar wenigen Plugins lädt schnell genug. Am Ende fühlt sich einfach alles mehr "responsive" an.
Für das 20 Jahre alte Gehäuse erstmal ein Adapter drucken...
Irgendwann kommt es in jeder Firma zu dem Zeitpunkt an dem über Werte, Qualität gesprochen wird und wie man diese selbst leben kann. Bei allen die direkten Kundenkontakt haben ist es immer einfach: Nett sein, schnell helfen und auf die Bedürfnisse der Kunden eingehen. Bei einem Entwickler der vielleicht sogar nur Backend-Services für Firmen internen Software schreibt, ist es weniger einfach zu definieren, wie man die Werte leben soll und wie Qualität erzeugt werden kann.
Als erstes: Was ist ein Software Entwickler eigentlich? Dabei ist es glaube ich falsch sich auf die Tätigkeit zu beschränken. Viel mehr geht es um den Zweck. Software hat keinen Selbstzweck. Software ist nicht da, weil sie Software ist. Jede Software hat einen Zweck und dieser Zweck ist gerade im Firmenumfeld ein Problem zu lösen. Wenn alles schon perfekt wäre bräuchte man keine neue Software und keine Entwickler mehr. Der beste Entwickler ist der, der sich durch seine Software selbst überflüssig macht.
Software ist dabei auch nicht die Lösung, sondern das Werkzeug um zur Lösung zu kommen. Ein Software-Entwickler entwickelt Lösungen, die mit Hilfe von Software herbei geführt werden.
Wenn wir das Einhalten der Werte und der Qualität (was Qualität ist nicht zu diskutieren, sondern in den ISO-Normen festgelegt!) als die großen Probleme der Firma sehen, ist die Software natürlich nicht die Lösung, weil keine Firma 100% automatisiert ist. Wir müssen hier in Schichten denken. Für die Mitarbeiter, die Kundenkontakt haben oder die Produkte für die Kunden verwalten ist unsere Lösung deren Werkzeug. Wir lösen das Problem, das besteht, dass die ein größeres und abstrakteres Problem lösen können. Das macht die Software nicht weniger bedeutend, denn die Basis muss stimmen, damit die großen Probleme überhaupt bewältigt werden können. Der Software-Entwickler ermöglicht es dem anderen Mitarbeiter erst effektiv arbeiten zu können.
Jetzt mal konkreter, damit man sich nicht anfängt dabei m Kreis zu drehen. Welche Werte sollte ein Entwickler bei seiner Software anwenden, damit z.B. ein Mitarbeiter im Kundensupport seinen Job gut erledigen kann und der Kunde am Ende zufrieden und sicher verstanden fühlt?
Der Mitarbeiter sollte schnell alle Kundendaten sehen und bei Abfragen, sollte das System nicht einfach warten, sondern eine Meldung ausgeben, die der Mitarbeiter dem Kunden auch mitteilen kann, damit Wartezeiten erklärbar werden. Aber an sich sollte dieses nie nötig sein, weil Antwortzeiten immer verlässlich sind. Nennen wir diesen Wert der Software "responsive".
Fehler sind menschlich und unter Stress unvermeidbar und häufig. Wenn ein Kunde berechtigt oder unberechtigt Druck macht und etwas schnell gehen soll, sollte bei Fehlern immer eine brauchbare Fehlermeldung kommen oder auch versucht werden möglichst viel automatisch zu korrigieren. Niemals sollte wegen einer formal ungültigen ein Formular abstürzen, nicht funktionieren oder es erzwingen Daten erneut eingeben und damit erneut vom Kunden erfragen zu müssen. Wenn man zum dritten mal nach seiner Telefonnummer gefragt wird, wird das Benutzererlebnis echt schlecht. Nenne wir diesen Wert der Software "widerstandsfähig" oder "resilient".
Wenn Fehler in Systemen auftreten, kommen meistens viele Kundenanfragen auf einmal. Keiner will hören, dass es heute etwas länger alles dauert, weil das System durch die vielen Anfragen langsam ist. Gerade bei Sonderangeboten und überlasteten Systemen kann es sehr negativ auffallen, wenn ein Kunde etwas nicht bekommt, weil das System plötzlich nicht mehr reagiert. Systeme sollten sich schnell anpassen.
Wenn nun plötzlich 100 Kunden anstelle von 10 Kunden bedient werden müssen.. dann sollte alles noch genau so schnell und stabil sein wie sonst. Nennen wir diesen Wert der Software "elastisch", weil es flexibel Resourcen nutzen kann, wenn nötig.
Diese drei Werte kann man sehr gut auf die Meta-Begriff: Schnell, Kompetent und Zuverlässig übertragen.
Bestimmt kommen diese drei "Werte" den meisten schon aus dem Reactive Manifesto bekannt vor. Ich finde dieses orientiert sich so sehr an der alltäglichen Realität, dass es sich die Ansätze mehr als einfach nur ein Idee für gute Software-Systeme sind. An sich lässt sich damit alles beschreiben, wo Kommunikation stattfindet.
Dann gibt es noch so Werte, die an sich keine Werte sondern Selbstverständiglichkeiten oder auch gesetzliche Vorgaben sind. Z.B. Freundlichkeit. Egal ob eine andere Abteilung, ein Kollege oder ein Kunde eine Frage oder ein Problem hat, ist man freundlich. Niemand will nerven oder versteht Erklärungen aus Vorsatz nicht. Man muss natürlich auch bestimmend sein, wenn man z.B. an wichtigen Dingen sitzt und die Anfrage von der Priorität niedrig ist. Erklären und eine feste Zeit oder Einordnung geben. Man kümmert sich und der andere fühlt sich verstanden. Das ist auch Freundlichkeit.. und kompetentes Auftreten.
Und dann gibt es Datenschutz. Ist das ein Wert? Es ist gesetzlich vorgeschrieben. Ich glaube es sollte doch als Wert geführt werden, weil man sollte es leben und nicht nur ausführen, weil man es muss. Es macht alles einfacher, wenn Datenschutz gleich mit einfließt und nicht von einer anderen Abteilung später erzwungen wird. Don't be evil ist immer ein guter Ansatz!
Ich hoffe damit hab ich ein paar Ansätze und Denkanstöße geben können, womit ein Entwickler beim nächsten mal, wenn er nach Werten und Qualität gefragt, ein kleines Set an Werkzeugen an der Hand hat, um die Frage schneller beantworten zu können.
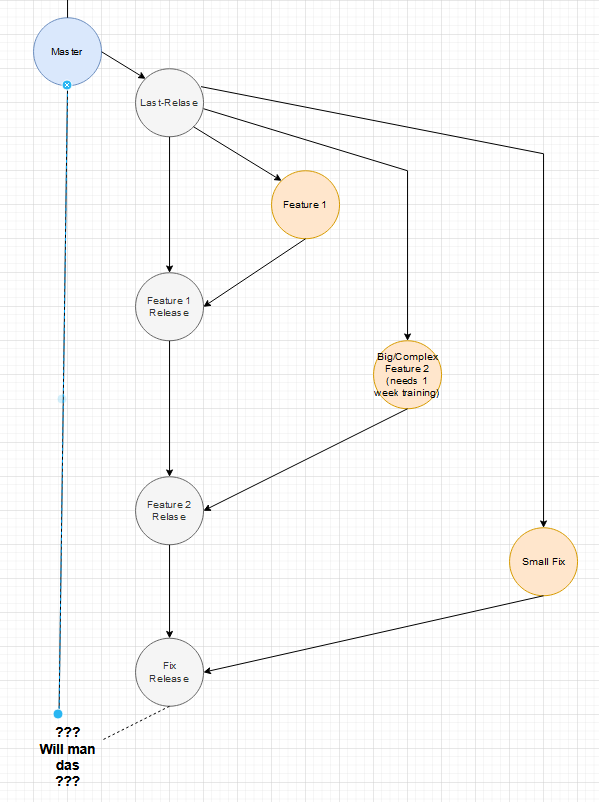
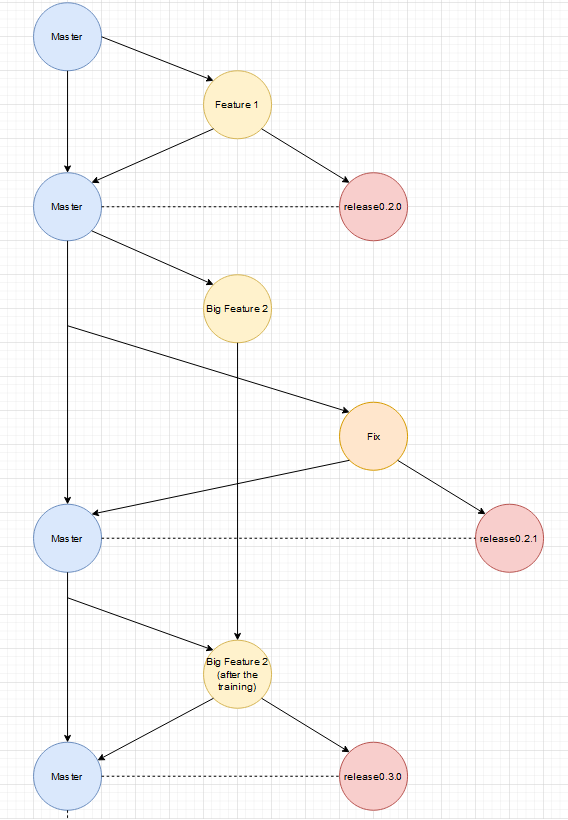
Ich halte Release-Branches für sehr problematisch. Manchmal können sie nützlich sein, aber in 99% aller Fälle sind sie überflüssig und bringen mehr Probleme mit sich. Nur wenn wirklich mehrere von einander abhängige Features gleichzeitig entwickelt werden wäre ein Release-Branch denkbar. Ob der dann auch wirklich einen Vorteil bringt, muss jeder dann für sich entscheiden.
Das Problem bei Release-Branches ist, dass alles was release-bereit ist auch da rein kommt. Schnell hat man das Problem, dass man seinen kleinen Fix da rein merged und feststellt, dass 3 weitere Features da drin liegen. Sie sind ja release-bereit, aber ein Release war noch nicht wirklich nötig. Entweder ändern die was, wo man die Benutzer noch instruieren muss oder sie sind nicht so wichtig man hat den Release auf den Ende des Sprints geschoben. Jetzt steht man da und muss erst mal von allen anderen die Info einholen, ob man die Features mit seinem Fix mit releasen kann oder man jetzt doch einen eigenen
Release-Branch aufmachen sollte.
Bloß weil etwas release-fertig ist, heißt es nicht dass ein Release möglich ist!
Die meisten Features und Fixes stehen für sich selbst und sie in einen gemeinsamen Release-Branch zu bringen blockiert schnelle Releases einzelner Features. Für jeden Feature-Branch einen eigenen Release-Branch auf zu machen ist aber auch nicht sinnvoll. Der Feature-Branch sollte meiner Meinung nach auch sein eigener Release-Branch sein... also man braucht nur den Feature-Branch.
Plugins für Shopware 6 zu schreiben ist an sich garnicht so unterschiedlich zu dem selben Vorgang für Shopware 5. Was nur anders geworden ist, dass Shopware eigene XMLs und Enlight-Components durch den Composer und Symfony abgelöst wurden. Man kann nun wirklich Namespaces definieren, die unabhängig vom Plugin-Namen sind und es ist kein Problem mehr den Composer mit Plugins zu verwenden, sondern es ist jetzt der zu gehende Weg.
Setup
Wie gehabt kann man sein Plugin unter custom/plugins anlegen.
custom/plugins/HPrOrderExample
Zu erst sollte man mit der composer.json anfangen.
Wichtig in der composer.json ist einmal der PSR-4 Namespace den man auf das src/ Verzeichnis setzt und der "extra" Teil. Dort wird alles definiert, was mit Shopware zu tun hat. Hier wird auch die zentrale Plugin-Class angegeben, die nicht mehr wie in Shopware 5 den selben Namen des Verzeichnisses des Plugins haben muss. Auch sieht man hier dass der Namespace-Name nichts mehr mit dem Verzeichniss-Namen zu tun hat.
Wir könnten durch die composer.json das Plugin auch komplett außerhalb der Shopware-Installation entwickeln, weil die gesamte Plattform als Dependency eingebunden ist. Deswegen müssen wir auch einmal den Composer ausführen.
php composer install
Plugin programmieren Nun fangen wir mit dem Schreiben des Plugins an.
Die Plugin-Klasse enthält erst einmal keine weitere Logik:
<?php
namespace HPr\OrderExample;
use Shopware\Core\Framework\Plugin;
class OrderExample extends Plugin{
}
Wir wollen auf ein Event reagieren. Dafür benutzen wir eine Subscriber-Klasse. Während man diese in Shopware 5 nicht unbedingt brauchte und alles in der Plugin-Klasse erldedigen konnte, muss man nun eine extra Klasse nutzen und diese auch in der services.xml eintragen. Die Id des Services ist der fullqualified-classname des Subscribers
Resources ist vordefiniert, kann aber in der Plugin-Klasse angepasst werden, so dass diese Dateien auch in einem anderen Package liegen könnten.
src/Subscribers/OnOrderSaved
<?php
namespace HPr\OrderExample\Subscribers;
use Shopware\Core\Checkout\Order\OrderEvents;
use Shopware\Core\Framework\DataAbstractionLayer\Event\EntityWrittenEvent;
use Symfony\Component\EventDispatcher\EventSubscriberInterface;
class OnOrderSaved implements EventSubscriberInterface {
/**
* @return array The event names to listen to
*/
public static function getSubscribedEvents()
{
return [
OrderEvents::ORDER_WRITTEN_EVENT => ['dumpOrderData']
];
}
public function dumpOrderData(EntityWrittenEvent $event) {
file_put_contents('/var/test/orderdump.json', json_encode($event->getContext()));
}
}
Hier sieht man, dass nur noch Symfony benutzt wird und keine Shopware eigenen Events.
Wir schreiben einfach die Order-Entity, die gespeichert wurde in eine Datei. Dort können wir UUID und ähnliches der Order finden.
Das ganze kann man dann weiter ausbauen und auf andere Order-Events (die man alle in der OrderEvents.php finden kann) reagieren.
Installieren
Damit ist das Plugin auch schon soweit fertig. Den Composer haben wir schon ausgeführt (ansonsten müssen wir es spätestens jetzt machen).
Nun geht es über die UI oder die Console weiter. Dort wird das Plugin installiert und und aktiviert.
Wenn man nun eine Bestellung ausführt wird, deren Entity in die oben angegebene Datei geschrieben.
Ein Update auf 5.6 ist schnell und einfach gemacht. Alle Tests liefen super und es sah nach einer 2 Minuten Aktion aus... dann kam das SwagPaymentPaypal und nutzte Shopware::VERSION. Um genau zu sein in der Bootstrap.php in Zeile 146. Das gibt es in 5.6 aber nicht mehr und deswegen lief dann auch gar nichts mehr. Das Plugin lies sich auch nicht deaktivieren.
Wer also das Plugin noch nutzt sollte es unbedingt durch SwagPaymentPayPalUnified ersetzen. Das alte muss deinstalliert werden, weil die selben Config-Namen verwendet werden.
Wer das alte noch hat und in das selbe Problem läuft, muss dann leider die Zeile 146 per Hand ändern. In etwas wie das hier:
if (false) {
Darin wird etwas für Shopware < 4.2.0 gemacht, was wir mit 5.6 eindeutig nicht mehr brauchen.
Es kann dazu kommen, dass beim Aufruf der console von Shopware 5 keine kernel.environment gesetzt ist. Bei Webserver Aufrufen wird diese ja zumeist in der conf des Apache gesetzt.
Um jetzt die Environment (z.B. "production") direkt beim Aufruf der console zu setzen muss man die Option "e" setzen und schon geht alles.
Jeder Java-Entwickler kennt es. Properties definieren und dann Setter und Getter erzeugen lassen. Wenn man was ändert, wird es nervig und wenn man was hinzufügt, muss man die fehlenden Methoden neu generieren lassen. Das geht an sich immer schnell, ist aber doch immer nervig.
Lombok übernimmt die Erzeugung dieser Methoden zur Compiling-Zeit. Die IDE benötigt ein Plugin und der Rest wird dann über Maven erledigt.
AngularJS hat beim IE (älter als Edge) ein Problem mit ng-change, wenn ein Input über eine DataList gefüllt wird. Dann wird einfach kein Event ausgelöst. Mit einer kleinen Hilf-Function und $scope.$applyAsync() in der Scope-Function kann man das aber reimplementieren.
function onChangeIE(value){
var ua = window.navigator.userAgent;
if((ua.indexOf('Trident/') > 0 || ua.indexOf('MSIE ') > 0) && ua.indexOf('Edge/') <= 0) {
angular.element(document.getElementById('my-ng-controller-element')).scope().myInputModel = value;
angular.element(document.getElementById('my-ng-controller-element')).scope().myNgChangeFunction();
Die beste Lösung wäre solche alten Browser nicht mehr zu supporten und dann vielleicht auch auf Vue.js oder eine aktuelle Angular-Version zu wechseln.
Aber für schnelles Prototypen, wo man wenig Code schreiben will, ist AngularJS noch immer sehr gut. Teilweise ist man so schnell damit, dass man während einer Diskussion die Ideen direkt nebenbei umsetzen und ausprobieren kann. Wenn man erst einmal viele Components schreiben muss, geht es nicht so gut, wie mit den AngularJS Templates und Dingen wie ng-options. Mit Vue.js ist man mit etwas Übung aber auch ähnlich schnell.
Manchmal ist es echt unpraktisch viele kleine JAR-Dateien zu haben und man hätte gerne alles in einer großen. Keine Class-Path Probleme mehr, einfaches Deployen und ein Single-Point-Of-Failure.
Mit Maven geht das zum Glück sehr einfach. Spring Boot und Meecrowave haben eigene Plugins mit denen man auch sehr gut arbeiten kann und die dem Beispiel hier vorzuziehen sind.
Wenn man JSON-Dateien mit längeren Texten bearbeitet, ist dieses oft sehr unübersichtlich, weil JSON keine Zeilenumbrüche innerhalb eines String zulässt. Zum Glück können einen IDEs da helfen, da sie eine Zeile in mehreren Zeilen im Editor darstellen können.
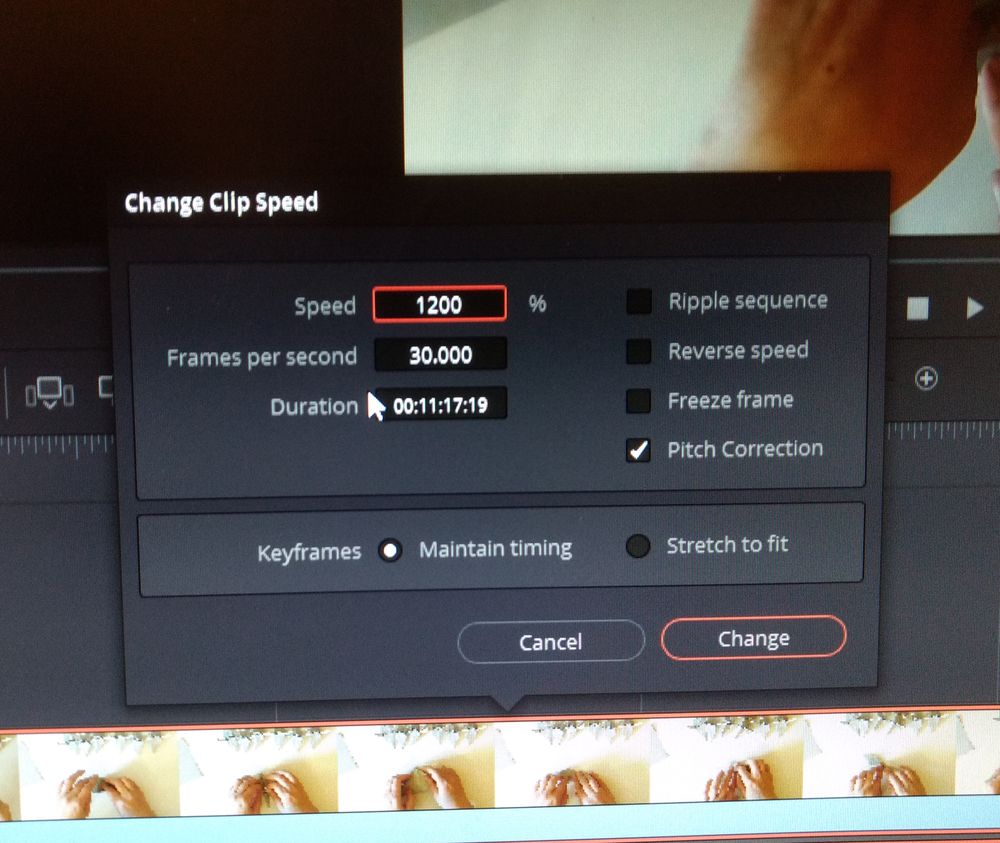
Im Gegensatz zu NCH Videopad, das nur bis 800% Speedup kommt (man muss für mehr zwischen durch immer exportieren), kann Blackmagic DaVinci Resolve auch weit über 1000% beschleunigen, so dass man man 11:00min auf unter 1min stauchen kann. Das geht auch ganz einfach. Auf den Clip den man ändern möchte mit einem Rechtsklick das Context-Menü öffnen und "Change Clip Speed" auswählen. Wenn man die %-Zahl ändert, sieht man auch direkt welche Länge der Clip dann haben wird.
In der Vorschau ruckelte es zwar noch sehr, aber nach dem Exportieren lief alles es flüssig. Ich muss mich wohl noch mal mit den Vorschau-Einstellungen auseinander setzen. Da es nur ein 720p Video war und nicht mal 4K.
ESM-Computer hat einen sehr interessanten Blog-Post geschrieben, der mich an alte Zeiten in Foren erinnert hat, wo man Freeware und Open-Source Listen hatte, damit die Mitglieder nicht ihr Geld für "fragwürdige" Software ausgeben, ob man für weniger (also nichts) mehr bekommen würde und auch um etwas zu Zeigen, dass es neben Adobe noch andere Lösungen gibt. Meiner Meinung nach fehlen in dem ESM-Post aber noch ein paar sehr gute Lösungen.
1. Videoplayer Da hat ESM-Recht... ich hatte den noch auf NT 4.0 laufen und es gab damals eigentlich keine Alternative. Es gibt den Server nicht mehr.. ja.. es gab einen Server und einen Client (das C in VLC steht für Client).
Man kann Video-Streams nehmen und ein eigenes Logo einbauen und es dann weiter streamen. Auch auf kleiner Hardware mit 1,2GHz und 2GB kann man ohne Probleme einen Stream von einem SAT-IP Server streamen und so ein Stream braucht wirklich Bandbreite.. wirklich viel.
2. Audio Seit neusten gibt es Cakewalk Sonar als Freeware. Seit Cakewalk-Zeiten (Cakewalk 5.0?) war es immer eine gute Lösung, auch wenn der aktuellen Freeware-Version einiges fehlen soll, ist es sicher immer noch eine gute Lösung.
3. Video Ich habe Lightworks ausprobiert und fand es so gut wie unbedienbar. Gerade für kleine Video hatte ich nicht die Ruhe mich lange damit zu beschäftigen. Früher war Adobe mit Premiere und AfterFX das Non+Ultra. Es gab noch exotischere Programme wie die von Autodesk/Discreet (Smoke, Combustion, etc). Aber an die kam man so garnicht ran ohne gleich ein komplettes Schnittsystem zu kaufen. Aber jetzt gibt es Blackmagic DaVinci Resolve, das auch keine großen Einschränkungen hat. Ich habe mir jeden Falls vorgenommen darauf umzusteigen, wenn ich mal wieder ein Video schneiden muss. Die Blackmagic Produkte kennt man ja und die waren schon immer cool.. auch deren Kameras.
Gibt es auch für Linux! Super professionelle Schnittlösungen für Linux waren lange echt nicht zu finden.. jetzt gibt es viele.
4. Audio 2 Ja.. kann man immer gut gebrauchen. Früher gab es noch Cool Edit Pro, bevor es von Adobe gekauft wurde und zu Audition wurde. Die erste Adobe Version war noch eine 1:1 Übernahme des Programms mit geänderten Namen.
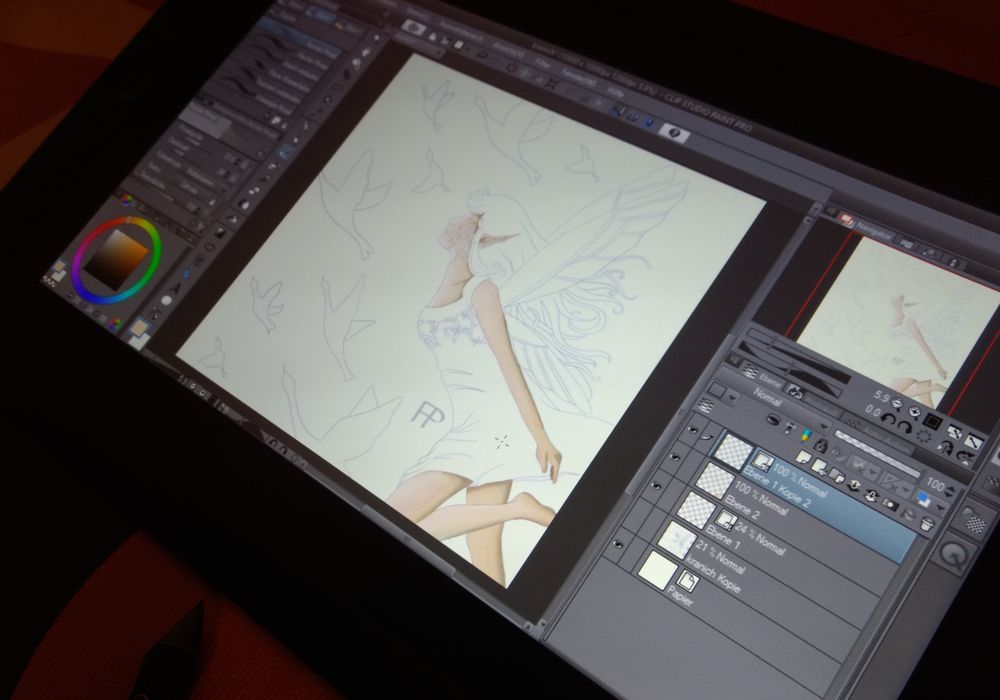
5. Grafik Klar gibt es GIMP, das super für Fotos ist. Wer aber malen möchte ist mit Krita besser beraten. Für Zeichner wohl auch besser als Photoshop. Leider hat es keine 3D-Figuren wie Clip Studio Paint Pro.
Wacom Cintiq mit Clip Studio Paint
Vielleicht baut ja jemand mal ein Plugin um Blender zu integrieren. Genau wie GIMP stammt auch Krita aus der Linux-Welt und wurde dann auf Windows portiert.
Krita hat auch Pixelart Werkzeuge, aber kann sehr viel weniger als Aseprite, dass nicht kostenlos ist, aber als Portable multiplattform Lösung seine paar Euro echt das Geld wert ist (gibt es im Humble Bundle Store). Für Windows gibt es [url=http://www.ultimatepaint.com/de/]Ultimate Paint als kostenlose EA DeluxePaint Kopie (ja EA hat mal Grafik-Software gemacht! Hatte ich mal auf einem 386er.).
Animation mit Aseprite erstellt
Ultimate Paint
6. Grafik RAW Für die Bearbeitung von RAW-Fotos und als Alternative zu Lightroom gibt es noch RawTherapee für Windows und Linux. Begleitet mich seit meinen Nikon D80 Zeiten.. f*ck.. ist das schon lange her.
Der Vorteil der meisten genannten Lösungen ist einfach, dass es sie für Linux gibt, man also auch nicht mal mehr Windows als kostenpflichtige Software braucht. Ich mag Linux Mint.. wobei Windows 10 meiner Meinung nach die beste Windows Version seit NT 4.0 ist.
Manchmal soll Logik auf Daten einer Map zugreifen können aber nicht ändern können. Ich habe für meine State-Implementierung Action-Dispatcher eingeführt, die Daten der Action anpassen dürfen und dafür auch Daten aus dem State zum Abgleich nutzen sollen, aber an der Stelle sollen sie nicht die Möglichkeit haben den State selbst zu ändern, weil ich an der Stelle keine Änderungen tracke. Action-Dispatcher sollen schnell und leichtgewichtig sein.
Zum Glück kann man mit Collections sich schnell eine unmodifiable Map erstellen. Was das für die Performance bedeutet habe ich noch nicht getestet, aber ich gehe davon aus, dass das Tracken und Behandeln von Änderungen am State am Ende auf wendiger wäre.
Falls man mal CSV-Daten per CURL irgendwo hin schicken will und es funktioniert einfach nicht, wie gedacht.. dann sollte man überprüfen, ob man nicht --data-binary vergessen oder durch -d ausgetauscht hat und somit alle Zeilenumbrüche verloren gegangen sind.
Da zuerst zu gucken, dann einen viel Zeit bei der Fehlersuche ersparen.
Ein Problem bei Smarty 3 ist, dass man zwar sehr schön Blöcke überschreiben oder erweitern kann, es aber keine Möglichkeit gibt, die im Block vorhanden anderen Blöcke dan unangetastet zu lassen. Man muss in so einem Fall die nested Blöcke immer mit kopieren und mit dem Parent-Template immer wieder bei Änderungen abgleichen. Wenn z.B. ein Template einen Block mit einer <form> hat und darin dann die ganzen Eingabe-Möglichkeiten auch als Blöcke ausgelegt sind, muss man wenn man die Form-Action ändern will zwingend auch das ganze Form-Content Templating mit übernehmen.
Eine Möglichkeit das zu umgehen ist den Block rendern zu lassen und dann per String-Operationen das Ergebnis anzupassen. Primitiv aber auch sehr effektiv!
Falls man Formular von Shopware in anderen Contexts als dem forms-Controller einsetzt, kann es nötig sein, dass Template so anzupassen, damit es noch auf den forms-Controller zeigt und nicht auf den Controller in desen Context man gerade arbeitet.
Damit ist es auch schon erledigt und man kann anfangen Seiten der Gruppe zu zuordnen und sie werden entsprechend gerendert. Unterseiten und ähnliches sind auch möglich, wie frontend/index/footer-navigation.tpl zeigt. Die Gruppen findet man in der Datenbank in der Table s_cms_static_groups.
An sich ist das hier vollkommen logisch und man wundert sich warum man diesen Fehler überhaupt gemacht hat.. weil man den vorher nicht gemacht hat. Deswegen sollte man im Kopf behalten, dass wenn man optionale Parameter im Methodenaufruf im REST-Controller in Spring hat, diese null als Wert haben können müssen.
Einfach gesagt Integer verwenden und nicht int, weil das natürlich Probleme geben würde, wenn Spring null in einen int füllen möchte.
Wenn man verschiedene application.properties Dateien für verschiedene Spring Boot Anwendungen vorhält kann man diese übe einen VM Parameter auswählen. Wenn wir z.B. ein Profil für "local" haben, wo eine DB auf Localhost verwendet werden soll, geht es so:
-Dspring.profiles.active=local
Damit wird dann die application-local.properties verwendet.
Manchmal will man später Dateien oder Verzeichnisse in die .gitignore aufnehmen, die man vorher nicht drin hatte und mit versioniert hatte. Das Hinzufügen zur gitignore reicht aber nicht, um die Dateien aus dem Repository verschwinden zu lassen.
Da muss man zuerst
git rm -r --cached .
ausführen und dann wieder alle Dateien adden. Dann werden die nun ignorierten Dateien als gelöscht in Git geführt.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: