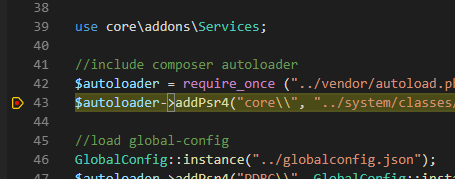
Um z.B. in einer Gitlab Pipeline den AWS secretsmanager zu nutzen, um Passwörter oder Token abzufragen muss man erstmal den CLI Client installieren und konfigurieren. Das geht am Besten wenn man die Dateien direkt schreibt.
Manchmal braucht einfach Imagick. Z. B. wenn man eine Bildvorschau einer PDF erzeugen will oder einfach mehr Power bei der Bildbearbeitung in PHP oder in Scripten braucht.
Während die Installation die meisten Anleitungen für Docker und Imagick mit den default PHP Docker-Image super funktionieren ist es bei Dockware anders, weil es eine volle Ubuntu-Umgebung mitbringt.
Zu beachten ist, dass man für alle PHP-Versionen die Erweiterung installieren muss.
Viele erinnern sich noch an Zeiten, wo man direkt auf einem Webserver seinen HTML-Seiten und Scripts geschrieben und getestet hat. HTML ging meistens schon lokal, aber wenn es um PHP oder anderes ging brauchte man einen Server. Dann schwenkte man auf XAMPP um, wo man einen lokalen Apache nutze. Linux brachte den Apache und PHP direkt mit. Aber man hatte oft kein Linux und half sich mit VirtualPC oder VirtualBox, so man entweder eine shared Speicher hatte oder ganz klassisch per FTP oder später SCP/SSH seine Dateien aus der IDE ins Zielsystem bekam. Dann kam Docker und die Welt wurde gut.. über all gut? Nein, dann erstaunlich viele gerade im Agentur-Bereich arbeiten immer noch mit einem Server und einem FTP-Sync. Gut heute oft mit SFTP oder SCP, aber ohne Docker oder lokalen Webserver.
Während ich klassische vServer mit Apache und ohne Reverse-Proxy und Docker für veraltet halte, sind sie noch öfter Realität als Docker-/K8n-Umgebungen. Selbst shared-Hosting für produktive Umgebungen sind noch öfters anzutreffen.
Nach einem Gespräch, wo noch direkt auf dem Server gearbeitet wurde und nicht mal eine lokale IDE einen Sync in Richtung Server vornahm sondern direkt die Datei vom Server aus geöffnet wurde (da kann man fast direkt mit vi auf dem Server arbeiten...), hier eine einfache kostenlose Lösung, wo man wenigstens die Dateien lokal hat und so auch ohne Probleme mit Git arbeiten kann.
Genutzt wird VisualStudio Code (die Intellij-IDEs bringen so einen Sync direkt von Haus aus mit, kosten aber in den meisten Varianten Geld).
Ein Plugin installieren:
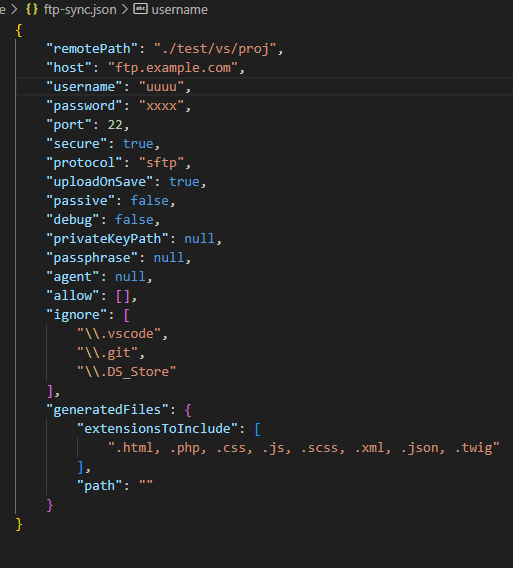
FTP-Config anlegen (wird geöffnet nach dem ersten Sync-Versuch):
Wenn uploadOnSave aktiviert ist am Besten die IDE noch mal neustarten.
Geht auf jeden Fall besser als WinSCP parallel zum Sync laufen zu lassen.
Würde ich so entwickeln wollen? Nein. Besonders wenn mehr als ein Entwickler an einem Projekt arbeiten, geht nichts über Docker. Für Shopware habe ich gute Images oder man nimmt Dockware, was gerade für Entwickler an sich vollkommen reicht.
Update meiner Shopware Docker Umgebung. Funktioniert mit 6.4. An 6.5 arbeite ich noch. Es ist Imagick installiert, um z.B. automatisch beim Upload von PDFs die erste Seite als JPG zu speichern und in einem CustomField als Vorschau zu verlinken.
RUN docker-php-ext-install dom \
&& docker-php-ext-install pdo \
&& docker-php-ext-install pdo_mysql \
&& docker-php-ext-install curl \
&& docker-php-ext-install zip \
&& docker-php-ext-install intl \
&& docker-php-ext-install xml \
&& docker-php-ext-install xsl \
&& docker-php-ext-install fileinfo
RUN mkdir -p /usr/src/php/ext/imagick
RUN curl -fsSL https://github.com/Imagick/imagick/archive/06116aa24b76edaf6b1693198f79e6c295eda8a9.tar.gz | tar xvz -C "/usr/src/php/ext/imagick" --strip 1
RUN docker-php-ext-install imagick
RUN echo 'memory_limit = 512M' >> /usr/local/etc/php/php.ini
RUN a2enmod rewrite
RUN php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
RUN php composer-setup.php --2.2 #there are problem
RUN mv composer.phar /usr/local/bin/composer
# copy conf-file to /etc/apache2/sites-enabled/000-default.conf
RUN mkdir /files;
COPY ./setup.sh /files/setup.sh
ENTRYPOINT ["sh", "/files/setup.sh"]
Wenn man weiß man tun muss ist es an sich recht einfach.
Wir brauchen Verzeichnis mit ./db_data und ./app. Zusätzlich noch eine leere .env Datei.
Um nichts mit DDEV zu tun haben zu müssen gehen wir zu GitHub und laden uns das letzte Release als Zip herunter. Die entpacken wir dann ins app-Verzeichnis.
Nun alles mit docker-compose up -d starten. Sich auf den web-Container per docker exec verbinden. Er hat keine bash sondern nur die sh. Aber egal. Einmal dieses Command ausführen:
php craft setup/security-key
Das generiert uns einen Security-Key für Cookies.
Nun http://localhost:8080/admin/install aufrufen und die Installation kann starten.
Getestet unter Windows mit Docker + WSL2. Sollte also auch ohne Probleme so unter Linux und auf einem Mac funktionieren.
Wenn man sich die Anleitungen durchliest, wie man Marlin selbst compilieren kann, muss mn immer VSCode mit vielen Plugins und so installieren. Alles sehr aufwendig. Aber es geht auch viel einfacher. Dank https://github.com/frealmyr/marlin-build kann man es einfach per Docker bauen. Man muss nur auf eine Sache achten: USE_TAG angeben und in docker-compose einkommentieren und die Configs für diese Version nutzen.
# This file is to be used with docker-compose.yml, or sourced before using docker run
BOARD=STM32F103RE_creality
MARLIN_FIRMWARE=./out
MARLIN_CONFIGURATION=./ender3_marlin_config
USE_TAG=2.1.2
meine docker-compose.yml so:
version: "3.5"
services:
build:
container_name: marlin-build
image: frealmyr/marlin-build:latest
user: 1000:1000
stdin_open: true
tty: true
environment:
- BOARD
# - USE_LATEST=true # Use latest git tag
# - USE_REPO=https://github.com/frealmyr/Marlin # USe a different git repo
- USE_TAG
# - USE_BRANCH=bugfix-2.0.x # Use a branch instead of latest tag
# - FW_EXTENSION=hex
volumes:
- $MARLIN_FIRMWARE:/home/platformio/build
- $MARLIN_CONFIGURATION:/home/platformio/CustomConfiguration
# - ./build-marlin.sh:/home/platformio/build-marlin.sh # Use build script in repo instead of image
wie man sieht ist das Github-Projekt auszuchecken optional, die beiden Dateien reichen an sich.
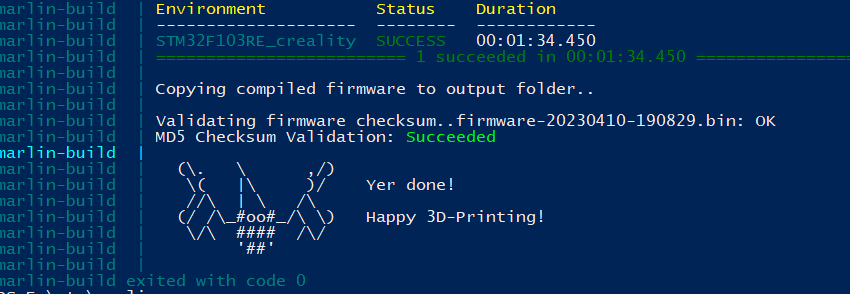
Um nun Marlin 2.1.2 für den Ender 3 mit Creality Board 4.2.7 zu bauen muss man nur noch eines tun:
Ein einfacher Weg PHPUnit in einer GitLab-CI Pipeline zu nutzen. An PHP 8.2 arbeite ich noch. Da gab es Probleme mit der Socket Extension. AMQP Extension lief nach einigem Suchen im Internet.
Während die Intenetnutzung im ICE mit dem Smartphone ohne Probleme geht, kann es mit Linux schnell zu Problemen kommen. Das liegt am IP-Bereich und Docker. Zwar kann sich das Gerät mit Linux ohne Probleme mit dem eigentlichen Netzwerk verbinden, aber dann kann die Seite zum bestätigen der AGBs nicht geladen werden.
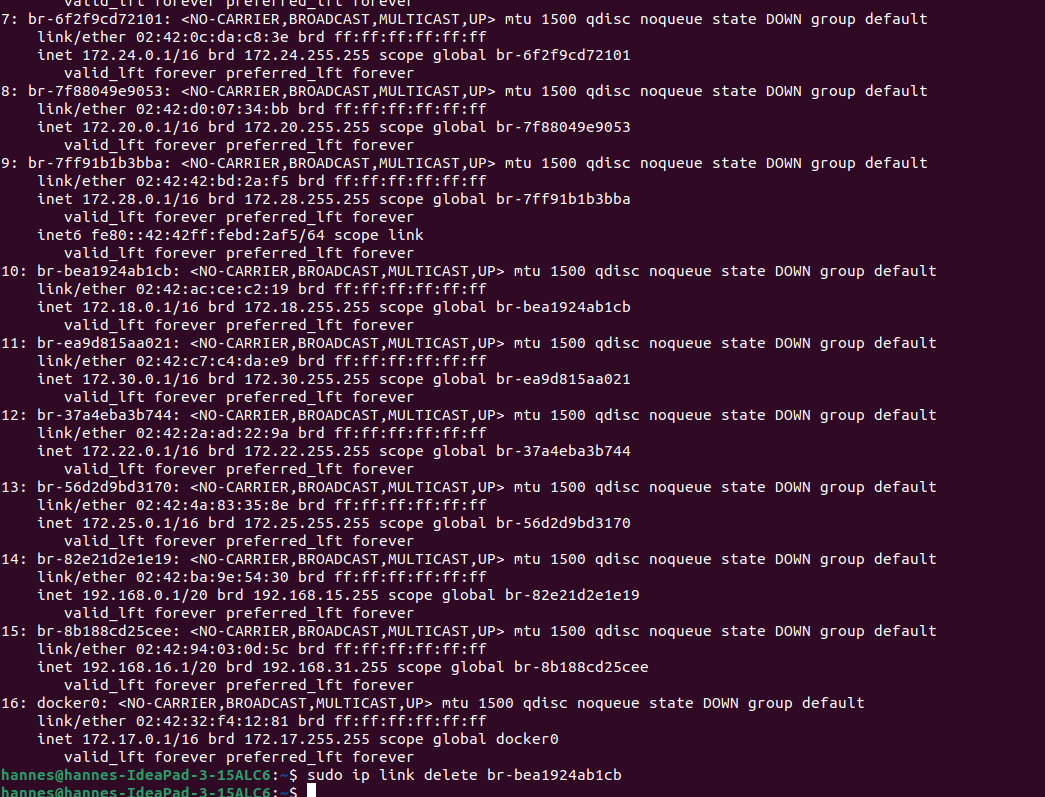
Anleitung: - Mit dem WLAN verbinden
- prüfen welcher IP-Bereich zu gewiesen wurde
-
ip addr
- gucken welcher Eintrag mit dem Bereich kolliedert
- diesen Eintrag entfernen
-
An sich ist es garnicht sooo schwer Nuxeo mit einem Keycloak zu verbinden und dann die Benutzerverwaltung allein über das Keycloak abzuwinkeln. Leider ist die Dokumentation dazu sehr dürftig und zu großen Teilen einfach veraltet und lückenhaft. Hier wird einmal in kurzer Form erklärt wie man das mit einer aktuellen Version von Nuxeo 10.10 bewerkstelligen kann. Man sollte das 10.10 Repository von Github einmal per Maven komplett selbst gebaut haben. Wir hatten die HF53-Version und ein Grundsetup als Docker-Image ist unter annonyme/nuxeo:HF53 zu finden. Besser ist aber wenn man sich das vollständig selbst baut. Das Docker-Repository hilft beim Bauen.
Die Erweiterung für Nuxeo
Das Repository für die Nuxeo Platform Login Keycloak Erweiterung ist Teil des Nuxeo Mono-Repository und kann direkt mitgebaut werden. Die Anleitung dazu ist vollkommen veraltet, aber ich nehme sie hier als Basis. Man braucht um dieses benutzen zu können:
Die Dateien aus der Zip der Adapter-Dist, die JAR vom Nuxeo Platform Login Keycloak sowie die JAR des UserMapper Services müssen alle in das selbe plugin/ Verzeichnis kopiert werden wie in der Anleitung erklärt wird. Das config/ Verzeichnis wie im Repository einfach auch rüber kopieren. Der Inhalt der JSON-Datei kann direkt aus dem Nuxeo kopiert werden und
ist die Config-Datei für den Keycloak Tomcat-Adapter und hat also an sich nichts mit Nuxeo zu tun. Dem entsprechend ist die Dokumentation zu der Datei auch um Welten besser als bei den Nuxeo Komponenten.
In der Anleitung wird alles in ein Template-Verzeichnis kopiert. Ein Template ist ein Profile für verschiedene Nuxeo-Konfigurationen und es können mehrere davon gleichzeitig verwendet werden. Den Docker-Container muss man dann also mit NUXEO_TEMPLATES: docker,keycloak starten.
Das war es dan nauch. Beim Login in Nuxeo einfach einen Account aus dem Keycloak verwenden und der Benutzer sie wie die im Keycloak zugeordneten Rollen/Gruppen werden ins Nuxeo übernommen.
Wenn man nochmal mit dem Administrator-Konto ins Nuxeo will und dieser noch nicht im Keycloak angelegt ist, muss man nur direkt /nuxeo/login.jsp aufrufen und bekommt die Nuxeo-Anmeldung ohne auf die Realm-Anmeldeseite des Keycloak weiter geleitet zu werden.
Es sind keine weiteren Konfigurationen an Nuxeo nötig. Wenn man sich ein Docker-Image baut muss also nur die keycloak.json aus dem config-Verzeichnis des Templates ersetzt werden können.
Das meiste findet man immer nur für die Bash. Aber wenn man Docker für Windows verwendet braucht man vieles für die PS. Ich habe hier mal ein paar kleine Dinge zusammen getragen.
Ich musste mir eine sw2-Datenbank anlegen über root/root, aber an sich sollte es wie in meinem SW5-Environment auf mit der sw-Datenbank und sw/sw gehen.
Jeder der schon mal mit PHP zu tun hatte wird sicher die Installationsanleitung von getcomposer.org. Das Problem ist nur, dass seit einiger Zeit Composer 2.0 installiert wird und einige alte Projekte damit echt ihre Probleme haben. Aber wie installiert man sich eine bestimmte Version? So das nicht plötzlich der Docker-Container nach einem neuen Build eine andere Composer-Version hat und die Pipeline nicht mehr funktioniert.
Ich hatte das Problem, dass der Befehl 'bash' nicht mehr mir die Bash meines WSL Ubuntu geöffnet hat sondern irgendwas machte und dann wieder in die Powershell zurück wechselte ohne was anzuzeigen. Das Problem kam wohl daher, dass ich Docker mit WSL vor Ubuntu installiert hatte. Also kein Hyper-V und kein Ubuntu. Daher war der 'bash' Befehl auf Docker gemappt und nicht auf das Ubuntu.
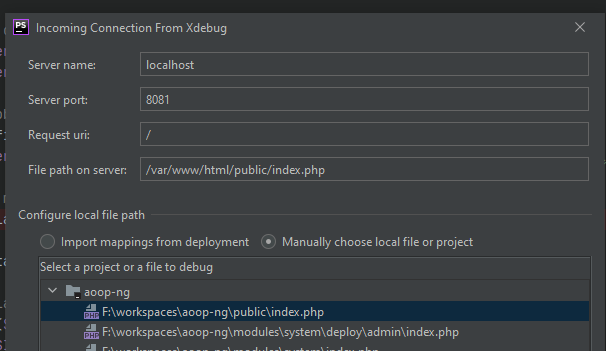
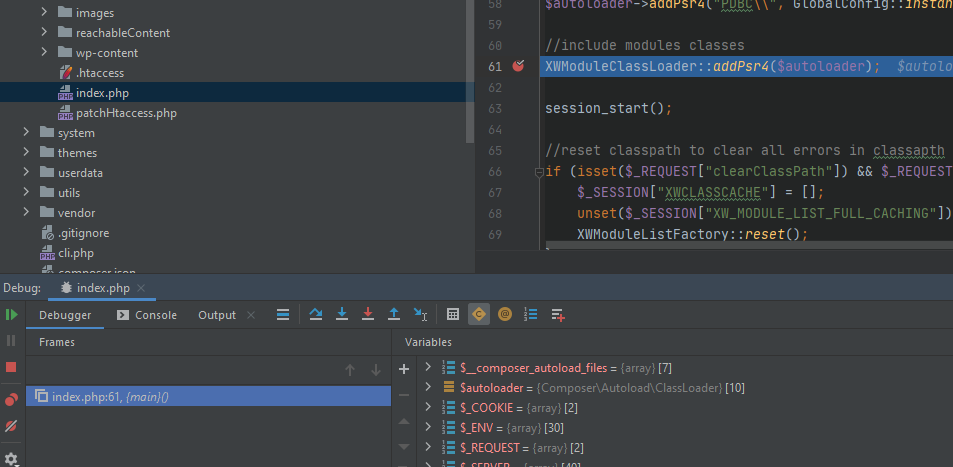
Auf Wunsch hier nochmal eine kleine Anleitung wie man Xdebug in einem Docker-Container zusammen mit PHPStorm verwendet. Ich hatte ja schon eine Anleitung für VSCode geschrieben und dort am Ende angemerkt, dass es mit PHPStorm sehr viel einfacher geht. Vorhin nochmal getestet und es geht sehr viel einfacher.
Aber von Anfang an. Wir müssen erstmal das Docker-Image um Xdebug erweitern:
RUN pecl install xdebug-2.8.0 && docker-php-ext-enable xdebug
RUN echo 'zend_extension="/usr/local/lib/php/extensions/no-debug-non-zts-20151012/xdebug.so"' >> /usr/local/etc/php/php.ini
RUN echo 'xdebug.remote_port=9000' >> /usr/local/etc/php/php.ini
RUN echo 'xdebug.remote_enable=1' >> /usr/local/etc/php/php.ini
RUN echo 'xdebug.remote_host=host.docker.internal' >> /usr/local/etc/php/php.ini
Dann installieren wir uns "Xdebug Helper" für den Chrome oder eben die Kombination aus Addon und Browser, die man gerne hätte.
Dann den Docker-Container starten. Die Seite im Chrome aufrufen und dort das Addon aktivieren. Einen Breakpoint in PHPStorm setzen und PHPStorm auf Debug Eingänge horchen lassen.
F5 im Webbrowser drücken und dann das Mapping bestätigen.
Das wars. Super einfach und schnell (abgesehen vom Docker-Container bauen) eingerichtet.
Ich habe einmal versucht Docker mit der WSL 2 based engine laufen zu lassen. Es war alles extrem langsam und alles dauerte ewig. Vorher lief Docker selbst auf einem langsameren Notebook ganz gut. Das hier beschreibt das Problem sehr genau. Am Ende bin ich auch wieder auf die Hyper-V Engine zurück gewechselt. Meine Daten in das WSL Dateisystem zu kopieren gefiel mir nicht wirklich, weil ich von Windows aus mit PHPStorm darin entwickel. Hyper-V deinstallieren klingt zwar auch interessant und ich könnte Virtual Box wieder verwenden.. aber so ganz traue ich dem nicht.
Manchmal muss man z.B. das Kopieren von Dateien auf einen Server per SCP testen. Oder auch einfache Deployments auf einem Server. Hier ist ein kleines SSH-Server Image mit Bash und Rsync.
FROM sickp/alpine-sshd:7.5
RUN apk update
RUN apk add bash
RUN apk add rsync
Und in einer docker-compose.yml
version: "3.0"
services:
ssh-server:
build: .
ports:
- "2222:22"
User: root
Password: root
Man kann aber auch authorized-keys hinterlegen, wie auf der Seite des Base-Images erklärt wird.
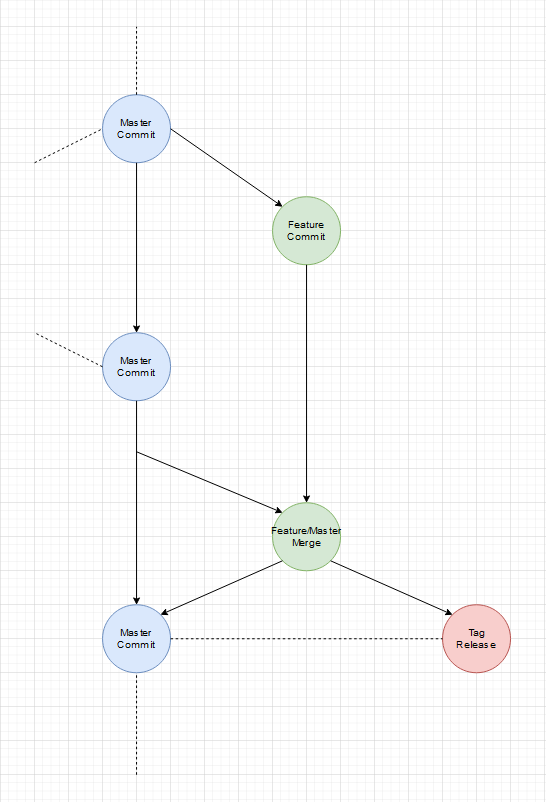
Am Freitag hat mir mein Kollege 2 Links zu Blogposts geschickt, die sich mit der Frage beschäftigen ob Git-Flow in der heutigen Zeit überhaupt noch funktioniert oder ob Git-Flow veraltet ist. Der 1. Blogpost zeigt erstmal nur Probleme auf und enthält keine Lösungen. Es passiert zu leicht das Release-Branches zu lange leben und dann darin selbst Entwicklung geschieht. Es dauert relativ lange bis eine Änderung durch die verschiedenen Branches im Master ankommen und am Schlimmsten ist noch, dass bei parallelen Entwicklungen ein nicht releaster Branch einen anderen aktuelleren, der einfach schneller war, blockiert.
Ja. Das ist jetzt nicht neu. Über diese Probleme habe ich 2009 schon im dem damaligen ERP-Team diskutiert (mein Gott waren wir damals schon modern...). Die Lösung hier ist einfach dass man harte Feature- und Code-Freezes braucht. Auch darf die Fachabteilung nicht erst im Release-Branch das erste Mal die neuen Features sehen. Ich habe es so erlebt. Dann kamen die neuen Anforderungen, Änderungen der gerade erst implementierten Features. Das soll aber so sein. Wenn das so ist braucht man aber auch noch das. Das ist falsch und muss so funktionieren... Alles Dinge die schon viel früher hätten klar sein müssen und erst dann hätte es zu einem Release-Branch kommen dürfen. Der Stand eines Feature-Branchs muss genau so auf einem System für Test und Abnahmen deploybar sein wie ein Release-Branch. Anders gesagt jeder Stand muss einfach immer präsentierbar sein!
Der 2. Blogpost brachte jetzt auch nicht wirklich neue Erkenntnisse, was am Ende der Author auch selbst schreibt.
Ich halte die Darstellung von Branches in parallelen Slots oder Lanes, die in dem Sinne ein Rennen um die Aktualität austragen für vollkommen falsch. Es darf auch nicht den develop-Branch oder den einen Release-Branch geben, der auch dann immer deckungsgleich mit dem Stand des Deployments auf einem System ist. In Zeiten von Docker und Reverse-Proxies zusammen mit Wildcard-Subdomains sind feste Systeme sowie so überholt. Jeder Branch kann ein System haben, auf dem Test, Abnahmen und Dokumentation stattfinden kann.
Das gilt auch für Tags. Branches sind variabel und ändern sich immer wieder. Tags sind statisch und damit perfekt für Zwecke, wo man kontrolliert bestimmte Stände deployen möchte. Tags persitieren einen bestimmten State/Zustand des gesamten Git-Repositories. Branches bilden einen State/Zustand aus der Sicht eines bestimmten Entwicklers oder eines bestimmten Features ab.
Deswegen halte ich feste Branches wie mit festen Aufgaben für komplett falsch. Ein Feature = ein Branch und am Ende steht ein Tag, der den gewünschten State/Zustand persitiert.
Ein einfacher Feature Branch:
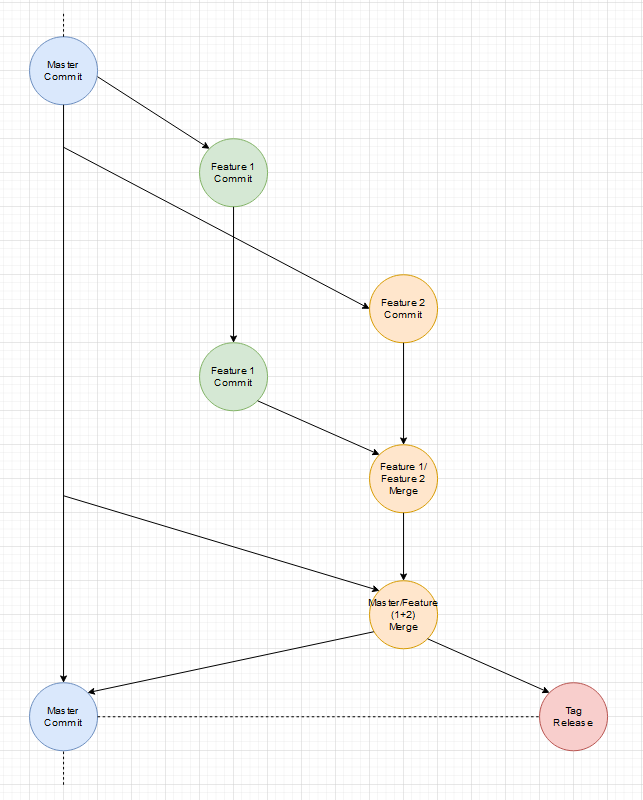
Ja es gibt noch einen Master-Branch, der aber in dem Sinne nur ein 2D Abbild des wilden mehr dimensionallen Feature Raum ist. Wenn wir jeden Feature-Branch als Vektor der auf das einzelne Feature/Tag als Ziel zeigt versteht, ist der Master einfach die Projektion aller Vektoren auf eine Fläche. Diese vereinfachte Projektion hilft Feature-Branches vor dem Release auf den aktuellen Stand (was andere Features und Fixes angeht) zu bringen.
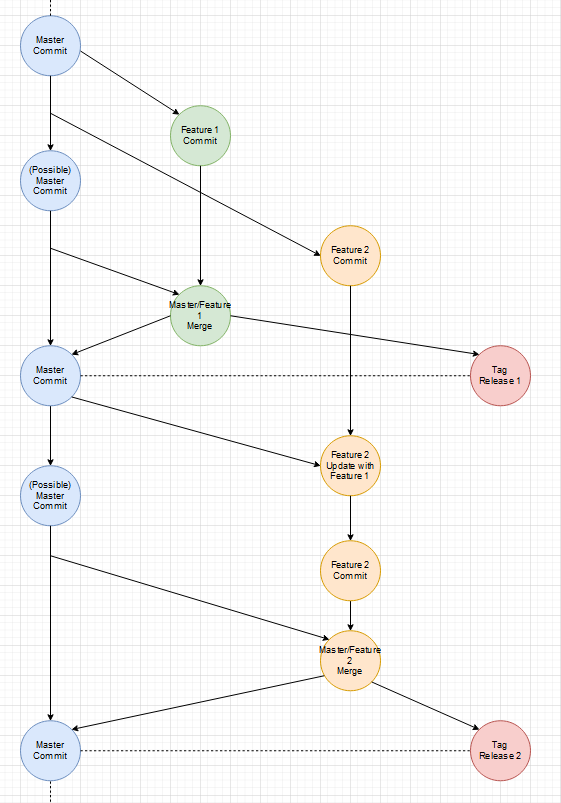
Es gibt auch immer mal Abstimmungsprobleme bei Features, die auf einander aufbauen. Interfaces haben minimale Abweichungen oder ein kleiner Satz in der Dokumentation wurde falsch verstanden. Was also wenn ein Feature doch noch eine kleine Änderung braucht, weil Entwicklungen parallel liefen?
Beides wird gleichzeitig fertig (ein extra Release-Branch wäre möglich):
Das Basis-Feature geht vorher live:
Das bessere und flexiblere Vorgehen
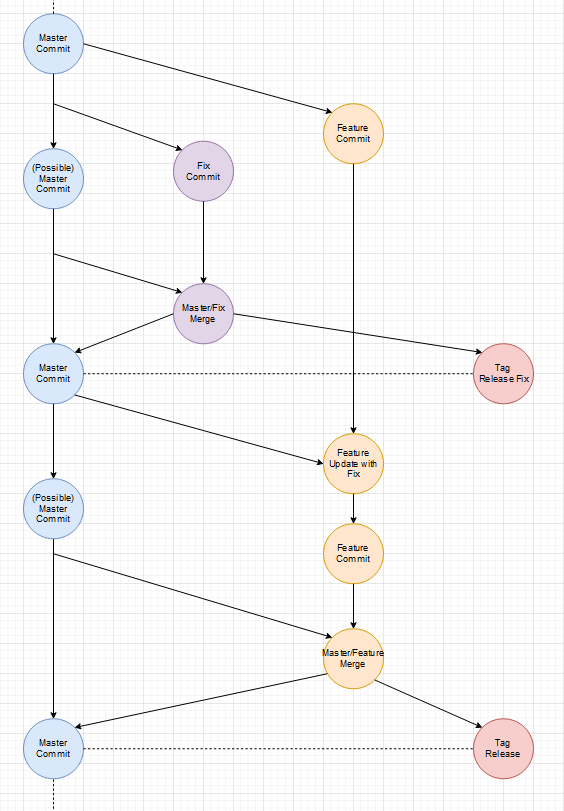
Gibt es einen Unterschied zwischen Fixes und Features? Nein. Beides sind Improvements des aktuellen States/Zustands. Wenn einem in einem Feature-Branch ein allgemeines Problem auffällt, fixt man das Problem und merged den Master mit der neuen Version erneut in den Feature-Branch.
Zwischenzeitlicher Fix:
Es ist an sich kein Unterschied zwischen einem Fix und einen weiteren Feature-Branch, außer dass der Fix-Branch sehr viel kurzlebiger ist und wohl weniger Commits enthält.
Der Master ist immer stable, weil nur Release-Tags darauf abgebildet sind.
Dieses Herangehen macht es sehr einfach jeden State/Zustand auf System abzubilden. Jeder Branch ist unter seinem Namen zu finden und Tags werden nach Typ auf Systeme gemappt.
Tag auf System: - release-XXX auf das produktive System
- staging auf das Staging-System (1:1 Namenabbildung)
- demo1-n auch 1:1 per Namen abbilden
Bei staging muss man den Tag löschen und neu anlegen, so kann jeder Zustand auf dem Staging-System deployt werden oder besser gesagt, wird ein Deployment durchgeführt das dann unter der Staging-Domain erreichbar ist. Hier gibt es eine tolle Anleitung wie man solche Systeme mit Traefik oder Kubernetes ganz einfach bauen kann. Ich werde das aber vielleicht auch noch mal genauer beschreiben, wie ich es für gut halte.
Denn Branches halte ich persönlich es nicht für wert wo anders als lokal in einem Docker-Container zu laufen. Da kann ich um es der Fachabteilung lieber schnell einen Tag erstellen und diesen nach dem Input der Abteilung auch wieder unter selben Namen neu anlegen oder unter einen neuen wenn zwei mögliche Umsetzungen verglichen werden sollen (macht das mal mit Git-Flow!).
Edit: Ich habe die per Hand gezeichneten Diagramme durch vollständigere Diagramme, die per Software erstellt wurden, ausgetauscht.
Wenn man Code-Coverage bei Unittests mit PHP haben will benötigt man extra Erweiterungen, wie z.B. XDebug. XDebug ist aber sehr langsam und deswegen gibt es Alternativen wie PCOV. Wenn man das nun installieren will kann es zu Problemen bei "docker-php-ext-install" auf den offiziellen PHP-Docker-Images kommen. Um es dort zu installieren, muss man
pecl install pcov && docker-php-ext-enable pcov
ausführen. Dann funktioniert die Installation und es steht für Unit-Tests zur Verfügung.
Ich hatte lange Zeit ja ein Postfix mit Dovecot laufen. Hat an sich gut funktioniert, aber es kam viel Spam durch und die Konfiguration und Erweiterung um Spamfilter war kompliziert und umständlich. Ich wollte einfach etwas was ich starten kann, meine Domains und Postfacher eintragen kann und dann alles läuft. Denn wenn es schon so viele Anleitungen gibt, hat doch sicher so etwas schon fertig als Docker-Image haben.
Am Ende bin ich bei poste.io gelandet. Dass kann man einfach mit einigen Angaben starten und es läuft dann einfach. Schnell und stabil, wie es sich wünscht. Man kann ganz einfach Weiterleitungen und eigene Postfächer für alle seine Domains anlegen und kann auch direkt mit Roundcube einen kleinen Webmailer-Service bauen. Das habe ich aber nicht gemacht.
Auf habe ich es nicht zusammen mit Traefik laufen, sondern allein auf eigenen Ports. Es soll eben allein für mich meine Weiterleitungen erledigen und dabei nicht so Spam-empfindlich sein.
Dazu kann ich sagen, dass der Spam-Filter wirklich gut funktioniert.
Ich hatte viel rumprobiert und bin mit diesem Start-Script ganz zufrieden:
Um die Traefik Labels einzubauen hat man ja die Wahl diese im Image zu haben oder im Container. Während man die dem Container beim Starten geben kann, muss man die für das Image beim Build-Process schon haben. Ich benutze beides und muss sagen, dass ich an sich dafür bin die dem Container zu geben. Aber falls man sich mal fragt wie man dynamische Labels dem Image geben kann... ARG ist das Geheimnis.
Wenn ich nun eine dynamische Subdomain haben will:
FROM httpd:2.4
ARG subdomain
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:$subdomain.example.com
Hier kann man dann auch auf ENV-Variablen zurück greifen und die weiter durch reichen. Was sehr praktisch ist, wenn man sich in einem Gitlab-CI Job befindet.
Nachdem ich meine wichtigsten Projekte in Docker-Container verfrachtet hatte und diese mit Traefik (1.7) als Reserve-Proxy seit Anfang des Jahres stabil laufen, war die Frage, was ich mit den ganzen anderen Domains mache, die nicht mehr oder noch nicht produktiv benutzt werden.
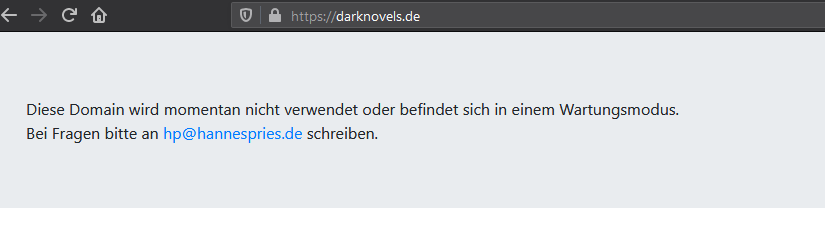
Ich hatte die Idee einen kleinen Docker-Container laufen zu lassen, auf den alle geparkten Domains zeigen und der nur eine kleine Info-Seite ausliefert. Weil das Projekt so schön übersichtlich ist und ich gerne schnell und einfach neue Domains hinzufügen will, ohne dann immer Container selbst stoppen und starten zu müssen, habe ich mich dazu entschieden hier mit Gitlab-CI ein automatisches Deployment zubauen. Mein Plan war es ein Dockerfile zu haben, das mir das Image baut und bei dem per Label auch die Domains schon angegeben sind, die der Container bedienen soll. Wenn ich einen neuen Tag setze soll dieser das passende Image bauen und auf meinem Server deployen. Ich brauche dann also nur noch eine Datei anpassen und der Rest läuft automatisch.
Dafür habe ich mir dann extra einen Gitlab-Account angelegt. Man hat da alles was man braucht und 2000 Minuten auf Shared-Runnern. Mehr als genug für meine Zwecke.
Ich habe also eine index.html und ein sehr einfaches Dockerfile (docker/Dockerfile):
FROM httpd:2.4
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:darknovels.de,www.darknovels.de
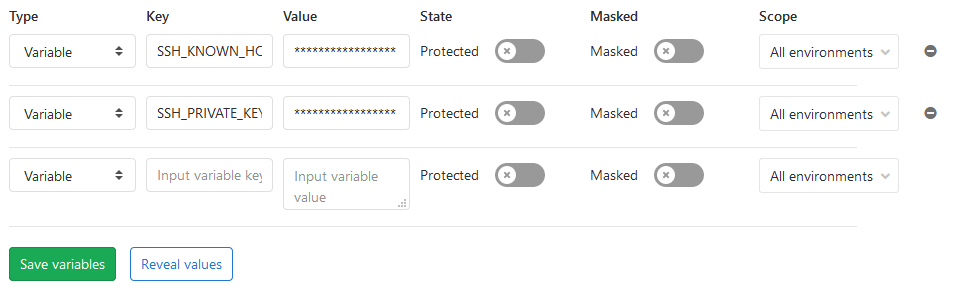
Das wird dann also in einen Job gebaut und in einem nach gelagerten auf dem Server deployed. Dafür braucht man einmal einen User auf dem Server und 2 Variablen in Gitlab für den Runner.
Dann erzeugt man sich für den User einen Key (ohne Passphrase):
su dockerupload
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
exit
Vielleicht muss man da noch die /etc/ssh/sshd_config editieren, damit die authorized_keys-Datei verwendet wird.
Den Private-Key einmal kopieren und in SSH_PRIVATE_KEY unter Settings - CI /DI - Variables speichern. Damit wir uns sicher vor Angriffen verbinden können müssen wir noch den Server zu den bekannten Hosts hinzufügen. Den Inhalt von known_hosts bekommt man durch:
ssh-keyscan myserver.com
Einfach den gesamten Output kopieren und in den Gitlab Variablen unter SSH_KNOWN_HOSTS speichern. Nun hat man alles was man braucht.
Seit heute laufen die meisten meiner Homepages als Docker-Container mit Traefik als Reserve-Proxy. Es war teilweise ein sehr harter Kampf mit vielen kleinen Fehlern. Wenn man sauber von vorne anfängt sollten weniger Fehler auftreten.
Was man beachten sollte:
- Images müssen Port 80 exposen
- HTTPS-Umleitungen aus htaccess-Dateien entfernen (Traefik kümmert sich darum)
- Datenbanken über Adminer oder PHPMyAdmin initialisieren und nicht über init-Scripte
- Man braucht ein eigenes Netzwerk in Docker wie "web"
- traefik.frontend.rule und traefik.enable reichen als Tags
- man macht vieles ungesichert während des Setups, dass muss man später alles wieder absichern (die Traefik-UI/API!)
- Immer Versionen für die Images angeben und nie LATEST (sonst hat man plötzlich neue Probleme)
Ich habe noch Traefik 1.7 laufen, aber das funktioniert so weit sehr gut und es gibt viele Hilfen. Für 2.0 gibt noch nicht so viele Hilfen und Beispiele. Für jeden Container habe ich auch ein eigenes Dockerfile, damit man da kleine Modifikationen an den Images machen (auch wenn es nur mal zum Testen ist).
Emails laufen nun alle über poste.io der unabhängig von Traefik läuft und einen eigenen Port für die Web-UI nutzt. Das Setup ging schneller und läuft schon seit einigen Wochen extrem stabil und filtert Spam sehr viel besser als meine vorherige selbst gebaute Lösung.
Es wird mal Zeit sich der Zukunft zu zuwenden und nicht mehr in der Vergangenheit zu leben. Deswegen werde ich endlich mal alle meine Seiten und Projekte in Docker-Container verfrachten und mit Traefik meinen Server neu strukturieren. Deswegen kann es im Dezember bei meinem Blog und MP4toGIF.com zu längeren Downzeiten im Dezember kommen. Ich überlege auch einen günstigen zweiten Server nur für Emails zu nehmen.
Das ganze sollte mir dann auch die Möglichkeiten geben spontan mal andere Dienste zu deployen. Im Kopf habe ich da so:
* Passbolt (als Ersatz für KeePasssXC)
* nextCloud um von OneDrive weg zu kommen
* und vielleicht Satis um meine PHP-Libs zu bündeln
Ich hoffe mal, dass alles ganz einfach und super funktioniert :-)
Es war ein harter Kampf.. aber ich war siegreich. Nachdem ich durch den Wechsel meines Arbeitgebers auch den Zugriff auf Intellij + PHP-Plugin einbüßen musste, bin ich jetzt vollständig auf VSCode gewechselt.
Wie ich XDebug + VSCode + Docker zum Laufen bekommen habe.
Dockerfile (nur der wichtige Teil):
RUN pecl install xdebug-2.8.0 && docker-php-ext-enable xdebug
RUN echo 'zend_extension="/usr/local/lib/php/extensions/no-debug-non-zts-20151012/xdebug.so"' >> /usr/local/etc/php/php.ini
RUN echo 'xdebug.remote_port=9000' >> /usr/local/etc/php/php.ini
RUN echo 'xdebug.remote_enable=1' >> /usr/local/etc/php/php.ini
RUN echo 'xdebug.remote_host=host.docker.internal' >> /usr/local/etc/php/php.ini
Lokale php.ini (ich habe 2.8.0 herunter geladen und als php_xdebug.dll gespeichert):
Manchmal muss den Upload von Dateien testen. Nicht immer nutzt man etwas wie S3 sondern oft auch noch ganz klassische Umgebungen mit SCP oder sFTP. Wenn man schnell und unkompliziert den Upload auf einen sFTP-Server testen will, kann sich so einen ganz schnell und einfach mit Docker erzeugen.
docker run -p 2222:22 -d atmoz/sftp foo:pass:::upload
man kann sich dann auf localhost:2222 mit dem Benutzer foo und dem Passwort pass verbinden. Für Dateien steht das Upload-Verzeichnis bereit. Wenn man ihn nicht mehr braucht, wirft man den Container einfach weg und kann das nächste mal sauber mit einem neuen starten.
Der einfachste Weg einen Shopware Shop zuinstallieren war immer, die ZIP-Datei mit dem Webinstaller downzuloaden und diese in das gewünschte Verzeichnis zu entpacken. Dann die URL aufrufen und dem Installer folgen. Das ist für automatische Deployments nicht so toll und oft wurde dort einfach die Git-Version verwendet. Die hat den extremen Nachteil, dass diese unglaublich viele Dinge mitbringt, die in einer produktiven Umgebung nichts zu suchen haben. Buildscripte, Tests, etc bringen einen wirklich nur in der Dev-Umgebung was und sollten in der produktiven Umgebung nicht mit rumliegen, weil je mehr rumliegt, desto mehr Sicherheitslücken oder ungewollte Probleme könnten mitkommen.
Seit einiger Zeit kann man Shopware aber auch sehr einfach über den Composer installieren. Dabei wird eine eher moderne Verzeichnisstruktur angelegt und auch die Basis-Konfiguration kann einfach über Env-Variablen gesetzt werden, so dass ein automatisches Deployment für einen Server damit sehr einfach wird. Im Idealfall hat man die Datenbank schon sauber und fertig vorliegen. Dann erspart man sich fast den gesamten Installationsprozess und kann direkt loslegen.
Wenn man den Composer noch nicht installiert hat, muss man diesen kurz installieren:
<Directory /var/www/your_webshop>
AllowOverride All
Require all granted
</Directory>
RewriteEngine On
</Virtualhost>
Reload des Apache und schon kann es an sich losgehen. Wenn man sehen möchte wie die DATABASE_URL verarbeitet wird, kann man einen Blick in die etwas komplexer gewordene config.php werfen die man nun unter your_webshop/app/config/config.php findet.
Sollte man noch keine fertige Datenbank auf dem Server liegen haben, muss man die ./app/bin/install.sh ausführen. Gerade für mehrere automatische Deployments, würde ich aber die Datenbank einmal local auf meiner Workstation anlegen und mit Default-Werten befüllen. Diese kommt dann auf den Datebankserver und wird beim deployment, mit den spezifischen Daten wie den Shopdaten und Admin-Zugängen versehen.
Natürlich würden Updates auch über den Composer laufen, wobei sw:migration:migrate automatisch mit aufgerufen wird, um die Datenbank mit aktuell zu halten. Das Verhalten kann man über die Deaktivierung des entsprechenden Hooks in der composer.json verhindern (aber das macht an sich nur in Cluster-Umgebungen Sinn). Ein Update über das Webinstaller-Plugin würde Probleme bereiten und sollte, wenn man es dann ,z.B. weil man eine alte Installation umgezogen hat, installiert und aktiv hat mit ./bin/console sw:plugin:uninstall SwagUpdate entfernen.
Der wirkliche Vorteil liegt jetzt darin, dass man in die composer.json seine Git-Repositories von den Plugins mit eintragen kann und die Plugins direkt über den Composer installieren und updaten kann. Man muss also nicht diese erst vom Server downloaden + entpacken oder per Git clonen (wo dann wieder viel Overhead mit rüber kommen würde).
Es kann dazu kommen, dass beim Aufruf der console von Shopware 5 keine kernel.environment gesetzt ist. Bei Webserver Aufrufen wird diese ja zumeist in der conf des Apache gesetzt.
Um jetzt die Environment (z.B. "production") direkt beim Aufruf der console zu setzen muss man die Option "e" setzen und schon geht alles.
Manchmal hat man einfach Scripts von anderen, die mit einem Fehlercode beendet werden und es ist vollkommen ok. Leider bricht bei so einem Fehler dann der Build-Process vom Docker-Image ab. Deswegen muss man den Fehlercode überschreiben.
RUN composer create-project shopware/composer-project my_shop --no-interaction --stability=dev; exit 0
Damit wird der Fehler wegen fehlender .env-Datei übergangen. Da man diese Datei an sich auch nicht braucht.
Mit Docker-Compose kann man sich einfach eine MinIO-Instanz erzeugen und auch gleich benötigte Buckets erstellen, so dass man das Erzeugen der Buckets nicht im Code der Anwendung erledigen muss.
Danach sollte auf localhost:8000 der Shop starten.. wenn eine MySQL Auth.-Method Fehlermeldung kommt hilft die Container zu beenden. In der Docker-Compose das DB-Image von dem MySQL-Image auf das MariaDB-Image zu ändern und noch mal die Container neu zustarten und ein wieder install durchführen.
Dann sollte alles laufen und man kann sich unter localhost:8000/admin mit admin - shopware anmelden.
Wenn man die lokalen psh.phar-Aufrufe durch die direkten Docker-Befehle ersetzt, sollte es auch unter Windows funktionieren. Innerhalb des Containers kann man natürlich wieder psh.phar verwenden.
Update: manchaml kann auch helfen, dieses vorher einmal auszuführen, bevor man den Container startet und dort install aufruft:
Amazon S3 ist ein einfacher Key-Value Store, wo man auch sehr große Daten unterbringen kann. Gerade wenn man Dateien nicht auf dem selben Server speichern möchte oder ein Cluster betreiben will, ist S3 eine gute Alternative zu FTP oder NFS-Laufwerken. Der Server ist über HTTP zu erreichen und es gibt für alle möglichen Sprachen Clients. Eine S3 kompatible Implementierung ist MinIO. Ich hab hier ein kleines Beispiel gebaut, wo ich ein Bild hochlade und wieder downloade und danach alles auch wieder aufräume. Metadata habe ich auch genutzt. Wenn man komplexere Anwendungen hat wird man wohl eher nicht SaveAs verwenden sondern den mitgelieferten Stream aus dem Array verwenden.
Das Minio Docker-Image:
sudo docker pull minio/minio
sudo docker run -p 9080:9000 -e "MINIO_ACCESS_KEY=AKIAIOSFODNN7EXAMPLE" -e "MINIO_SECRET_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY" minio/minio server /data
Wer kennt das Problem nicht? Der Java-Appserver ist schon beim hochfahren, während der DB-Server noch Daten importiert und Hibernate fängt an wild Exceptions zu werfen.
Die Lösung ist das Script wait-for-it, das einfach wartet, bis ein Server auf einem bestimmten Port erreichbar ist.
FROM openjdk:12-alpine
RUN apk add --no-cache bash
ADD utils/wait-for-it.sh /wait-for-it.sh
RUN chmod +x /wait-for-it.sh
Die Scripts basieren auf dieser Anleitung von DigitalOcean.
Mit diesem Script werden der Master und alle Tags als Docker-Image gebaut, wobei der Master dann auch als latest-Tag abgelegt wird. D.h. der Master muss immer stable sein.. bei jedem Commit.
Alternative kann man auch sich auf verschiedene Tags-Notationen einigen, wobei nur die Tags als latest getaggt werden, wenn diese ein release-Tag sind. Hier muss man aufpassen, falls man eine alte Version
nachträglich einpflegen will.
Wer sich sonst immer für Wildfly/Tomcat und JAX-RS für seine REST-API Lösungen entschieden hat wird sich mit Apache Meecrowave sehr schnell zu Hause fühlen. Im Grunde ist es auch nichts anderes als ein Tomcat mit JAX-RS nur dass die Setup-Phase fast komplett entfällt. Für Microservices und schnelle Lösungen hat man in wenigen Minuten eine funktionsfähige REST-API.
Für eine einfache REST-API braucht man die pom.xml, eine Klasse mit einer Main-Methode und einen REST-Endpoint.
@Path("test")
@ApplicationScoped
public class TestController {
@GET
@Produces(MediaType.APPLICATION_JSON)
public TestModel action(){
TestModel model = new TestModel();
model.setId(23);
model.setName("Test");
return model;
}
}
Der Endpoint ist jetzt erreichbar:
http://localhost:8080/test
Der Vorteil bei dieser Lösung ist, dass man sehr einfach ein Docker-Image mit dieser Anwendung erstellen kann, das man dann direkt deployen kann.
Durch das Meecrowave-Maven-Plugin wird eine meecrowave-meecrowave-distribution.zip im Target-Verzeichnis erstellt.
RUN apk --no-cache add bash
EXPOSE 8080
ENTRYPOINT["sh /app/meecrowave.sh start"]
Auch für Test gibt fertige Meecrowave-Packages, die man nutzen kann. Sonst geht natürlich auch einfach JUnit.
Wer sich jetzt fragt ob Spring Boot besser oder schlechter ist.. ich hatte jetzt mit beiden zu tun und am Ende ist beides an sich das Selbe mit ein jeweils anderen Libs. Beides ist für Microservices sehr gut geeignet.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: