Viele erinnern sich noch an Zeiten, wo man direkt auf einem Webserver seinen HTML-Seiten und Scripts geschrieben und getestet hat. HTML ging meistens schon lokal, aber wenn es um PHP oder anderes ging brauchte man einen Server. Dann schwenkte man auf XAMPP um, wo man einen lokalen Apache nutze. Linux brachte den Apache und PHP direkt mit. Aber man hatte oft kein Linux und half sich mit VirtualPC oder VirtualBox, so man entweder eine shared Speicher hatte oder ganz klassisch per FTP oder später SCP/SSH seine Dateien aus der IDE ins Zielsystem bekam. Dann kam Docker und die Welt wurde gut.. über all gut? Nein, dann erstaunlich viele gerade im Agentur-Bereich arbeiten immer noch mit einem Server und einem FTP-Sync. Gut heute oft mit SFTP oder SCP, aber ohne Docker oder lokalen Webserver.
Während ich klassische vServer mit Apache und ohne Reverse-Proxy und Docker für veraltet halte, sind sie noch öfter Realität als Docker-/K8n-Umgebungen. Selbst shared-Hosting für produktive Umgebungen sind noch öfters anzutreffen.
Nach einem Gespräch, wo noch direkt auf dem Server gearbeitet wurde und nicht mal eine lokale IDE einen Sync in Richtung Server vornahm sondern direkt die Datei vom Server aus geöffnet wurde (da kann man fast direkt mit vi auf dem Server arbeiten...), hier eine einfache kostenlose Lösung, wo man wenigstens die Dateien lokal hat und so auch ohne Probleme mit Git arbeiten kann.
Genutzt wird VisualStudio Code (die Intellij-IDEs bringen so einen Sync direkt von Haus aus mit, kosten aber in den meisten Varianten Geld).
Ein Plugin installieren:
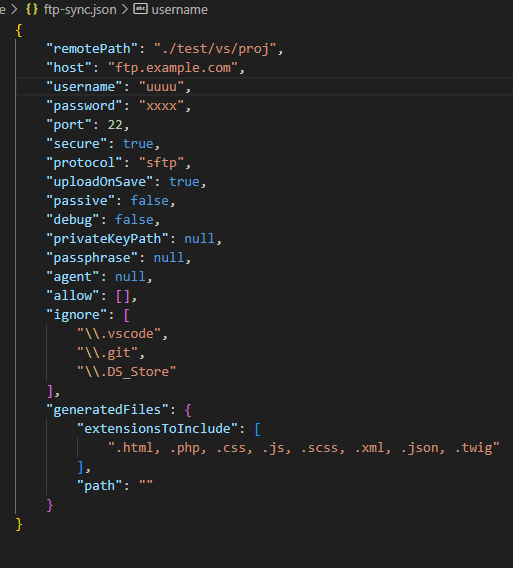
FTP-Config anlegen (wird geöffnet nach dem ersten Sync-Versuch):
Wenn uploadOnSave aktiviert ist am Besten die IDE noch mal neustarten.
Geht auf jeden Fall besser als WinSCP parallel zum Sync laufen zu lassen.
Würde ich so entwickeln wollen? Nein. Besonders wenn mehr als ein Entwickler an einem Projekt arbeiten, geht nichts über Docker. Für Shopware habe ich gute Images oder man nimmt Dockware, was gerade für Entwickler an sich vollkommen reicht.
Update meiner Shopware Docker Umgebung. Funktioniert mit 6.4. An 6.5 arbeite ich noch. Es ist Imagick installiert, um z.B. automatisch beim Upload von PDFs die erste Seite als JPG zu speichern und in einem CustomField als Vorschau zu verlinken.
RUN docker-php-ext-install dom \
&& docker-php-ext-install pdo \
&& docker-php-ext-install pdo_mysql \
&& docker-php-ext-install curl \
&& docker-php-ext-install zip \
&& docker-php-ext-install intl \
&& docker-php-ext-install xml \
&& docker-php-ext-install xsl \
&& docker-php-ext-install fileinfo
RUN mkdir -p /usr/src/php/ext/imagick
RUN curl -fsSL https://github.com/Imagick/imagick/archive/06116aa24b76edaf6b1693198f79e6c295eda8a9.tar.gz | tar xvz -C "/usr/src/php/ext/imagick" --strip 1
RUN docker-php-ext-install imagick
RUN echo 'memory_limit = 512M' >> /usr/local/etc/php/php.ini
RUN a2enmod rewrite
RUN php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
RUN php composer-setup.php --2.2 #there are problem
RUN mv composer.phar /usr/local/bin/composer
# copy conf-file to /etc/apache2/sites-enabled/000-default.conf
RUN mkdir /files;
COPY ./setup.sh /files/setup.sh
ENTRYPOINT ["sh", "/files/setup.sh"]
Ich arbeite nun doch schon einige Zeit mit Shopware 6. Während ich am Anfang vielen Konzepten etwas kritisch gegenüberstand, bin ich nun doch sehr von fast allen Dingen überzeugt. Ich habe viele verschiedene Dinge schon mit Shopware 6 realisiert und einiges wäre in Shopware 5 nicht so einfach gewesen.
Gerade Vue.js in der Administration ohne irgendwelche zusätzlichen Lizenzen nutzen zu können ist super. Ich mochte immer Vue + Bootstrap und Symfony. Also am Ende fühle ich mich so was von extrem in meinen Vorlieben bestätigt... wenn auch Shopware diese Kombinationen nutzt muss ich ja schon immer richtig gelegen haben :-)
Varianten sind immer noch viel zu kompliziert. Daten in das Model für Emails rein zubekommen ist wirklich viel zu umständlich. N:M Relation in DAL ist umständlich bzw wie früher mit puren SQL. Entweder alles vorher löschen oder sich merken was genutzt wird und alles was nicht dazugehört löschen. Aber am Ende kommt man ja gut damit klar... ist eben wie mit JDBC oder PDO direkt zu arbeiten und dass habe ich lange genug gemacht.
So.. aber was kann man alles mit Shopware 6 so alles bauen? Ich habe bis jetzt nur für Kunden direkt entwickelt und falls jemand etwas hier von gerne hätte, geht das leider nur über Anfrage und dann wird ein Angebot erstellt.
1. Adressänderungen verhindern Wie schon bei Shopware 5 war es nötig, weil SAP sonst überfordert ist.
2. Register-Form erweitern Das zu Erweitern war am Ende sehr viel einfacher als gedacht und ich nutzt einfach das Data-Mapping Event für den Customer. Der richtige Weg? Für mich funktioniert er gut.
3. Blog Einträge Das kostenlose Blog-Plugin ist schon echt super. Es fehlt nur ein Flag um Posts von er Suche auszuschließen, Typen, Rechte über Rules und Datei-Anhänge. Ja.. ich weiß.. ich könnte mich da beteiligen und alles einbauen.. sollte ich wirklich machen. Aber bis jetzt war nur Zeit das Plugin zu erweitern um Rezepte aus einem Panipro-System zu importieren.
Typen sind natürlich dynamisch und es werden nur Typen auf der linken Seite angezeigt, die auch gefunden wurden.
4. Bonuspunkte und passende Produkte Produkte die man nur oder auch gegen Bonuspunkte kaufen kann. Das war etwas komplexer und man musste über Collector und Processor des Carts eingreifen. Heute würde ich wohl einiges ein wenig anders machen, aber nicht viel und auch nur minimale Änderungen.
5. Konfigurator Style #1 So kann man sich z.B. Geschenkkörbe oder PCs/Notebooks konfigurieren. In der Administration kann man sich ein Config-Preset anlegen und es verschiedenen Products zuordnen.
6. Konfigurator Style #2 Ein Produkt das z.B. Hackfleisch beinhaltet so konfigurieren in welchen Formen man das Hack gerne geliefert bekommen würde. Wurde als Teil von Punkt 7 entwickelt.
7. Paket verkauf Erst alle Pakete verkaufen und dann erst das Tier schlachten. Spart Lagerkosten und andere Aufwände. Hier habe ich gelernt warum Varianten noch immer umständlich sind und CustomFields zu syncen zwischen Varianten schlechter ist als eine eigene Entity dafür zu erstellen. Aber die Anforderungen waren zuerst so das CustomFields die einfacher Lösung waren.
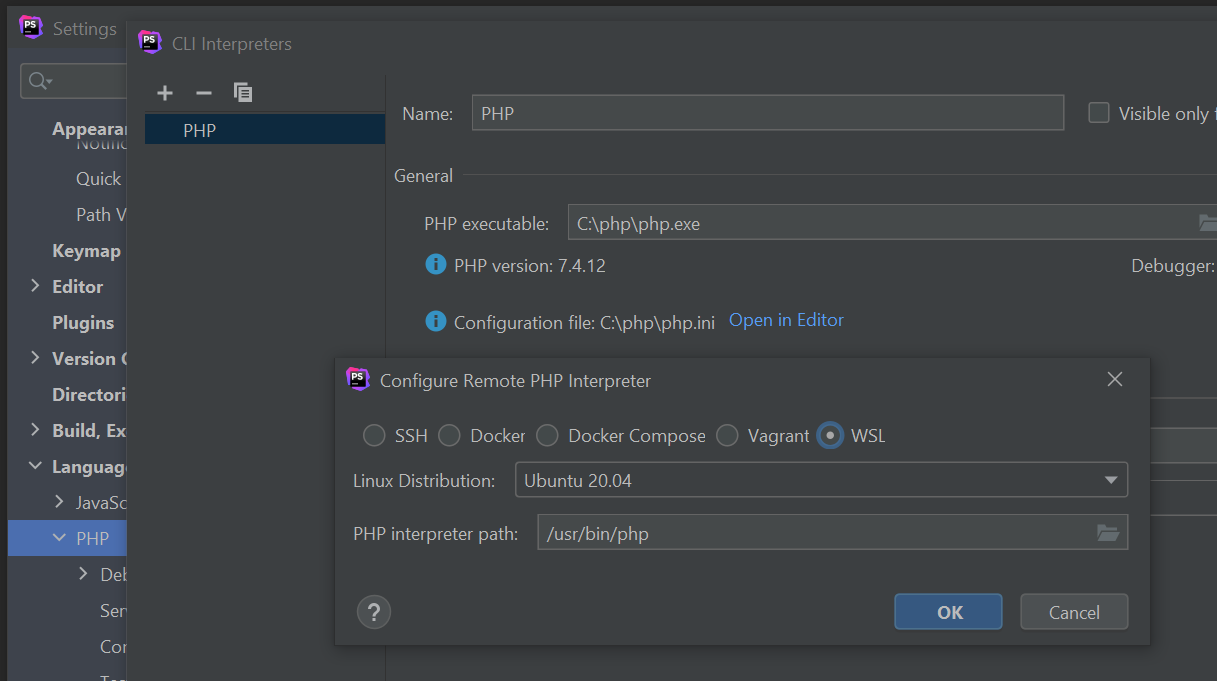
Wenn man mit Windows arbeitet und dort PHPStorm nutzt hat man oft im Terminal die Bash offen, um die unter Windows geschriebenen PHP-Script unter WSL laufen zu lassen.
Aber Jetbrains war ja schlau und hat direkt in PHPStorm eingebaut die PHP-Runtime aus WSL als CLI-Rutime nutzen zu können. Genauso wie man eine Runtime nutzen kann die in einem Docker-Container läuft.
Diese einzurichten ist auch in einem Bild erklärt (wie man PHP unter Linux installiert wird ja an sich jedem PHP-Entwickler klar sein...).
Wie sollen Commit-Messages aussehen? Es gibt viele gute und durchdachte Konzepte dazu.
* Einfache mit wenig Formalitäten
* Sehr umfassende, die zur automatischen Generierung von Changelogs taugen
Aber man sollte sich auch klar machen, dass diese Commit-Messages nur bei Merge Commits zum tragen kommen. Wenn man in einem Branch ist commitet man häufig (mindestens einmal am Tag) und oft auch WIP Stände. Vieles was man commited ist ungetestet und enthält noch Fehler. Am Ende macht man alles noch mal hübsch und schreibt die README.
Also hier braucht es weder "feat" noch "fix" Prefixes. Was ist insgesamt ist, sagt ja schon der Branch. Wie es innerhalb des Branches aussieht interessiert nur 1-2 Entwickler. Die Commit-Message des Merges ist interessant und da braucht man an sich keine Message aus der man ein Changelog-Eintrag erzeugen kann sondern direkt einen Changelog-Eintrag. Also macht es sich an sich mehr Sinn über das Changelog, Versionierung und Change-Dokumentierung Gedanken zu machen. Ein Template für Merge-Commits wird da schon von alleine mit abfallen.
"clean up code" und "fixes while testing" sind im Branch also voll OK.
Irgendwann kommt es in jeder Firma zu dem Zeitpunkt an dem über Werte, Qualität gesprochen wird und wie man diese selbst leben kann. Bei allen die direkten Kundenkontakt haben ist es immer einfach: Nett sein, schnell helfen und auf die Bedürfnisse der Kunden eingehen. Bei einem Entwickler der vielleicht sogar nur Backend-Services für Firmen internen Software schreibt, ist es weniger einfach zu definieren, wie man die Werte leben soll und wie Qualität erzeugt werden kann.
Als erstes: Was ist ein Software Entwickler eigentlich? Dabei ist es glaube ich falsch sich auf die Tätigkeit zu beschränken. Viel mehr geht es um den Zweck. Software hat keinen Selbstzweck. Software ist nicht da, weil sie Software ist. Jede Software hat einen Zweck und dieser Zweck ist gerade im Firmenumfeld ein Problem zu lösen. Wenn alles schon perfekt wäre bräuchte man keine neue Software und keine Entwickler mehr. Der beste Entwickler ist der, der sich durch seine Software selbst überflüssig macht.
Software ist dabei auch nicht die Lösung, sondern das Werkzeug um zur Lösung zu kommen. Ein Software-Entwickler entwickelt Lösungen, die mit Hilfe von Software herbei geführt werden.
Wenn wir das Einhalten der Werte und der Qualität (was Qualität ist nicht zu diskutieren, sondern in den ISO-Normen festgelegt!) als die großen Probleme der Firma sehen, ist die Software natürlich nicht die Lösung, weil keine Firma 100% automatisiert ist. Wir müssen hier in Schichten denken. Für die Mitarbeiter, die Kundenkontakt haben oder die Produkte für die Kunden verwalten ist unsere Lösung deren Werkzeug. Wir lösen das Problem, das besteht, dass die ein größeres und abstrakteres Problem lösen können. Das macht die Software nicht weniger bedeutend, denn die Basis muss stimmen, damit die großen Probleme überhaupt bewältigt werden können. Der Software-Entwickler ermöglicht es dem anderen Mitarbeiter erst effektiv arbeiten zu können.
Jetzt mal konkreter, damit man sich nicht anfängt dabei m Kreis zu drehen. Welche Werte sollte ein Entwickler bei seiner Software anwenden, damit z.B. ein Mitarbeiter im Kundensupport seinen Job gut erledigen kann und der Kunde am Ende zufrieden und sicher verstanden fühlt?
Der Mitarbeiter sollte schnell alle Kundendaten sehen und bei Abfragen, sollte das System nicht einfach warten, sondern eine Meldung ausgeben, die der Mitarbeiter dem Kunden auch mitteilen kann, damit Wartezeiten erklärbar werden. Aber an sich sollte dieses nie nötig sein, weil Antwortzeiten immer verlässlich sind. Nennen wir diesen Wert der Software "responsive".
Fehler sind menschlich und unter Stress unvermeidbar und häufig. Wenn ein Kunde berechtigt oder unberechtigt Druck macht und etwas schnell gehen soll, sollte bei Fehlern immer eine brauchbare Fehlermeldung kommen oder auch versucht werden möglichst viel automatisch zu korrigieren. Niemals sollte wegen einer formal ungültigen ein Formular abstürzen, nicht funktionieren oder es erzwingen Daten erneut eingeben und damit erneut vom Kunden erfragen zu müssen. Wenn man zum dritten mal nach seiner Telefonnummer gefragt wird, wird das Benutzererlebnis echt schlecht. Nenne wir diesen Wert der Software "widerstandsfähig" oder "resilient".
Wenn Fehler in Systemen auftreten, kommen meistens viele Kundenanfragen auf einmal. Keiner will hören, dass es heute etwas länger alles dauert, weil das System durch die vielen Anfragen langsam ist. Gerade bei Sonderangeboten und überlasteten Systemen kann es sehr negativ auffallen, wenn ein Kunde etwas nicht bekommt, weil das System plötzlich nicht mehr reagiert. Systeme sollten sich schnell anpassen.
Wenn nun plötzlich 100 Kunden anstelle von 10 Kunden bedient werden müssen.. dann sollte alles noch genau so schnell und stabil sein wie sonst. Nennen wir diesen Wert der Software "elastisch", weil es flexibel Resourcen nutzen kann, wenn nötig.
Diese drei Werte kann man sehr gut auf die Meta-Begriff: Schnell, Kompetent und Zuverlässig übertragen.
Bestimmt kommen diese drei "Werte" den meisten schon aus dem Reactive Manifesto bekannt vor. Ich finde dieses orientiert sich so sehr an der alltäglichen Realität, dass es sich die Ansätze mehr als einfach nur ein Idee für gute Software-Systeme sind. An sich lässt sich damit alles beschreiben, wo Kommunikation stattfindet.
Dann gibt es noch so Werte, die an sich keine Werte sondern Selbstverständiglichkeiten oder auch gesetzliche Vorgaben sind. Z.B. Freundlichkeit. Egal ob eine andere Abteilung, ein Kollege oder ein Kunde eine Frage oder ein Problem hat, ist man freundlich. Niemand will nerven oder versteht Erklärungen aus Vorsatz nicht. Man muss natürlich auch bestimmend sein, wenn man z.B. an wichtigen Dingen sitzt und die Anfrage von der Priorität niedrig ist. Erklären und eine feste Zeit oder Einordnung geben. Man kümmert sich und der andere fühlt sich verstanden. Das ist auch Freundlichkeit.. und kompetentes Auftreten.
Und dann gibt es Datenschutz. Ist das ein Wert? Es ist gesetzlich vorgeschrieben. Ich glaube es sollte doch als Wert geführt werden, weil man sollte es leben und nicht nur ausführen, weil man es muss. Es macht alles einfacher, wenn Datenschutz gleich mit einfließt und nicht von einer anderen Abteilung später erzwungen wird. Don't be evil ist immer ein guter Ansatz!
Ich hoffe damit hab ich ein paar Ansätze und Denkanstöße geben können, womit ein Entwickler beim nächsten mal, wenn er nach Werten und Qualität gefragt, ein kleines Set an Werkzeugen an der Hand hat, um die Frage schneller beantworten zu können.
Ich halte Release-Branches für sehr problematisch. Manchmal können sie nützlich sein, aber in 99% aller Fälle sind sie überflüssig und bringen mehr Probleme mit sich. Nur wenn wirklich mehrere von einander abhängige Features gleichzeitig entwickelt werden wäre ein Release-Branch denkbar. Ob der dann auch wirklich einen Vorteil bringt, muss jeder dann für sich entscheiden.
Das Problem bei Release-Branches ist, dass alles was release-bereit ist auch da rein kommt. Schnell hat man das Problem, dass man seinen kleinen Fix da rein merged und feststellt, dass 3 weitere Features da drin liegen. Sie sind ja release-bereit, aber ein Release war noch nicht wirklich nötig. Entweder ändern die was, wo man die Benutzer noch instruieren muss oder sie sind nicht so wichtig man hat den Release auf den Ende des Sprints geschoben. Jetzt steht man da und muss erst mal von allen anderen die Info einholen, ob man die Features mit seinem Fix mit releasen kann oder man jetzt doch einen eigenen
Release-Branch aufmachen sollte.
Bloß weil etwas release-fertig ist, heißt es nicht dass ein Release möglich ist!
Die meisten Features und Fixes stehen für sich selbst und sie in einen gemeinsamen Release-Branch zu bringen blockiert schnelle Releases einzelner Features. Für jeden Feature-Branch einen eigenen Release-Branch auf zu machen ist aber auch nicht sinnvoll. Der Feature-Branch sollte meiner Meinung nach auch sein eigener Release-Branch sein... also man braucht nur den Feature-Branch.
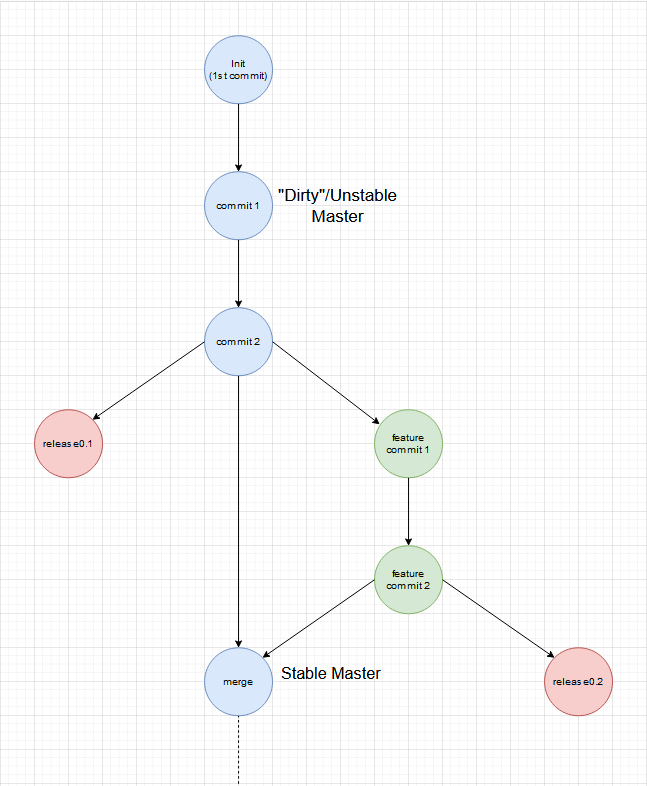
Ist es okay mit einem dreckigen Master-Branch zu starten?
Meiner Meinung nach ist es vollkommen ok. Ein leeres Projekt als stable zu deklarieren macht keinen Sinn und ist in den meisten Fällen auch nicht deploybar, da z.B. eine build.xml oder .gitlab-ci.yml noch fehlen.
Master mit dirty Commit vor dem ersten Release
Ich vertrete die Meinung, dass der Master erst nach dem ersten Release stable gehalten werden muss. Es folgt der Regel, dass im Master der letzte nutzbare Stand liegt. Wenn kein Release vorhanden ist, ist der letzte Commit der Dev-Version, die nutzbarste Version die man finden kann. In dem Sinne bemühe ich bei der Regel eine Art Fallback auf die Dev-Version, für die Zeit wo kein Release existiert. Nach dem ersten Release ist immer das letzte Release die nutzbarste Version.
Es gibt also immer eine nutzbare Version und nie "Nichts".
Am Freitag hat mir mein Kollege 2 Links zu Blogposts geschickt, die sich mit der Frage beschäftigen ob Git-Flow in der heutigen Zeit überhaupt noch funktioniert oder ob Git-Flow veraltet ist. Der 1. Blogpost zeigt erstmal nur Probleme auf und enthält keine Lösungen. Es passiert zu leicht das Release-Branches zu lange leben und dann darin selbst Entwicklung geschieht. Es dauert relativ lange bis eine Änderung durch die verschiedenen Branches im Master ankommen und am Schlimmsten ist noch, dass bei parallelen Entwicklungen ein nicht releaster Branch einen anderen aktuelleren, der einfach schneller war, blockiert.
Ja. Das ist jetzt nicht neu. Über diese Probleme habe ich 2009 schon im dem damaligen ERP-Team diskutiert (mein Gott waren wir damals schon modern...). Die Lösung hier ist einfach dass man harte Feature- und Code-Freezes braucht. Auch darf die Fachabteilung nicht erst im Release-Branch das erste Mal die neuen Features sehen. Ich habe es so erlebt. Dann kamen die neuen Anforderungen, Änderungen der gerade erst implementierten Features. Das soll aber so sein. Wenn das so ist braucht man aber auch noch das. Das ist falsch und muss so funktionieren... Alles Dinge die schon viel früher hätten klar sein müssen und erst dann hätte es zu einem Release-Branch kommen dürfen. Der Stand eines Feature-Branchs muss genau so auf einem System für Test und Abnahmen deploybar sein wie ein Release-Branch. Anders gesagt jeder Stand muss einfach immer präsentierbar sein!
Der 2. Blogpost brachte jetzt auch nicht wirklich neue Erkenntnisse, was am Ende der Author auch selbst schreibt.
Ich halte die Darstellung von Branches in parallelen Slots oder Lanes, die in dem Sinne ein Rennen um die Aktualität austragen für vollkommen falsch. Es darf auch nicht den develop-Branch oder den einen Release-Branch geben, der auch dann immer deckungsgleich mit dem Stand des Deployments auf einem System ist. In Zeiten von Docker und Reverse-Proxies zusammen mit Wildcard-Subdomains sind feste Systeme sowie so überholt. Jeder Branch kann ein System haben, auf dem Test, Abnahmen und Dokumentation stattfinden kann.
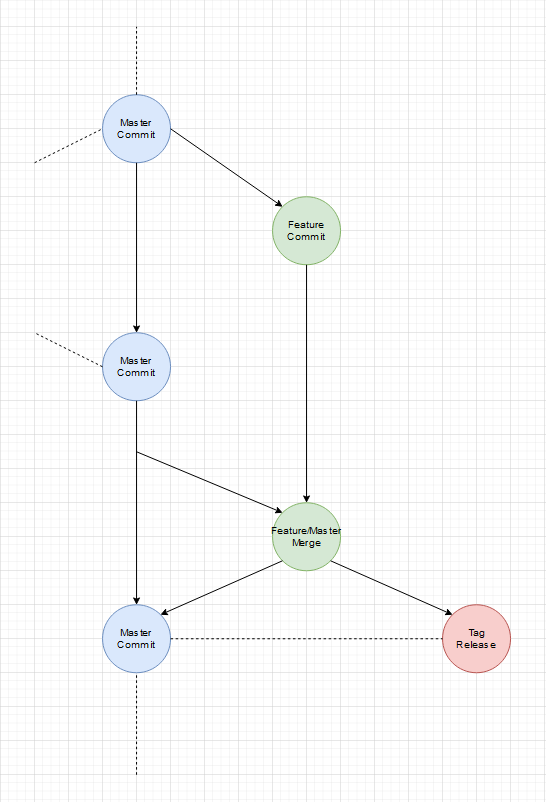
Das gilt auch für Tags. Branches sind variabel und ändern sich immer wieder. Tags sind statisch und damit perfekt für Zwecke, wo man kontrolliert bestimmte Stände deployen möchte. Tags persitieren einen bestimmten State/Zustand des gesamten Git-Repositories. Branches bilden einen State/Zustand aus der Sicht eines bestimmten Entwicklers oder eines bestimmten Features ab.
Deswegen halte ich feste Branches wie mit festen Aufgaben für komplett falsch. Ein Feature = ein Branch und am Ende steht ein Tag, der den gewünschten State/Zustand persitiert.
Ein einfacher Feature Branch:
Ja es gibt noch einen Master-Branch, der aber in dem Sinne nur ein 2D Abbild des wilden mehr dimensionallen Feature Raum ist. Wenn wir jeden Feature-Branch als Vektor der auf das einzelne Feature/Tag als Ziel zeigt versteht, ist der Master einfach die Projektion aller Vektoren auf eine Fläche. Diese vereinfachte Projektion hilft Feature-Branches vor dem Release auf den aktuellen Stand (was andere Features und Fixes angeht) zu bringen.
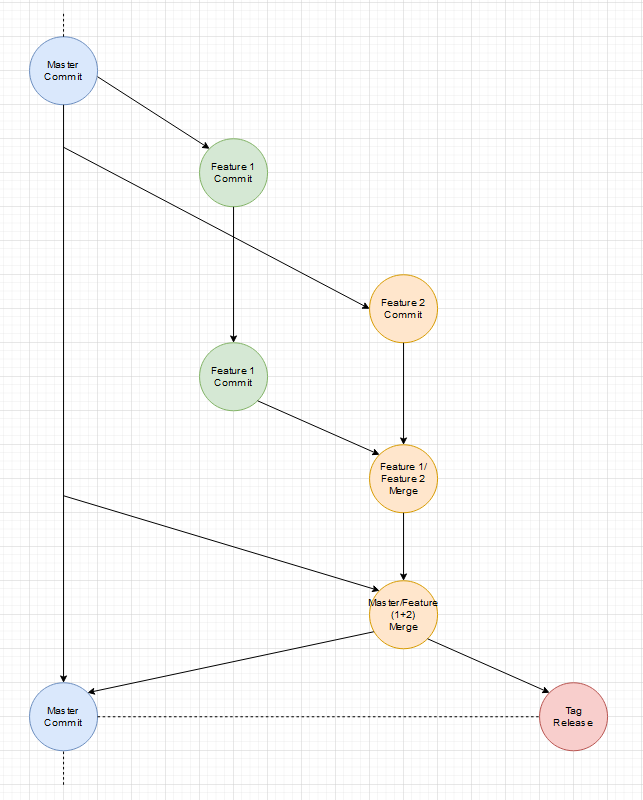
Es gibt auch immer mal Abstimmungsprobleme bei Features, die auf einander aufbauen. Interfaces haben minimale Abweichungen oder ein kleiner Satz in der Dokumentation wurde falsch verstanden. Was also wenn ein Feature doch noch eine kleine Änderung braucht, weil Entwicklungen parallel liefen?
Beides wird gleichzeitig fertig (ein extra Release-Branch wäre möglich):
Das Basis-Feature geht vorher live:
Das bessere und flexiblere Vorgehen
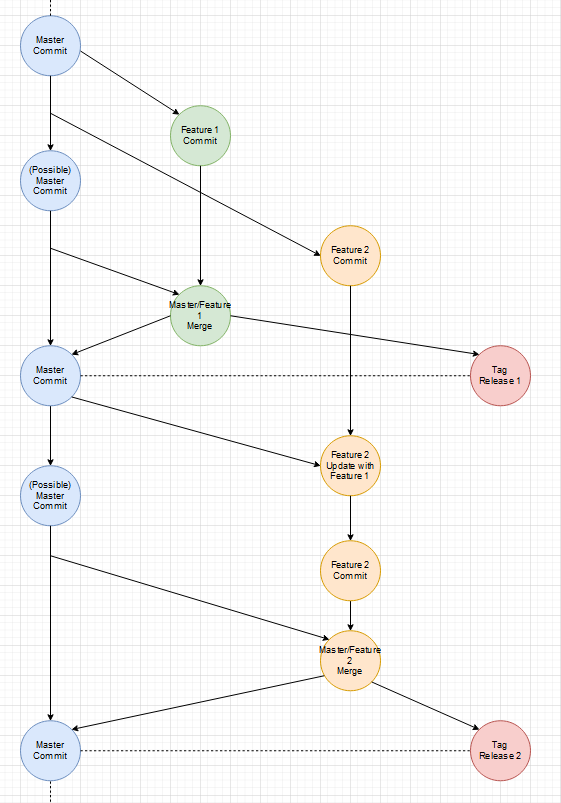
Gibt es einen Unterschied zwischen Fixes und Features? Nein. Beides sind Improvements des aktuellen States/Zustands. Wenn einem in einem Feature-Branch ein allgemeines Problem auffällt, fixt man das Problem und merged den Master mit der neuen Version erneut in den Feature-Branch.
Zwischenzeitlicher Fix:
Es ist an sich kein Unterschied zwischen einem Fix und einen weiteren Feature-Branch, außer dass der Fix-Branch sehr viel kurzlebiger ist und wohl weniger Commits enthält.
Der Master ist immer stable, weil nur Release-Tags darauf abgebildet sind.
Dieses Herangehen macht es sehr einfach jeden State/Zustand auf System abzubilden. Jeder Branch ist unter seinem Namen zu finden und Tags werden nach Typ auf Systeme gemappt.
Tag auf System: - release-XXX auf das produktive System
- staging auf das Staging-System (1:1 Namenabbildung)
- demo1-n auch 1:1 per Namen abbilden
Bei staging muss man den Tag löschen und neu anlegen, so kann jeder Zustand auf dem Staging-System deployt werden oder besser gesagt, wird ein Deployment durchgeführt das dann unter der Staging-Domain erreichbar ist. Hier gibt es eine tolle Anleitung wie man solche Systeme mit Traefik oder Kubernetes ganz einfach bauen kann. Ich werde das aber vielleicht auch noch mal genauer beschreiben, wie ich es für gut halte.
Denn Branches halte ich persönlich es nicht für wert wo anders als lokal in einem Docker-Container zu laufen. Da kann ich um es der Fachabteilung lieber schnell einen Tag erstellen und diesen nach dem Input der Abteilung auch wieder unter selben Namen neu anlegen oder unter einen neuen wenn zwei mögliche Umsetzungen verglichen werden sollen (macht das mal mit Git-Flow!).
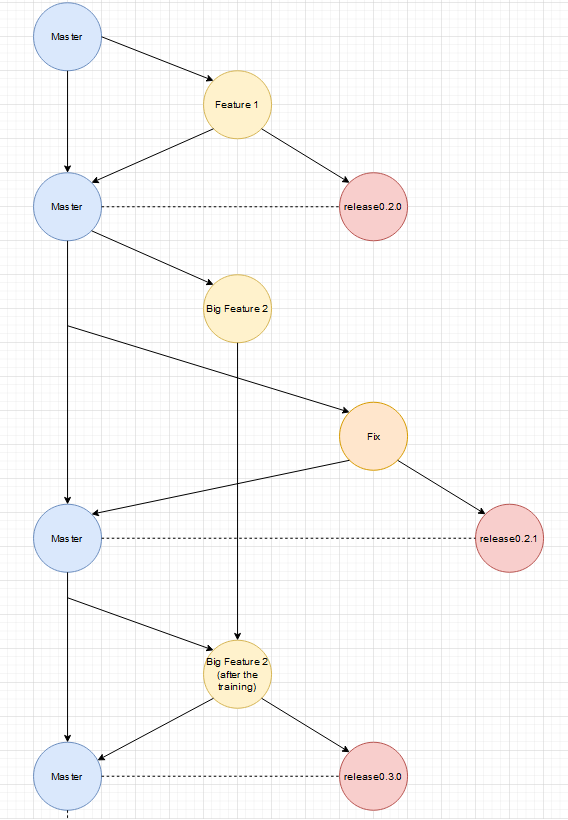
Edit: Ich habe die per Hand gezeichneten Diagramme durch vollständigere Diagramme, die per Software erstellt wurden, ausgetauscht.
Manchmal muss den Upload von Dateien testen. Nicht immer nutzt man etwas wie S3 sondern oft auch noch ganz klassische Umgebungen mit SCP oder sFTP. Wenn man schnell und unkompliziert den Upload auf einen sFTP-Server testen will, kann sich so einen ganz schnell und einfach mit Docker erzeugen.
docker run -p 2222:22 -d atmoz/sftp foo:pass:::upload
man kann sich dann auf localhost:2222 mit dem Benutzer foo und dem Passwort pass verbinden. Für Dateien steht das Upload-Verzeichnis bereit. Wenn man ihn nicht mehr braucht, wirft man den Container einfach weg und kann das nächste mal sauber mit einem neuen starten.
Jeder kennt Software, die man nicht mehr anfassen möchte. Man sagt, die Software wäre nicht mehr wartbar. Aber was bedeutet das überhaupt?
Die Definition von Wahnsinn ist, immer wieder das Gleiche zu tun und andere Ergebnisse zu erwarten.
von irgendwem.. vielleicht Einstein
Wenn eine Software unwartbar wird, gilt etwas sehr ähnliches.
Die Definition von unwartbar ist, an zwei augenscheinlich gleich funktionierenden Stellen etwas zu ändern und bei beiden das selbe Ergebnis zu erwarten... das es dann aber nicht ist!
von Hannes Pries... nach einen entsprechenden Tag
Oft ist solche Software organisch gewachsen. Organisch gewachsen bedeutet in diesem Fall, dass man nie das grundlegende System erweitert und verbessert hat, sondern einfach neue Funktionen drum herum gebaut hat. Auch wird oft Code kopiert und im Laufe der Zeit immer nur die einzelnen Code-Blöcke angepasst, wo es nötig ist und die anderen so belassen. Besser wäre es gewesen, den Code auszulagern, so dass an allen Stellen die Änderungen greifen.
Oft sind es gar nicht die ganz alten Code-Teile der aller ersten Version, die die Probleme machen, weil diese noch einem Konzept folgten. Mit der Zeit ist das Konzept verloren gegangen und die damaligen Entwickler sind oft schon lange nicht mehr dabei. Es gibt natürlich keine Doku, Namespaces und eine besonders übersichtliche Sortierung von Klassen sind meistens nicht vorhanden, gab es zu der Zeit einfach nicht oder wurden durch die ganzen Erweiterungen selbst zerstört.
Mit der Zeit setzt sich die Annahme durch, dass der damalige Code einfach schlecht war und man es erneuern sollte, wenn man etwas neues programmiert. Das führt dazu, dass jeder das auch macht und plötzlich 3-4 Implementierungen für ein und das selbe gibt.
Dumm nur, dass auch alle diese Implementierungen auch immer verwendet werden und so sich niemand traut eine der Implementierungen abzuschalten, weil es nicht der eigene Code ist und man sich nicht sicher ist, ob es wirklich 100%ig den selben Funktionsumfang hat.
Aber irgendwann muss man daran und dann baut man einfach etwas wieder ran und entfernt nicht einfach die Implementierung und nutzt die aktuellste.
Lustig ist auch, dass man oft gegen Ende der Lebenszeit einer Software, wenn man die Strukturen für einen Rewrite analysiert, feststellt, was das grundlegende alte Framework schon alles konnte und vieles was man später mit viel Aufwand eingebaut hat, schon lange da war. Oft auch sogar in einer gar nicht so schlechten Implementierung.
Jeder hat bei so etwas genau so mitgemacht, oder? Zeitdruck... neu bauen und nicht alten Code lesen. Wirklich mal mysqli-Funktionen gegen PDO ersetzen? Wäre toll, aber wer will sich wirklich die Arbeit machen, weil es ja doch alles irgendwie funktioniert. Das System verwendet viele PHP-Dateien und keine zentrale index.php? Kann man ja schnell bauen.. macht man aber nie und muss in vielen Dateien oft die selben Dinge ändern.
Was ist die Lösung? Sich klar werden, dass es nichts mehr bringt und das System sauber neu schreiben. Nicht für sich (naja.. doch irgendwie schon), sondern für andere Entwickler. Es muss ein System sein, wo man von ausgeht, dass es für jeden Fall eine Lösung mitbringt. Das System wird den selben Weg gehen und man muss versuchen schon ganz am Anfang anfangen gegen zu steuern auch noch kein anderer daran mit arbeitet.
Keep it simple! Keep it clean!
hat das schon mal wer anderes gesagt? Bestimmt!
Wenig Code, klare Interfaces mit 100%ig aussagekräftige Namen. Die Codevervollständigung ist die Suche nach der richtigen Klasse, also müssen alle Klassen richtig benannt sein.
Es ist alle schwerer als man denkt, aber Frameworks und Standards wie PSR bei PHP helfen da sehr. Sich einfach auf den Stil und die Konventionen des Frameworks einlassen und sich aneignen. Dann klappt es schon. Auch wenn es schwer ist.
Gerade wenn man Apps (PWAs) entwickelt, die zwingend HTTPS brauchen, weil man auf Dinge wie die interne Kamera des Geräts zugreifen möchte, kommt man zu dem Problem auch die Middleware mit HTTPS betreiben zu müssen. Kein Browser mag Mixed-Content. Wenn die Middleware mit Spring Boot geschrieben ist, kommt man aber auch da ziemlich schnell und einfach zu einer Lösung.
Das funktioniert sogar ohne komplexe Keystore Aktionen und irgendwelchen Signieren von gebauten Artefakten.
Die einfachste Lösung ist sich ein PKCS#12-Certificate (als das als Datei, PKCS#11 ist das von den Smartcards) zu erzeugen und direkt als Keystore zu nutzen.
Neben dem Alias sollte man auch den Dateinamen der p12-Datei anpassen. Danach muss man viele Daten angeben (die man sonst in openssl in der Conf-Datei ablegen würde). Die p12-Datei kann man nun einfach im resources-Bereich im Default-Package ablegen (bzw. auch in jedem anderen Package, wo es per getResource erreichbar ist).
Danach muss man die Daten nur noch in der application.properties eintragen.
Danach sollte Spring Boot wie vorher auf dem konfigurierten Port starten, aber ab jetzt nur noch per HTTPS erreichbar sein.
Das Certificate ist natürlich nur self-signed und eignet sich nur für Dev-Umgebungen. Bevor die PWA auf die Middleware zu greifen kann, muss man mit dem Browser die Middleware einmal aufrufen und den Zugriff für den Browser erlauben. Danach sollte es dann gehen.
Ich habe mir diesen Artikel durch gelesen, warum man bis 2020 Python lernen sollte. Aber irgendwie überzeugen mich diese Gründe so gar nicht. Ich hab schon mal ein paar Dinge mit Python gemacht und am Ende, war es eine Sprache wie jede andere. Viel weniger Boilerplate-Code als Java, aber dass ist keine Kunst und mit Lombok und ähnlichen hat sich auch bei Java viel getan. Aber mal der Reihe nach:
1. Automatisiert triviale Aufgaben Das kann ich mit PHP (mit Symfony-CLI) auch ganz gut. Kleine Tools schreiben ohne viel Framework wie JRE + Spring + JPA + etc haben zu müssen. Aber sobald der Code Compiler wird, kommt auch da alles hinzu. Ich sehe da eher den Vorteil dass Python auf IoT-Geräten gut läuft und man sehr viel Overhead einsparen kann.
2. Schneller Einstieg und einfache Syntax Stimmt. Das Beispiel ist zwar nicht aussagekräftig da der Boilerplate-Code mit zunehmenden Code immer geringere Anteile einnimmt und man sich viel Code heute ja auch automatisch generieren lassen kann. IDEs sei dank bringt einen diesen Code zu schreiben kaum einen zeitlichen Nachteil. Also... ja.. Python ist nicht schwer, aber auch nicht leichter als PHP oder JavaScript. Java ist an sich auch nicht schwer, man muss nur eben Classes und Packages richtig nutzen und schon ist alles sehr übersichtlich. Je weniger Struktur man braucht desto schwieriger wird es auch für die IDE bei der Codevervollständigung zu helfen. Java ist da einfach immer noch weit vorne.
3. Data Science Geil... wenn ich Python kann, kann ich Data Science? Nein. Irgendwer hat man angefangen Python in dem Bereich zu nutzen und hat gute Libs geschrieben. Oft sind die Libs Ausschlag gebender als die Sprache an sich. Also war es wohl eher Zufall dass in dem Bereich Python hauptsächlich eingesetzt wird und nicht der Sprache an sich geschuldet. Bloss weil ich das Hauptwerkzeug für einen Berufszweig benutzen kann, kann ich auch den Beruf ausüben... ich kann mit einem Skalpell scheiden!!!!
4. Machine Learning Ja.. auch cool. Tolles und komplexes Thema. Werkzeuge dafür zu erlernen ist hier sicher nicht die größte Herausforderung in dem Bereich.
5. Ressourcen Wie oben schon beschrieben. Wenn die Lib mein Problem löst, nehme ich die Sprache für die es die Lib gibt. Da ist es egal ob es Python, Java oder C++ ist. Ich nehme einfach das, was mein Problem schnell und einfach löst. Also bringt es mir nichts Python zu lernen, weil es tolle Libs gibt. Wenn ich eine Lib benutzen will, dann habe ich ein Grund mir die Sprache anzueignen.. vorher nicht (außer aus Spass oder Lerndrang).
6. Community Das gilt an sich für jede größere Programmiersprache. Stackoverflow hilft, deutsche Foren liefern nie eine Lösung. Alles wie immer.
Zusammenfassend kann ich für mich nur sagen. Es lohnt sich für mich nicht eine neue Sprache zu lernen, weil man theoretisch super tolle Dinge damit machen könnte, die ich entweder nicht beherrsche oder nicht benötige. Die Standardaufgaben können alle Sprachen fast gleich gut und da zwischen den Sprachen zu wechseln fällt auch entsprechend leicht. Mal mit einer Sprache rumspielen ist immer lustig und macht Spass, aber eine Sprache wirklich lernen ist nru nötig wenn man es benötigt. IoT-Geräte sehe ich da noch als den wahrscheinlichsten Grund, warum ich mal wieder was mit Python machen sollte.
Manchmal braucht man schnell und einfach einen HTTPS-Server um z.B. eine App auszuliefern, die auf die Kamera des PC oder Smartphones per WebRTC zugreift. Das geht an sich ganz einfach wenn man weiß, was man alles braucht.
Damit hat man direkt einen HTTPS-Server bei dem man nur noch das unsichere Zertifikat akzeptieren muss.
Wenn man Windows verwendet muss man über die Bash (WSL) OpenSSL, NodeJS und NPM installieren und dann ist es wie unter Linux.. man befindet sich dann ja auch in einem Linux....
Agil arbeiten ist voll in und jeder will es machen. Klingt eben cool, wenn man sagen kann, dass man Scrum macht und UserStories entwirft und danach arbeitet. Leider ist agiles Arbeiten nichts, was man den Mitarbeitern einfach mal vorschreiben kann und es dann auch so in Zukunft läuft. Agil ist viel mehr als ein Whiteboard mit ToDos und Sprints mit 2 Wochen Laufzeit, wo am Ende es Sprints alles fertig ist, was man an das Board geklebt hat.
Wenn man wirklich agil arbeiten will, muss man erst einmal sich um die Hierarchie kümmern, weil diese agilen Arbeiten meistens im Weg steht. Wer so arbeitet, dass Aufgaben durch 3-4 Schichten von Oben nach Unten herunter gereicht werden und jeder nur die Infos bekommt, die er gerade braucht, wird das ganze Vorhaben scheitern. Wichtig beim agilen Arbeiten ist, dass die Mitarbeiter, die es umsetzen sollen, auch vollumfänglich informiert sind und nicht nur das wissen, was in dem aktuellen Sprint umgesetzt werden sollen.
Oft läuft es so das der Chef seine Idee mit dem Abteilungsleiter bespricht, der guckt was zu machen ist und stimmt sich mit dem Teamleiter/Scrummaster ab was in einem Sprint abgearbeitet werden soll. Die Mitarbeiter dürfen dann noch mal die Aufwände schätzen für das was sie in der Zeit erledigen sollen. Meistens müssen, dann die Aufwände aber dann auch so geschätzt werden, dass es passt, weil der Inhalt des Sprints ja schon fest gelegt wird. Was im Backlog für die nächsten Sprints steht, wird oft nicht mitgeteilt. Damit wird den Mitarbeitern aber die Möglichkeit genommen schon mal Erkenntnisse und konkretes Wissen für die Zukunft zu sammeln. Weil.. man ist ja agil und wenn sich die Arbeit des Sprints leider als nicht zukunftssicher heraus stellt, macht man es eben nochmal. Aber Hauptsache man wird am Sprintende mit den Aufgaben fertig.
Im Grunde kennt man dieses Vorgehen schon lange. Man bekommt die Anforderungen diktiert, dann werden diese umgesetzt und am Ende wird geguckt, ob es das ist was man haben wollte. Wenn nicht fängt man wieder von vorne an. Das ist das klassische Wasserfall-Model.
Nur eben auf 2 Wochen herunter gebrochen. Das ist nicht Agil. Man blickt nicht über den Tellerrand und passt sich ändernden Anforderungen an. Wenn sich mitten drin was ändert wird es oft nicht mitgeteilt, wenn dann heißt es man müsse das Sprintziel um jeden Preis erreichen und im nächsten Sprint würde man es eben dann nochmal machen.
Planung und Konzeption wird weiterhin von der "Führungsebene" gemacht. Die Mitarbeiter arbeiten nur wieder stur nach Vorgaben ihre ToDos ab. Sollte ein ToDo in der Umsetzung nicht genau spezifiziert sein, kann dieses nicht bearbeitet werden. Ein Konzept kann sich nicht mit der Zeit entwickeln, weil es kein Feedback über Erkenntnisse und neue Erfahrungen gibt.
Hier ist aber nicht nur die "Führungsebene" schuld, sondern oft auch Mitarbeiter, die viel lieber nach festen Vorgaben arbeiten und nicht selbst die Lösung für das Problem entwickeln wollen. Die Verantwortung für ein Produkt wird da immer noch nach oben gereicht, weil der Mitarbeiter führt ja nur aus.
Wie macht man es besser. Man braucht eine direkte und vollständige Kommunikation über alle Grenzen hinweg. Die Vision muss allen klar sein und jeder muss auch bereit sein diese selbstverantwortlich um zu setzen. Jeder soll eine Lösung vorschlagen können. Bei klaren Anforderungen muss auch nicht jeder Pups besprochen werden, weil jeder ja daran interessiert ist, das Produkt fertig zu stellen, wird auch jeder die seiner Ansicht nach beste Lösung implementieren. Und wenn man ehrlich ist, kann jede andere Lösung genau so "richtig" oder "falsch" sein, wie die andere. Zu viel diskutieren bringt am Ende nichts, lieber machen und ausprobieren.
Niemand wird dir das Denken dabei abnehmen. Immer mit denken und den Denkprozess und die Entscheidungen dazu immer dicht man Entwicklungsprozess halten. Bei den Meetings können Vorschläge gemacht werden, aber diese sind nicht in Stein gemeißelt sondern wie gesagt nur Vorschläge und mögliche Lösungen. Wenn es sich auf halben Wege heraus stellt, dass es nicht so geht.. abbrechen und direkt neu anfangen. Ein Sprintziel ist nie wichtiger als das Produkt. Was bringt es ein Feature zu Ende zu implementieren, wenn die Implementierung sowie so
wieder verworfen wird? Nichts.. es verbraucht nur Zeit und Kunden könnten glauben, es würde doch schon fertig sein. Wenn man etwas macht, dann richtig und dafür darf man keine Angst haben mal was aus zu probieren und dann mit dem Versuch auch zu scheitern.
Retrospektiven und Meetings sind wichtig, weil da keine nach unten gerichtete Kommunikation stattfindet, sondern alle auf Augenhöhe mit einander reden können. Auf von "unten" muss klar kommuniziert werden, was und wie viel man schafft und schaffen will. Ein Sprint ist kein Zeitraum wo man möglichst viele Aufgaben reindrückt und am Ende Crunchtime erzeugt, damit das Sprintziel auf jeden Fall erreicht wird. Lieber weniger einplanen und dem Sprintende entspannt und zufrieden entgegen sehen. Lieber die Zeit nutzen um Lösungen zu entwickeln und geplante ToDos noch mals zu analysieren und schon mal etwas auszuarbeiten.
Viele leben aber noch zu sehr in ihrer hierarchischen Wasserfall-Welt, wo Kommunikation nur in eine Richtung geht, nur konkrete Ausgaben kommuniziert werden und ein Sprint ein Timeslot ist, in dem man möglichst viel Arbeit erledigt haben will und das Sprintende eher drohend sein soll und nicht erwartet werden soll.
Agil bedeutet für mich, dass Informationen in alle Richtungen fließen und einen beim Denken und Lösungen finden immer zur Verfügung stehen. Agil ist, wenn man schnell austestet, schnell scheitert und schnell mit der mehr Erfahrung von neuen beginnen kann. Wo man neue Fehler machen kann um so zu neuen Lösungen zu kommen. Und für all dieses übernehme ich dann auch gerne die Verantwortung
[2018-01-09 13:26:18] plugin.WARNING: SW001: price[EK] should be checked, sell for 1041.18, purchase for 2380 by demo [] {"uid":"5e860d0"}
[2018-01-09 13:27:58] plugin.WARNING: SW002: price(EK) should be checked, sell for 8.40, purchase for 59.5 by demo. [] {"uid":"075a3b6"}
Die obere Zeile kann im Shopware Backend nicht angezeigt werden. Die untere schon. Also sollte man mit eckigen Klammern in Log-Messages aufpassen.
Nachdem Firefox 57 meine alten Plugins entsorgt hat, brauchte ich auf die schnelle wieder ein Plugin um Xdebug triggern zu können, damit ich wieder in PHPStorm debuggen konnte. Ich bin jetzt bei diesen hier gelandet...
Wenn eine Exception auftritt oder eine Fehlermeldung kommt (egal ob per Email oder aus einem Log) ist eine Sache ganz wichtig: Ruhe bewahren!
So. Da wir nun ruhig sind, gucken wir uns die Fehlermeldung oder Exception an. Wir überlegen nicht was wir als letztes geändert haben oder welcher Klick oder welche Eingabe alles ausgelöst hat. Das wäre verschwendete Zeit, weil genau diese Info steht ja in der Fehlermeldung/Exception.
Wir lesen einmal quer rüber. Kommt uns etwas Bekannt vor? Klassennamen? Module? SQL-Statements?
Nein? Schade.. aber auch nicht so schlimm.
Wir müssen uns nur 3 Fragen beantworten:
1) Welche Daten sollten hier durch gereicht werden?
2) Wo fing es an (Ursprung der Daten)?
3) Wo wollte man hin (Ziel der Daten)?
Bei einer Nullpointer-Exception z.B. geht es darum, erst einmal heraus zu bekommen, welche Daten verloren gegangen sind.
Dann gucken wir wo die herkommen sollten und ob von dort vielleicht schon NULL her kam.
Als letztes gucken wir wo es hin sollte und ob der mit dem NULL vielleicht sogar klar gekommen wäre und der Fehler bei einem zwischen Schritt liegt oder bei so einem schon auffiel.
Am Ende bleibt nur dann zu klären, wo in dieser Kette passierte das Falsche und dann muss geklärt werden warum eben jenes passierte.
Vermuten und Eingebungen sind Teil des letzten Schrittes und nie des ersten. Aber das Wichtigste ist immer noch die Fehlermeldung/Exception auch erst einmal in Ruhe zu lesen und in ihre Teile zu zerlegen, um alle Informationen atomar vorliegen zu haben.
Alles hat nicht geholfen? Dann ist das Logging scheiße und unvollständig.. bitte das Logging verbessern :-)
Am Ende dachte ich mir nur: "ist an sich ja genau so wie in meinem Framework.."
Ok. Alle Sprachen in einer Datei und nicht wie bei den Properties-Dateien in Java, aber ansonsten. Im Grunde hat man eine ini-Datei die eingelesen wird. Sie hat einen Namespace, was es sehr viel einfacher macht auf Text-Snippets anderer Plugins oder des Core-Systems zuzugreifen.
Momentan steht bei mir an ein Plugin für Shopware zu entwickeln.
Das erste Problem dabei ist nicht mal, wie das funktioniert, weil das ist im Internet mehrfach gut erklärt, sondern wie man seine Entwicklungsumgebung aufsetzt.
Shopware ist schnell installiert. Aber man will für ein Plugin ja nicht immer das gesamte Shopware mit im Projekt haben. Also wird nur das Verzeichnis aus custom/plugins/ als Projekt-Verzeichnis gewählt.
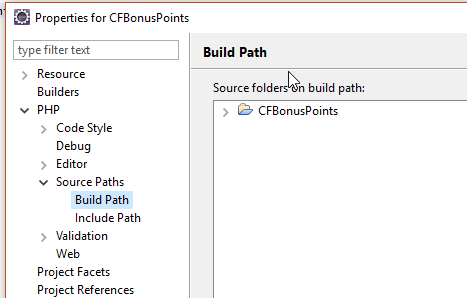
Bei Eclipse kann man Projektverzeichnisse außerhalb des Workspaces anlegen.
Nun hat man das Problem, dass einem die ganzen Klassen von Shopware fehlen und man so viele Warnings und keine Autovervollständigung hätte.
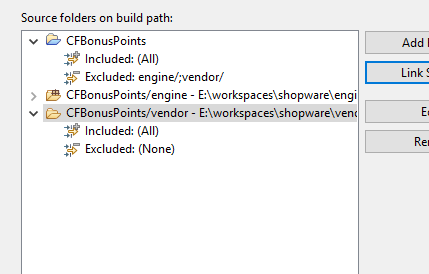
Über Properties > PHP > Source Paths > Build Path kann man externe Source-Verzeichnisse verlinken.
ich habe das engine-Verzeichnis von Shopware gewählt und noch zusätzlich dessen vendor-Verzeichnis.
Die PHPUnit Tests werfen dann zwar noch Fehler. Aber die Plugin-Klasse von Shopware wird schon einmal gefunden und damit ist der erste Schritt schon getan.
Damit kann meine Arbeit an meinem ersten Shopware-Plugin jetzt anfangen.
Morgen beginnen die Test meiner ersten beiden Shopware Plugins. Teilweise sehen sie auch wirklich wie "die ersten" aus, auch wenn ich nochmal viel nachgebessert habe. Aber gerade optisch ist noch viel Raum nach Oben. Bis Freitag kann man da sicher noch was machen, um auch optisch noch was besseres abliefern zu können.
Weitere und bessere Plugins, aber erst einmal ohne Oberflächen, sondern als Unterstützung für Entwickler und Designer, folgen dann hoffentlich in den nächsten Wochen und Monaten.
foreach ($this->getListeners($event) as $listener) {
if (null !== ($return = $listener->execute($eventArgs))) {
$eventArgs->setReturn($return);
}
}
$eventArgs->setProcessed(true);
return $eventArgs->getReturn();
}
und da sehen wir
$eventArgs->setReturn($value);
Also ist die Lösung
public function eventMailListener(\Enlight_Event_EventArgs $args){
/** @var \Enlight_Components_Mail $mail */
$mail = $args->getReturn();
echo $mail->getPlainBodyText();
die();
}
Wenn man das erst einmal verstanden hat, ist alles plötzlich ganz einfach. Ach ja, wenn man das Subject überschreiben möchte erst einmal $mail->clearSubject(); ausführen.
Gerade in Firmennetzwerken kann man nicht immer wie man gerade will eine VM ins Netzwerk hängen. Oft hat man aber Bedarf an einer VM. Gerade wenn man auf Windows entwickelt und am Ende auf Linux deployen soll, ist es immer gut eine Linux-VM zur Hand zu haben, um schnell selbst testen zu können, ob da noch alles läuft.
Auch fertige VMs wie die von Oracle mit einer fertig installierten Datenbank sind wirklich praktisch und können in vielen Situationen helfen.
Um jetzt aber einen eigenen Server in VM zu betreiben, von dem man vom Host aus zugreifen kann, aber kein anderer Rechner im Netzwerk diesen Server sehen kann, kann man in VirtualBox ein Host-only Netzwerk erstellen. Der Host ist Teil des Netzwerks, aber er Rest ist rein virtuell.
Beim einfachen Anlegen einer VM ist immer NAT voreingestellt.
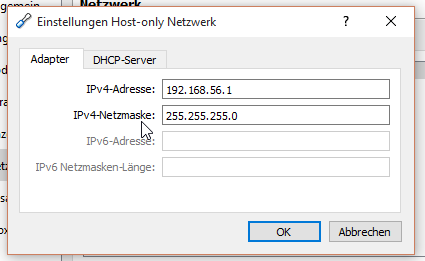
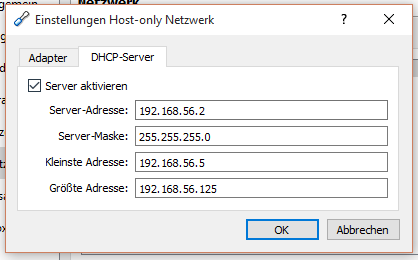
Zuerst muss man das Host-only Netzwerk erstellen.
am Besten mit DHCP damit man sich nicht mit den IP-Adressen herum ärgern muss.
Danach die VM von "NAT" auf "Host-only" beim Netzwerkadapter umstellen.
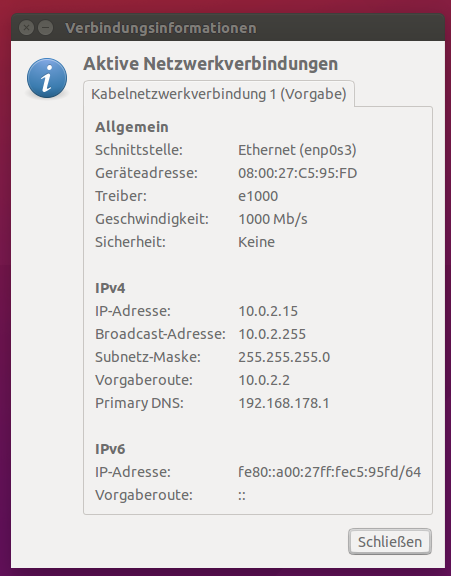
Wenn man nun die VM wieder startet sieht man schon dass die IP sich geändert hat
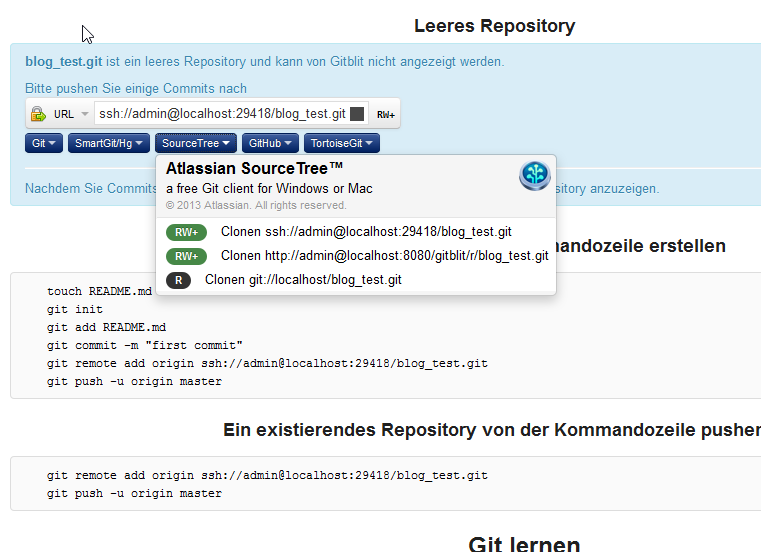
Nachdem ich feststellen musste, dass man Stash/BitBucket zwar für $10 für ein kleines Team kaufen kann, aber man dafür eine Kreditkarte benötigt, habe ich mit auf die Suche nach einer kostenlosen Alternative.
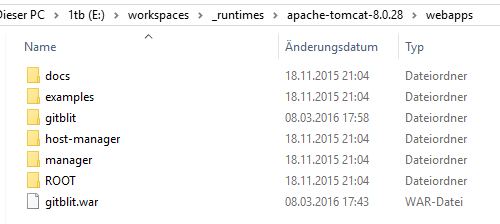
Das Problem der meisten Alternativen wie Gerrit oder Apache Allura ist doch die immer sehr aufwendige und auch umständliche Installation. Auch gerade wenn man Windows benutzt und nicht Linux. Auch hat nicht jeder Windows-Benutzer der Zuhause etwas entwickeln möchte eine Windows 2008 Server-Version. Ich hatte mir etwas vorgestellt, was ich einfach im Tomcat deployen kann als WAR und dann ist es da (vielleicht noch Einstellungen wie Speicherort und Datenbank.. aber nicht viel mehr). Die beiden genannten Systeme können
zwar sehr viel und gerade Gerrit ist wohl noch mal einen zweiten Blick wert, aber ich wollte erst einmal schnell was kleines und einfaches.
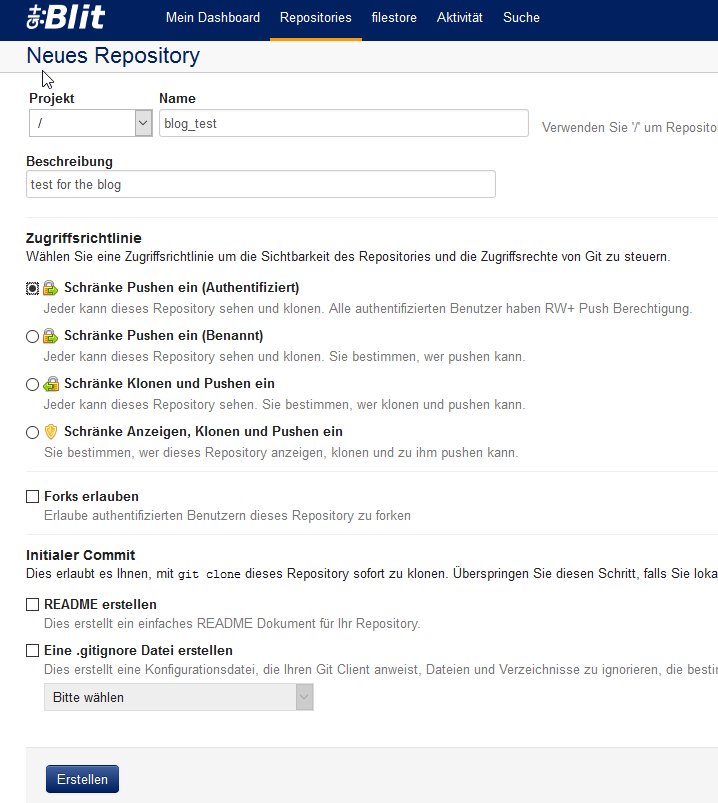
Ich habe länger gesucht und habe am Ende Gitblit gefunden. Die WAR downloaden, ins webapp Verzeichnis kopieren und den Tomcat starten... und es war da. Eingeloggt mit dem default-User und alles erschloss sich gleich.
Und mit das Beste ist die vorhandene Integration von SourceTree, die bei mir langsam war aber an sich sauber und gut funktionierte. So kann man sich auf jeden Fall für Testzwecke in wenigen Minuten einen GIT-Server einrichten.
Was ist eigentlich die Aufgabe eines Softwareentwicklers? Natürlich Software entwickeln.. das ist ja klar. Aber warum entwickelt man Software.
Ok.. erst einmal natürich, weil es der Beruf ist man von irgendwas leben muss. Aber warum entwickelt man Software in seiner Freizeit? Geld? Ansehen? Aber in den meisten Fällen einfach um ein Problem zu lösen.
Selbst wenn es um Geld geht sollte an sich das Problemlösen im Mittelpunkt stehen. Wenn ein Kunde gerne eine Homepage mit einem entsprechenden System hätte, um seinen Job besser erledign zu können, schreibt man ihm ein Angebot. Individuelle SYsteme sind aber teuer. Wenn der Kunde sich es also nicht leisten kann, sollte man nicht einfach dann sagen "Pech gehabt!", sondern überlegen wie man das Problem lösen kann.
Die Lösung heißt nicht auf Geld zu verzichten, man muss ja auch bezahlt werden, aber es gibt immer eine Lösung. Wieso nich ein System entwickeln, dass der Kunde verwenden kann un sich trotzdem noch an andere verkaufen läßt?
Die Software die man entwickelt ist nur da Werkzeug, um die Probleme zu lösen. Daran sollte man immer denken. Eine gute Software ist nicht gut, weil sie viele Features hat oder hübsch aussieht, sie st gut weil sie ein Problem löst.
Darum nutzen viele noch Jahre alte Software, weil sie einfach das Problem gut löst. Es geht nicht um Technik oder immer das modernste zu haben. Die Umsetzung sollte gut sein, damt die Software lange stabil läuft.. aber sie mus kein Meiterwerk an Abstraktion und Programmierkünsten sein.
Das macht einen guten Softwareeentwickler aus.. Software zu schreiben, die die Probleme der Leute löst. Oder sie soweit ablenkt, dass sie die Probleme mal vergessen können :-)
Gehen wir mal davon aus, ich hätte doch mal das Geld für einen neuen PC und würde alles neu installieren müssen.
Was wäre das alles? Bei vielen Programmen nehme ich die portable-Version wenn vorhanden, weil man dann einfach das
Programm inkl. alle Einstellungen und Daten kopieren kann und sich nicht über die Migration der Daten Gedanken machen braucht.
* Notepad++ (Portable): Seit man einfach den Editor schließen kann und er speichert auch nicht gespeicherte Texte automatisch mit, ist er ideal für Notizen, kleine Text und schnelle Bearbeitungen einzelner Dateien. EmEditor kann es nicht, dafür paar andere tolle Dinge, wie Zeilen mit Such-Treffen in ein neues Dokument extrahieren, aber gerade dass ich EmEditor nicht einfach schließen kann ohne zu speichern, empfinde ich als großen Nachteil.
* WinSCP (Portable): Der eingebaute Editor ist kein Highlight, aber besser als wenn per Default immer der von Windows verwendet werden würde. Das Programm läuft auch stabil und hat mich bis jetzt nie im Stich gelassen. Bitvise finde ist als SFTP oder SSH Client irgendwie schlechter zu bedienen und es ist eben nicht Opensource.
* Eclipse + PDT: Bei Eclipse reicht es auch die ZIP-Datei zu entpacken. Über das Software-Menü dann einfach PDT nach installieren und vielleicht nochmal die Zuordnung der *.php-Dateien zum entsprechenden Editor bearbeiten.Wie man Unterstützung für Getter und
Setter installiert findet man hier: PDT-Extensions. PHPStorm kann auch einiges. Ich finde es aber auch unübersichtlich. RemoteHost-View.. ist unter Deployment zu finden. An sich ja nicht verkehrt, wenn man das weiß. Bei Eclipse einfach bei den Views gucken. Da kann man auch suchen und findet alles innerhalb von Sekunden. Vielleicht liegt es auch daran dass ich Jahre mit Eclipse verbracht habe und es lieben und auch oft
genug hassen gelernt habe, aber bei PHP ist es mein Favorit und es ist eben Opensource.
* Oracle SQLDeveloper: Wenn man mal mit Oracle zu tun hat oder keine Lust auf phpMyAdmin hat, ist es immer noch meine Lieblingssoftware für Datenbank-Entwicklung. phpMyAdmin ist eben sehr träge (für eine Webanwendung aber noch wirklich schnell.. nur im Vergleich). HeidiSQL ist einfach nicht so professionell. Man merkt dass Oracle sich mit Datenbanken auskennt.
* Source Tree für GIT-Repositories. Die GIT-Integration in Eclipse war jedenfalls nie wirklich toll, wie ich fand. Der Konsolen-Client funktionierte,war aber für Nicht-Programmierer wirklich zu umständlich. Tortoise.. ja.. hat bei mir noch aus Delphi+SVN Zeiten einen schlechten Nachgeschmack hinterlassen. Auch wenn deren SVN Client manchmal durch mergen zerstörte Projekte wieder retten musste zusammen mit Notepad++.
* XAMPP oder Bitnami... Benutze ich beides und am Ende mag ich XAMPP minimal lieber. Deren Kontroll-GUI ist etwas aufgeräumter und ich kann auch hier einfaches von einem PC auf den anderen kopieren. Aber funktionieren tun beide gut.
* ein aktuelles JDK: Weil viele der oben genannten Programme Java-Programme sind und ich unter Umständen auch mal ein kleines Java-Programm schreiben oder pflegen muss. Eine aktuelle JDK8-Version installieren und die reicht erst einmal lange ohne Updates. Sollte ich nicht doch plötzlich wieder voll auf Java setzen. Dann aber nur mit Tomcat und vielleicht der aktuellsten JSF-Version oder meinen REST-Framework und das Frontend entsteht komplett in AngularJS (habe ich so schon benutzt und funktioniert extrem gut und ist PHP mit dem Application-Scope und echten Singletons teilweise
weit voraus bei der Performance.. mal PHP7 abwarten).
Und dann eben noch der ganze Rest wie Firefox Developer Edition (64-Bit), Thunderbird, Chrome, etc. Was man auch zum Testen und dem Alltag so
braucht.
Manchmal gibt es ja Probleme die man nur mit produktiven Daten nachgestellt bekommt. Oder man hat keine gute Möglichkeit vielDaten zu erzeugen um Test mit vielen realistischen Daten durch zu führen. Dann hilft oft eine Kopie der Datenbank des produktivenSystems.
Nur echte Kunden-Daten auf einer Entwickler-Workstation liegen zu haben, ist nicht wirklich toll. Der Datenschutz und so.
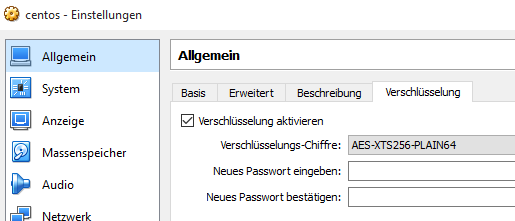
Hier hilft es die Datenbank in einer VM zu betreiben und einfach die gesamte VM zu verschlüsseln. Man muss nichts an der Workstationändern und hat trotzdem eine gute Sicherheit für die Daten.
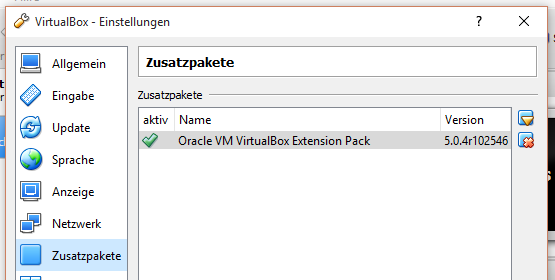
Bei VirtualBox muss man nur das Erweiterungs-Pack downloaden und schon kann man dort eine gesamte VM verschlüsseln.
Ein wirklich gutes Buch. Der Vorteil ist, dass Kapitel so geschrieben sind, dass man auch mal welche überspringen kann. Zum Beispiel das Kaptiel über Sourcecode Management Systeme wie SVN oder CVS werden heute kaum noch jemanden neues zeigen können.
Auf die Zusammenfassungen am Ende der Kaptiel und des gesamten Buches sind toll. Es gibt Listen wie es laufen sollte, wie man es verbessern kann und welche Anzeichen dafür sprechen, dass Verbesserungsbedarf besteht.
Ich fand das Kapitel über Daily-Meetings und "The List", also priorisierte Todo-Listen wirklich gut und sie gaben mir neue Denkanstöße. Ich werde mal versuchen Daily-Meetings in meinen Arbneitstag einzubringen und umzusetzten.. mal sehen was mein Chef dazu sagt :-)
Ich kann jedem Entwickler, Projektleiter und Kontakt-Person, die mit einem der beiden erst genannten für einen Kunden Kontakt halten muss empfehlen.
Denn wenn der Kunde die Probleme der Entwickler versteht und der Entwickler die Probleme der Kunden (etwas technisches zu Formulieren und Zeiten abschätzen zu können), dann kann man viele Missverständnisse schon mal vermeiden. Und dieses Buch ist einfach formuliert mit Reallife-Beispielen und könnte als neutraler Dritter zwischen beiden Seiten einen gemeinsamen Konsens vermitteln.
Gerade beim Laden großer Datenmengen wie Lagerstrukturen oder bei Exporten ganzer Datenbestände, kommt man schnell in Bereiche, wo das Laden und Aufbereiten mehr als ein paar Minuten dauern kann. Bei normalen Desktop-Programmen und Skripten ist das nicht ganz so relevant. Wenn man aber im Web-Bereich arbeitet, kann es schnell zu Problemen mit Timeouts kommen. 3 Minuten können hier schon ein extremes Problem sein. Asynchrone Client helfen hier, aber keiner Wartet gerne und Zeit ist Geld.
Es gibt dann einen Punkt, wo die Zeit pro zu ladenen Element sich nicht mehr weiter verringern lässt. Hier hilft dann nur noch die Verarbeitung der einzelnen Elemente zu parallelisieren. Bei Java gibt es den ExecutorService, in JavaScript die WebWorker und in PHP gibt es pthreads. Es ist nichts für Leute mit einem Shared-Hosted Webspace, weil man eine Extension nach installieren muss.
Hier ist ein kleines Beispiel wo eine Liste von MD5-Hashes erzeugt werden soll. Die Threaded-Variante lief bei mir meistens fast doppelt so schnell
wie die einfache Variante mit der Schleife.
Man kann also auch in PHP moderne Anwendungen schrieben die Multi-Core CPUs auch wirklich ausnutzen können und muss sich hinter Java in den meisten Bereichen nicht mehr verstecken.
Nachdem ich noch bei einem Abschiedsessen mit meinen alten Kollegen, doch noch mal auf der Thema der Entwicklungsgeschwindigkeit und Qualität an dem Abend gekommen bin, werde ich mir dieses Thema hier doch mal annehmen. Es ist ein kompliziertes Thema, dass keine richtige einzelne richtige Lösung kennt, aber dafür Raum für viele Fehler bereit hält. Ich stütze mich jetzt einfach mal auf 10 Jahre Erfahrung in der Softwareentwicklung und der Mitarbeit in Teams, die eben auch mit diesen Problemen zu kämpfen hatten und auch noch haben. Denn auch wenn man Lösungen kennt, muss man den Weg immer noch gehen.
Neben der verlorenen Zeit stellen diese Probleme auch für die Entwickler eine nicht zu unterschätzende Belastung da.
Frameworks vs eigenen Code
Einer der größten Fehler wurde gleich am Anfang gemacht. Es sollte schnell los gehen und da wurde auf Abstraktion und der Suche nach vorhandenen Lösungen verzichtet. Es wurde alles auf der untersten Ebene begonnen. Also keine Kapselung oder ähnliches. Entitäten-Objekte wurden direkt vom Service an den Client geschickt. Eine allgemeine Kommunikationsstruktur zwischen den beiden wurde nicht entwickelt.
Oberflächen und Logik wurden einfach zusammen in eine Klasse geschrieben. DTOs, DAOs und DataBindung waren aber schon da keine neuen Konzepte mehr. Das alles führte dazu, dass man sich mit EJB und SWT jeweils auf der untersten Ebene auseinander setzen muss, selbst um einfache Oberflächen und Service zu implementieren.
Es entwickelte sich zu der Vorgehensweise, dass man es lieber alles schnell selbst machten sollte, als externe Frameworks und Libs zu verwenden. Wenn man nur genug eigene Dinge implementieren würde, würde am Ende schon ein fertiges Frameworks dabei heraus kommen. Das Ein Framework in seiner Gesamtheit durchdacht sein muss und eine gewisse Konsistenz in der Benutzung und im Verhalten zeigt, war dabei egal. Die Idee, jeder Entwickler würde mal so nebenbei für sich ein oder zwei Komponenten entwickeln und wenn man nach einem Jahr alles zusammen wirft, würde ein fertiges GUI-Framework heraus kommen, war zu verlockend und so wurden auch alle komplizierteren Ansätze, die so etwas beachten wollten, als nicht notwendig erachtet.
Wenn man ein auch nicht mehr ganz so neues AngularJS nun betrachtet, dass einmal für die GUI-Elemente auf HTML5 setzen kann und für die Oberflächen eine sehr gute und flexible Template-Engine mitbringt, merkt man erst wie viel Zeit allein mit dem Kampf des SWT-Gridlayouts oder der selbst gebauten Input-Box für Zahlenwerte verbracht wurde.
Das Problem, dass zu viel grundlegende Technologie selbst entwickelt wird und dann alles zu sehr mehr der eigentlichen Anwendungslogik verzahnt wird, ist in so fern ein wirklich großes Problem, als dass hier sehr schnell sehr viel Code produziert wird und durch die fehlende Abstraktion Änderungen mit fortlaufender Zeit immer schwieriger werden. Am Anfang müsste man einige Klassen neu schreiben, aber ein Jahr später, kann man schon die halbe Anwendung weg werfen. Ob man das vielleicht auch tun sollte, werde ich später noch mal ansprechen.
Jedenfalls braucht man entweder jemanden aus dem Team der das Framework für das Team(!) entwickelt und auch die Zeit dafür bekommt oder aber man muss einige Woche am Anfang einplanen, um ein geeignetes Framework zu finden.
Hier lauter schon der nächste Fehler. Oft wird eine Person dazu abgestellt, sich über Frameworks zu informieren und eins oder zwei vorzuschlagen. Da aber viele Entwickler damit arbeiten sollen, sollten auch alle bei dem Findungsprozess mit wirken können. Jeder achtet auf andere Dinge und erkennt Vor- oder Nachteile wo andere nur eine weitere aber nicht so wichtige Komponente sehen. Und auch hier werde ich auf die Probleme,
die hierbei entstehen können, später noch mal eingehen. Es hängt alles zusammen und beeinflusst sich gegenseitig, so führen Probleme zu anderen Problemen.. vielleicht.
Vertrauen in die Technologie muss da sein
Gehen wir mal davon aus, dass wir nun jemanden haben, der das Framework entwickelt oder man eines gefunden hat, das auf dem Papier echt toll aussieht, aber viele Fehler hat und Lösungen dafür kaum zu finden sind.
Das kann an Fehler, einer schlechten Dokumentation oder einem eher ungewöhnlichen Benutzungskonzept liegen. Aber am Ende besteht das Problem, dass die Entwickler dem Framework nicht vertrauen. Das für dann oft auch zu Punkt 1 zurück, in dem dann lieber eine Funktionen und Methoden geschrieben und verwendet werden, weil man diesen mehr traut als dem Framework. Weiter werden dann mindestens 2 Entwickler das Selbe nochmals neu implementieren, aber natürlich dann so verschieden, dass man nicht eines davon wieder abschaffen könnte. Wenn diese mindestens Doppelung an gleicher Funktionalität auffällt, muss das Framework so angepasst werden, dass es mindestens seine und die beiden anderen Funktionsweisen abbilden kann und hoffentlich dabei nichts kaput geht. Dadurch haben wir dann wieder eine große Inkonsistenz Framework, weil es plötzlich Sachen machen soll, die einfach anders sind und anderer Herangehensweisen haben. Weil es inkonsistent geworden ist kommen die Entwickler nicht mehr wirklich damit klar und schreiben sich im besten Falle eine eigene Abstraktionsschicht für das Framework, oder versuchen es wieder zu umgehen, was dann am Ende mindestens die 4. Implementation für die selbe Funktionalität mit sich bringt.
Ich ziehe hier mal wieder AngularJS als positives Beispiel heran. Wenn man ein Problem hat, wird man eine Lösung im Internet finden. Irgendwer hatte das Problem schon und irgendwer hat den Fehler schon behoben, die richtige Vorgehensweise noch mal erklärt oder eine passende Direktive geschrieben. Es stellt sich nicht die Frage, ob etwas an sich möglich ist. Es ist möglich und man versucht es erst einmal und wenn es nicht funktioniert, guckt man eben wie die anderen es gelöst haben. Im Notfall gibt es immer noch das native JavaScript mit document.getElementById().
In Java versuchen Frameworks einen oft komplett in sich gefangen zu nehmen und alle anderen Wege als den eigenen unmöglich zu machen. Durch Interfaces die eingehalten werden müssen, klappt es ganz gut. Das verhindert, dass andere Lösungen entwickelt werden, die das Framework um gehen. Aber es schränkt oft auch mehr ein als es hilft. Das Framework soll dem Entwickler helfen und nicht über ihn bestimmen. Als Entwickler mag man es nicht, nur die Konzepte und Denkweisen eines anderen unterworfen zu sein, der, wie man schnell merkt, das ganze nicht mit dem Anwendungsfall im Hinterkopf entwickelt hat, den man selber gerade umsetzen möchte.
Deswegen muss ein Framework alles bieten und so flexibel sein, dass auch Abweichungen vom Konzept möglich sind und sich direkt ins Framework integrieren lassen, dass es zu einem Teil des Frameworks wird. So wird verhindert, das Entwickler das Framework umgehen oder eigene Lösungen einbauen, die zwar den Anwendungsfall entsprechen aber sich komplett als Fremdkörper im Framework präsentiert. Das wichtigste ist aber eine gute Doku und eine zentrale Stelle wo man Probleme zusammen beheben kann. Für ein eigenes Framework ist daher ein Forum im Intranet vielleicht gar nicht so verkehrt. Man kann suchen, nachlesen und diskutieren. Auch weiß der Entwickler des Frameworks, wo er die Dokumentation verbessern oder nochmal überarbeiten sollte. Auch werden Ansätze etwas neu zu schreiben oder zu umgehen schneller erkannt und es kann mit Aufklärung oder Fehlerbehebung und neuen Features darauf reagiert werden.
Ich habe auch schon erlebt, dass ich von einer Lösung erfahren habe, wie man etwas im Framework bewerkstelligen kann und ein Ergebnis erhält wie man es möchte und das auch schon von einige Entwicklern so eingesetzt wurde und die auch ganz Stolz auf diese Lösung waren. Das Problem war nur, dass das Framework an der Stelle eigentlich genau das liefern sollte, was die über Umwegen dann auch bekommen haben und eine einfache kleine
Meldung bewirkt hätte, dass aufgefallen wäre, dass es ein einfacher Bug im Code war, der dann auch in 5min behoben war. Aber dadurch dass eine alternative Lösung jetzt ein falsches Ergebnis erwartete, war es viel Arbeit alles mit der Fehlerfreien Komponente des Frameworks wieder zum laufen zu bekommen.
Da fehlte dann auch das vertrauen ins Framework. Denn wenn man Vertrauen hat und etwas nicht wie erwartet funktioniert, geht man von einem Bug aus und nicht von einem normalen Verhalten, dem man selbst entgegen wirken muss.
Entscheidungen überdenken und schnell reagieren
Manchmal klingt etwas sehr gut und die Beispiele liefen gut und die Tutorials im Internet ging schnell von der Hand. Entität anlegen, laden, ändern, löschen und eine Liste der vorhandenen Entitäten laden. Alles super.
Aber dann kommt die Komplexität der echten Welt, wo man nicht nur Listen lädt und etwas hinzufügt oder ein Element hinzufügt. Hier beginnen Probleme und manchmal zeigt sich erst hier, ob dass alles wirklich so gut war wie gedacht. Bei JavaFX kann ich einfache DTOs in Tabellen verwenden. Wenn sich aber ein Wert in einem der DTOs ändert wird es nur erkannt, wenn es ein Property ist. Das ist dann plötzlich ein Sprung von "geht ja ganz einfach" zu "jetzt muss alles in Properties umkopiert werden und die normalen Getter und Setter reichen nicht mehr und also doch wieder eine Wrapper-Klasse bauen."
Oder wir treffen auf das Problem aus Punkt 1. Entweder probieren wir es erst einmal weiter und bauen erst einmal eine Version und damit und gucken dann mal oder aber wir haben uns doch am Anfang darauf festgelegt und die Entwickler haben gerade gelernt damit umzugehen.. oder aber ganz radikal: Zusammen setzen, noch mal Alternativen suchen und wenn es was gibt schnellst möglich wechseln. Erstmal mit einer nicht passenden Technologie oder so einem Framework weiter zu arbeiten ist das schlimmste was man machen kann. Denn es müssen Teile neu geschrieben und angepasst werden und dass sollte man machen, wenn noch nicht zu viel davon entstanden ist. Wenn man ein Jahr wartet, wird es zu viel und die Ansicht wird sich durch setzen, dass fertig machen nun doch schneller geht als "neu" machen. Es wird aber mit den Jahren immer langsamer und langsamer entwickelt und es zeigt sich, dass die Annahme falsch war und man doch schon viel weiter wäre, wenn man gewechselt hätte.
Nie mit etwas entwickeln was Probleme macht ohne das die Möglichkeit gegeben ist, das entwickelte später in einem besseren Technologie-Kontext weiter verwenden zu können. Hier Zahlt sich Abstraktion wie MVC/MVVM oder auch einfaches Databinding dann schnell aus, wenn man mit einfachen DTOs und POJOs gearbeitet hat.
Hier ist aber oft die Angst vor dem Mehraufwand und auch vor neuen Technologien das Problem, was die Entwickler daran hindert, schnell und angemessen zu reagieren. Denn die Entwickler kennen fehle Technologien und Frameworks und können bestimmt eine oder zwei Alternativen nennen. Man sollte immer dafür offen sein, dass es etwas besseres gibt und vielleicht ein Umstieg die Zukunft einfacher macht. Auch ohne zu große Probleme sollte so ein Vorschlag immer mal wieder überdacht werden. Es kann auch helfen sich andere Lösungen anzusehen und davon zu lernen in dem man Konzepte übernimmt (wenn diese dann in die alte Struktur passen!)
Ich habe bei meinen Frameworks, die ich so geschrieben habe gelernt, dass man manchmal einfach alte Dinge weg werfen muss, Kompatibilität gut ist aber nicht bis in die Steinzeit reichen muss und man teilweise ein neues Framework anfängt, dass alles besser machen soll und am Ende portiert man es in das alte Framework zurück und wundert sich wie flexibel man das erste doch entwickelt hat, dass man die Konzepte am Ende auch dort in wenigen Stunden komplett implementieren konnte.
Mutig sein und Entwickler dafür abstellen sich auf dem Laufenden zu halten und die Aufgabe zu geben Vorhandenes zu hinterfragen und zu kritisieren.
Die eine zukunftssichere Technologie
Damit kommen wir direkt zum nächsten Problemkomplex. Es wird analysiert und diskutiert und sich für eine Technologie entschieden. Das geht auch erst einmal ganz gut und so lange niemand danach über den Tellerrand schaut bleibt auch alles gut.
Um eine Technologie für ein Projekt, das auch mal mehrere Jahre laufen wird, muss sie stabil sein, gut zu benutzen, es darf sich nichts groß an ihr ändern, damit man nicht dauernd alte Module anpassen muss und sie sollte gut unterstützt werden (also schon viel im Internet darüber zu finden sein). Das alles ist am Anfang gegeben. Aber es soll ja auch so bleiben. Eine Technologie bei der sich in 3 Jahren nichts mehr groß ändern wird ist an sich tot. Was vor paar Jahren noch sehr toll war z.B. SOAP-Webservice über Annotationen zu erzeugen wird heute keiner mehr wirklich benutzen wollen. SOAP war mal komfortabel, wirkt heute aber einfach umständlich im Vergleich zu REST-Services.
Es gibt keine Technologie, die über Jahre hinweg die beste und einfachste Lösung bleibt. Man kann sich aber auch modernen Entwicklungen nicht komplett entziehen. Das Grundsystem wie der Application-Server und das GUI-Framework sollten immer bei neuen Versionen mit geupdatet werden. Es bedeutet nicht, dass die produktiven Server jedes mal ein Update erhalten müssen, aber die Anwendung sollte immer auch auf der aktuellsten Version laufen können. Das kostet den Entwickler natürlich immer etwas Zeit, aber sollt wirklich mal ein Wechsel der Produktivumgebung anstehen, wird dies wenigstens kein Problem mehr sein und es entsteht kein Zeitdruck alles
doch noch schnell auf die neue Version anzupassen. Wir wissen ja das solche Ankündigen nie rechtzeitig vor her kommuniziert werden.
Es muss nicht immer eine neue Technologie sein, aber wenn man bei der Entwicklung der benutzen Technologie nicht mit macht wird man schnell Probleme bekommen und von allen Vorteilen der neuen Versionen nicht profitieren können. Das deprimiert die Entwickler und gibt denen das Gefühl, als würde man ihnen bewusst Steine in den Weg legen. Man siehe nur den Wechsel von EJB2 auf EJB3.
Jeder Entwickler ist anders
Wir brauchen ein Konzept, damit nicht alles wild durch einander geht und jeder so programmiert wie er gerne möchte und kein Modul aussieht wie das anderen. Also soll jemand festlegen, wie der Code-Style, die Packages und die Oberflächen auszusehen haben. Das geht natürlich ganz schnell, es wird programmiert wie man es selber machen, weil man ist überzeugt von seinem vorgehen und man selbst kommt damit ja super zurecht. Oberflächen guckt man sich seine Anwendungsfälle an... andere werden ja wohl keine Anwendungsfälle haben, die sich von der Struktur her groß unterscheiden. Aber leider dreht sich die Welt nicht um einen. Jeder kommt mit seinen Sachen gut zurecht, sonst hätte man es ja schon längst geändert. Also muss man davon ausgehen, dass auch der der die Dinge entwickelt hat, mit denen wir nicht zurecht kommen, damit super zurecht kommt. Also sich im Team zusammensetzen und am Besten mit offenen Standards anfangen. Ein Tab ist fast immer 4 Zeichen lang. Warum sollte man 3 nehmen? Eine persönliche Vorliebe, weil man ein besseres Lesegefühl dabei hat? So etwas hat sich nicht umsonst durchgesetzt und es haben sich Menschen Gedanken gemacht. Wichtig ist zu realisieren, dass vor einem schon andere Leute über solche Dinge nachgedacht haben und diese Leute auch nicht dumm waren oder sind. Wer glaubt er hätte die einzige wahre Lösung gefunden und jegliche kleine Abweichung wäre falsch, der sollte alles wegwerfen und noch mal von vorne beginnen.
Das Framework sollte verschiedene Ansätze von sich auf unterstützen. JavaFX mit Objekten, FXML, HTML im Web-View und auch sonst noch die alte SWT-Variante. Klingt nach viel, aber es gibt für jeden dieser Ansätze einen Anwendungsfall wo er besser als der Rest ist. Das Framework sollte den Entwickler unbemerkt dazu bringen, dass egal wie er an die Aufgabe heran geht, der Code am Ende den der anderen Entwickler ähnelt. Gleich wird der Code nie sein. Es ist schwer so ein flexibles Framework zu entwickeln, wo sich jeder ransetzen kann und ohne viel Lernen und Anpassungen damit anfangen kann zu entwickeln. Databindung oder direkt Zugriff auf das Element.
POJOs oder komplexe Beans. Wiederverwendbare Komponenten oder eine Komponente aus einzelnen kleinen Komponenten direkt beim Aufbau der GUI konstruieren. Alles ist manchmal nötig und manchmal ist das Gegenteil der bessere Weg. Aber nie ist eines davon an sich falsch. Jeder Entwickler ist anders und geht anders an Probleme heran und in einem Projekt sollte es nie so sein, dass sich die Entwickler darin an einen anderen anpassen müssen, weil sie dann nicht mehr die Leistung bringen, die sie könnten.
Unit-Tests
Unit-Tests sind meiner Erfahrung oft eher Belastung als eine Hilfe. Ein wirklich guter Test braucht Zeit und meistens sind diese Test nichts weiter als Entität speichern, laden, freuen, dass der selbe Wert drin steht, wie beim Speichern. Bei Berechnungen sind die Tests super, weil man schnell prüfen kann, ob eine Berechnung noch korrekt ausgeführt wird. Aber für komplexe Workflows und Anwendungsfälle sind diese Tests meistens sinnlos. Ein paar gute Tester bringen mehr als Unit-Tests. Lieber keine oder wenige Unit-Tests und dafür genug Tester haben. Ein Tester ist ein Mensch und für Schnittstellen, die von Menschen verwendet werden, sind Menschen die besseren Tester,
weil sie an Dinge unterschiedlich heran gehen. 2 Tester können eine Workflow-Schritt durch testen und 2 unterschiedliche Fehler finden, während der Entwickler ohne Fehler getestet hat.
Bloß weil etwas toll ud hip ist, ist es für das eigene Projekt nicht auch immer die beste Lösung. Man muss gucken, ob es einen etwas bring und sich klar sein, dass es nicht die eine richtige Lösung für alles gibt. Unit-Tests für Services sind toll und für GUIs meistens vollkommen unbrauchbar.
Dokumentation ist genau so ein Thema. Ein freier Text kann viel mehr erklären wie ein JavaDoc, wären JavaDoc toll ist während des Programmieren kleine Infos zur Methode zu erhalten. Aber brauch ich eine Info was die Methode load($id) macht?
Team-Leader und Lead-Developer als Unterstützung und nicht als Diktatoren
Ich hatte ja schon mehr Mals im Text erwähnt, dass man viele Dinge im Team klären muss und nicht eine Person, wichtige Dinge für alle entscheiden lassen sollte. Es ist die Aufgabe eine Lead-Developers das Team zu fördern und die Leistung zu steigern und dem Team die Probleme vom Hals zu halten. Es ist nicht die Aufgabe des Teams alles zu tun um dem Team-Leader zu gefallen. Lead-Developer und Team-Leader sind undankbare Jobs und man muss sie machen wollen. Wenn man das nicht will und nur etwas mehr zusagen haben möchte, ist man dort falsch. Auch wenn man nur immer zu allen "Ja" sagt, was von oben kommt und dann die Probleme direkt nach unten zum
Team leitet.
Wenn das Team das Gefühl hat sich in bestimmten Situationen nicht auf den Team-Leader verlassen zu können, hat man ein Problem. Es muss deutlich sein, dass er Verantwortung übernimmt und hinter oder besser noch vor seinem Team steht.
Das selbe gilt für den Lead-Developer und seine Entscheidungen. Er muss Erfahrung haben und seine Entscheidungen erklären können und auch die Verantwortung dafür übernehmen, wenn er eine falsche Entscheidung getroffen hat und den Mut haben diese zu Korrigieren. Wenn also ein falsches Framework ausgewählt wurde mit dem kein Entwickler zurecht kommt, ist es sein Fehler und nicht der Fehler der Entwickler. Dann muss er handeln und
den Fehler beheben.
Fazit Das waren jetzt meine groben Gedanken zu dem Thema und meinen Erfahrungen. Es ist aber klar, dass zur Behebung eines Problems erst einmal das Gespräch gesucht werden muss, denn die Entwickler wissen schon meistens sehr genau was schief läuft. Eine Lösung für das Problem müssen die aber deshalb nicht präsentieren können. Wenn nicht ganz klar sein, sollte wo das Problem liegt und man wirklich mit dem Projekt in Bedrängnis kommt, sollte man sich jemanden holen der Erfahrung hat und solche Situationen kennt und am besten mal durchlebt hat. Auch hier wieder die Feststellung, dass vieles immer sehr ähnlich ist und man von den Problemen und Fehler der anderen oft sehr viel lernen und dann verwenden kann.
Solche Leute sind nicht günstig, aber wenn man mal dagegen rechnet wie viel Zeit eingesperrt werden kann, sind die oft ihr Geld wert.
Probleme innerhalb des Teams könnte auch da sein. Aber das ist ein sehr sensibles Thema und dort gibt es noch weniger als bei den deren Problemfeldern keine einfache Lösung.
Du kannst keinen klaren Gedanken mehr fassen? Du hast das Gefühl dein Gehirn wäre geschmolzen und nur noch ein Haufen Matsch? Du hast eine komplexe Klassen-Struktur im Kopf und wunderst auf dem Weg zum Auto warum dein Autoschlüssel sich da nicht richtig einfügt?
Dann hast du wohl denn ganzen Tag Doku geschrieben.
Doku schreiben schlaucht einen irgendwie immer extrem. Endlose Listen von Klassen, die man alle beschreiben soll. Bei den meisten ist vom Namen her schon eigentlich klar was die machen und bei den wenigen Ausnahmen, weiß man nicht wie man es gut Beschreiben soll oder ob man gleich refactoren sollte.
Der der das Projekt übernimmt soll ja möglichst ohne die Doku damit zurecht kommen. Die Doku sollte nur zur Einleitung und bei Unstimmigkeiten bemüht werden.
Nach ein paar Wochen intensiven Doku-Schreibens habe ich mir folgende Regeln aufgestellt:
* Pausen machen und abschalten. Dann noch mal in Ruhe das davor geschriebene nochmal lesen bevor man weiter macht
* Die Punkte für den Tag aufschreiben und abarbeiten
* dazu am Besten noch sich den Roten-Faden vorher auf schreiben (habe ich am Anfang nicht gemacht und bereue ich jetzt sehr)
* Sich lieber mal wiederholen als irgendwelche Verweise auf andere Textstellen einbauen
* Immer auch beschreiben, warum etwas so gemacht wurde und welche Überlegungen und Ideen dahinter stehen
* Wenn man auf nicht mehr verwendete Klassen, Code, etc trifft.. sofort löschen
* lieber Refactoring als viel Text schreiben nur weil man bei einem Namen einer Klasse mal nicht gut überlegt hatte
* 10min schreiben oder 10min etwas aufräumen und in 5min beschreiben? Immer das zweite, denn dem der das Projekt übernimmt wird dadurch mehr Zeit sparen als du mehr aufgewendet hast
Was die Pausen angeht frage ich mich auch immer wieder, ob so etwas nicht fest zur Arbeitszeit dazu zählen sollte. Die Pause um den Kopf wieder so frei zu bekommen um gut weiter arbeiten zu können und Geschriebens noch mal mit Abstand neu zu betrachten geschieht nicht einfach so neben bei. Manchmal ist Pause machen schwieriger als weiter zu arbeiten, weil man sich zwingen muss jetzt an was ganz anderes zu denken... dann bleibt auch die Frage an was man dann denken soll.
Wie macht man effizient Pause?
Da ich mich momentan verstärkt wieder im PHP-Umfeld rumtreibe, bin ich über diese Auflistung von Tipps/Regeln für Programmierer gestolpert, die viele Probleme sehr genau erkennt. Aber meiner Erfahrung nach wird oft genau entgegen gesetzt dazu gehandelt und diese Lösungen den regelkonformen auch oft vorgezogen.
Zu 1. Technologie ist nur das Tool, aber nicht die fertige Lösung Oft wird am Anfang eines Projektes eine Technologie gewählt und es wird Erfahrungen damit gesammelt. Bei den nächsten Projekten wird diese Erfahrung höher eingestuft, als die Erleichertungen, die andere Technologien bieten würde. Grundsätzlich kann immer mit jeder Technologie fast alles lösen, aber jede Technologie wurde mit einem bestimmten Augenmerkt entwickelt. JavaFX ist z.B. toll um vorhandene
Desktop-Anwendungen zu erweitern oder zu er setzen. Beim Versuch eine komplexere Webanwendung durch eine JavaFX-Anwendung zu erstzen wird man eher scheitern, weil die Konzepte einfach zu weit auseinander sind.
Zu 2. „Geschickt“ ist der Feind von „eindeutig“ Es gilt irgendwie die Annahme, dass es eine einfache Lösung schnell überlegt ist und wenn man länger nachdenkt eine komplexe Lösung dabei raus kommt. Ich würde behaupten, dass es genau anders herum ist. Erst wenn man alles ausreichend durch schaut hat und verschiedene Lösungswege durch gegangen ist, kann man etwas auf das Elementare herunter brechen. Nach 2h nachdenken wird die Lösung einfacher und klarer als, als wenn ich das erste nehme was mir nach 2min in den Kopf kam.
Zu 3. Nur dann Code schreiben, wenn es wirklich nötig ist Hier würde ich nicht nur unnötigen Code und unbenutzte Funktionen aufführen sondern auch Templates, wenn es um die Darstellung geht. Es ist schlecht und bringt mehr mögliche Fehlerquellen mit, wenn ich Dinge die ich mit einem Template erledigen könnte im Code formulieren müsste. HTML-Tables + CSS in Kombination mit z.B. AngularJS ist sehr viel Übersichtlicher und da durch weniger fehleranfällig als z.B. ein TableView in JavaFX wo ich für jede Zeile und Spalte einen eigenen Renderer schreiben muss, wenn es über die einfache Darstellung eines String hinaus geht. Jeder Renderer implementiert ein bestimmtes Interface oder leitet einen schon vorhandenen Renderer ab, der wiederrum Code enthält den man nicht kennt und der aber in Wechselwirkung mit dem eigenen Code auch mal lustige Seiteneffekte haben kann. Eine Hintergrundfarbe zusetzen mit einer Angabe im style des TD oder dafür einen Renderer schreiben macht nicht nur zeitlich einen Unterschied sondern sorgt auch für viel mehr Code und weniger Übersicht.
Zu 4. Kommentare sind meist „böse“ Kommentare sind nicht verkehrt, aber meistens nutzlos und machen alles Unübersichtlich. Oft hört man "man braucht mindestens einen Kommentar der beschreibt wozu die Methode da ist. Weil wenn du nach einem halben Jahr dir deinen Code wieder ansiehst weißt du dass oft nicht mehr." FALSCH! Wer Methoden schreibt, die er nach 6 Monaten nicht mehr zuordnen kann, macht grundsätzlich etwas falsch. Zu glaube man würde vergessen was loadArticleById($id) macht, ist genau so weltfremd. Wenn man Methoden und Klassen richtig und beschreibend benennt, wird jeder der den Namen liest auch verstehen, was da passiert ohne die Implementierung betrachten zu müssen. Also keine Abkürzungen verwenden und lieber längere Namen verwenden. Wenn man das macht wird man auch loadArticleByCategoryIdAndMaxPrice($catId,$maxPrice) verstehen. Die ganz extremen wollen auch Kommentare an jedem Getter und Setter sehen, aber da wird nicht erklärt was das zu setzende fachlich bedeutet sondern nur das dort was gesetzt wird.
Also zu glauben das unnütze Kommentare besser sind als gar keine Kommentare ist meiner Meinung nach falsch.
Zu 5. Vor dem Code-Schreiben wissen, was der Code bewirken soll Am Ende muss man die Anforderung verstanden haben. Da muss richtig Kommuniziert werden. Aber selbst wenn man es falsch versteht... niemand wird anfangen eine Methode zu schreiben, ohne zu wissen was am Ende dabei raus kommen soll. Allein wenn man sich den Methodennamen überlegt, wird man diesen Schritt ja schon erfüllen.
Zu 6. Code testen, bevor man ihn an das Qualitätsmanagement weitergibt Entwickeln und Testen kann man nicht trennen. Wer Entwickelt muss, dass es auch testen. Alles andere würde auch unnötig Zeit kosten. Einen abschliessenden Test sollte dann jemand anderes machen. Aber die grundlegenden Tests kann man nicht auslagern.
Zu 7. Jeden Tag etwas neues lernen Jeder kennt einen oder mehrere, der oder die mal vor Jahren etwas gelernt haben und seit dem alles immer damit lösen. Leute die immer Desktop-Anwendungen gebaut haben und Server irgendwie noch akzeptieren aber Webanwendungen für totalen Unsinn halten.
Das ist immer kein Problem, solange diese Personen nicht große Entscheidungen für ein Projekt zu treffen haben. Dann wird schnell ein Web-Client abgelehnt, weil JavaScript dynamische Typsierung nutzt. Allgemeine Tendenzen bei Entwicklungen sowie so komplett ignoriert und als Unsinn bezeichnet, wenn jemand mal was in die Richtung vorschlägt. Es wäre alles Unsicher, man hätte keine Erfahrungen, es müsste sich erst einmal zeigen ob es sich durchsetzen wird (das habe ich erst vor kurzen zum Thema Multithreading gehört), usw. Sich was neues mal wenigstens anzusehen, wird als Zeitverschwendung gesehen und mit den alten Sachen, die man schon immer nutzt, würde da ja auch irgendwie gehen. Auch wenn man die alte Technologie nutzen kann, die neuen
Konzepte bringen trotzdem oft etwas, und wenn es nur eine neue Sichtweise ist, warum etwas weiterhin so mach wie bisher.
Zu 8. Nicht vergessen: Code schreiben macht Spaß Hier merkt man eindeutig, dass der Original-Text nicht aus Deutschland stammt. Programmieren ist eine erste Sache! Wer bei der Arbeit Spaß hat, der erledigt seinen Job ja offensichtlich nicht richtig.
Wenn man einfach und schnell zum Ziel kommt, macht es Spaß und die Qualität von Dingen die mit Spaß an der Sache gemacht werden ist meistens sehr hoch. Aber bei allen was auch so intern an Frameworks oder Libs entwickelt wird, ist leicht und schnell nie ein Argument warum etwas benutzen sollte. Leicht zu verstehen muss nichts sein, man könne ja die rudimentär vorhandene Anleitung lesen.
Anleitungen lesen ist genau so Spannen wie Kontoauszüge lesen.. was aber in Deutschland wohl immer noch als super lustige Freizeitbeschäftigung gilt. Ich habe genug interne Frameworks und Libs erlebt die einfach schrecklich zu benutzen waren. Sie machten was sie sollten, aber die Zeit um die benutzbar zu machen, galt gleich wieder als sinnlose Zeitverschwendung.
Man muss den Spaß am Programmieren sich bewahren und wenn das am Ende mit privaten Projekten umgesetzt wird.
Zu 9. Man kann nicht alles wissen Das kann man nicht. Man muss nur wissen wo man suchen oder wen man fragen muss. Es gibt nur ganz wenige, die meinen, dass das was sie nicht wissen, damit auch gleichzeitig unbedeutend wird. Einen guten Programmierer macht nicht aus alle Klassen-Referenzen und Protokoll-Spezifikationen auswendig zu kennen. Aber wenn man etwas nicht weiß, kann es lernen und das ist leider auch immer Arbeit.
Zu 10. Best Practices hängen vom Kontext ab Web-Anwendugnen brauchen andere Best Practices als Desktop-Anwendungen. Java ist anders als PHP. Es gibt immer viele Überschneidungen aber am Ende machen es auch gerade die kleinen Unterschiede aus. In Java sollte man den Application-Scope verwenden und nicht die Session, wenn man für die gesamte Anwendungen einmal etwas laden/parsen muss. In PHP sollte man die Session verwenden, weil es nichts auf Applikationsebene gibt.
Wenn jemand Best Practices erstellt und meint es wäre jetzt die Lösung für alles, kann man davon ausgehen, dass es mit etwas Glück für einen Fall passt oder eher für gar keinen.
Zu 11. Immer nach Vereinfachung streben Wie schon weiter oben beschrieben wird leider oft einfach mit schnell verwechselt. Um eine einfache und gute Lösung zu finden braucht man Zeit und die sollte man sich nehmen dürfen. Die Zeit wird man am Ende wieder einsparen, weil der Code dadurch viel einfacher zu pflegen und zu erweitern ist.
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: