Wenn man in der Storefront an einem eignem JavaScript-Plugin arbeitet ist es beim Debuggen, oft nervig, dass der JavaScript Code nicht direkt lesbar ist. Oft weiß man beim eigenen Code direkt was los ist, aber gerade wenn 3rd Party Plugins auch mit rein spielen, kommt man nicht drum herum sich Exceptions mit lesbaren Stacktrace anzeigen zu lassen.
Das ist zum Glück extrem einfach:
* Port 9998 aus dem Docker-Container durchleiten
* Dem SalesChannel in dem man entwickelt die Domain "localhost" zu ordnen
* das Script bin/watch-storefront.sh starten
Nun kann man localhost:9998 im Browser aufrufen. Der JavaScript Code ist lesbar und Änderungen werden sofort übernommen ohne dass man die Storefront neu bauen muss.
Ich arbeite nun doch schon einige Zeit mit Shopware 6. Während ich am Anfang vielen Konzepten etwas kritisch gegenüberstand, bin ich nun doch sehr von fast allen Dingen überzeugt. Ich habe viele verschiedene Dinge schon mit Shopware 6 realisiert und einiges wäre in Shopware 5 nicht so einfach gewesen.
Gerade Vue.js in der Administration ohne irgendwelche zusätzlichen Lizenzen nutzen zu können ist super. Ich mochte immer Vue + Bootstrap und Symfony. Also am Ende fühle ich mich so was von extrem in meinen Vorlieben bestätigt... wenn auch Shopware diese Kombinationen nutzt muss ich ja schon immer richtig gelegen haben :-)
Varianten sind immer noch viel zu kompliziert. Daten in das Model für Emails rein zubekommen ist wirklich viel zu umständlich. N:M Relation in DAL ist umständlich bzw wie früher mit puren SQL. Entweder alles vorher löschen oder sich merken was genutzt wird und alles was nicht dazugehört löschen. Aber am Ende kommt man ja gut damit klar... ist eben wie mit JDBC oder PDO direkt zu arbeiten und dass habe ich lange genug gemacht.
So.. aber was kann man alles mit Shopware 6 so alles bauen? Ich habe bis jetzt nur für Kunden direkt entwickelt und falls jemand etwas hier von gerne hätte, geht das leider nur über Anfrage und dann wird ein Angebot erstellt.
1. Adressänderungen verhindern Wie schon bei Shopware 5 war es nötig, weil SAP sonst überfordert ist.
2. Register-Form erweitern Das zu Erweitern war am Ende sehr viel einfacher als gedacht und ich nutzt einfach das Data-Mapping Event für den Customer. Der richtige Weg? Für mich funktioniert er gut.
3. Blog Einträge Das kostenlose Blog-Plugin ist schon echt super. Es fehlt nur ein Flag um Posts von er Suche auszuschließen, Typen, Rechte über Rules und Datei-Anhänge. Ja.. ich weiß.. ich könnte mich da beteiligen und alles einbauen.. sollte ich wirklich machen. Aber bis jetzt war nur Zeit das Plugin zu erweitern um Rezepte aus einem Panipro-System zu importieren.
Typen sind natürlich dynamisch und es werden nur Typen auf der linken Seite angezeigt, die auch gefunden wurden.
4. Bonuspunkte und passende Produkte Produkte die man nur oder auch gegen Bonuspunkte kaufen kann. Das war etwas komplexer und man musste über Collector und Processor des Carts eingreifen. Heute würde ich wohl einiges ein wenig anders machen, aber nicht viel und auch nur minimale Änderungen.
5. Konfigurator Style #1 So kann man sich z.B. Geschenkkörbe oder PCs/Notebooks konfigurieren. In der Administration kann man sich ein Config-Preset anlegen und es verschiedenen Products zuordnen.
6. Konfigurator Style #2 Ein Produkt das z.B. Hackfleisch beinhaltet so konfigurieren in welchen Formen man das Hack gerne geliefert bekommen würde. Wurde als Teil von Punkt 7 entwickelt.
7. Paket verkauf Erst alle Pakete verkaufen und dann erst das Tier schlachten. Spart Lagerkosten und andere Aufwände. Hier habe ich gelernt warum Varianten noch immer umständlich sind und CustomFields zu syncen zwischen Varianten schlechter ist als eine eigene Entity dafür zu erstellen. Aber die Anforderungen waren zuerst so das CustomFields die einfacher Lösung waren.
Ich musste mir eine sw2-Datenbank anlegen über root/root, aber an sich sollte es wie in meinem SW5-Environment auf mit der sw-Datenbank und sw/sw gehen.
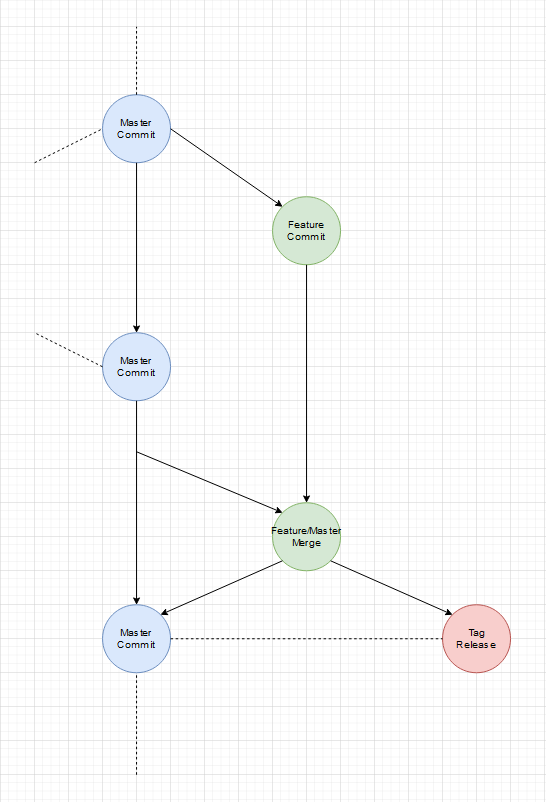
Am Freitag hat mir mein Kollege 2 Links zu Blogposts geschickt, die sich mit der Frage beschäftigen ob Git-Flow in der heutigen Zeit überhaupt noch funktioniert oder ob Git-Flow veraltet ist. Der 1. Blogpost zeigt erstmal nur Probleme auf und enthält keine Lösungen. Es passiert zu leicht das Release-Branches zu lange leben und dann darin selbst Entwicklung geschieht. Es dauert relativ lange bis eine Änderung durch die verschiedenen Branches im Master ankommen und am Schlimmsten ist noch, dass bei parallelen Entwicklungen ein nicht releaster Branch einen anderen aktuelleren, der einfach schneller war, blockiert.
Ja. Das ist jetzt nicht neu. Über diese Probleme habe ich 2009 schon im dem damaligen ERP-Team diskutiert (mein Gott waren wir damals schon modern...). Die Lösung hier ist einfach dass man harte Feature- und Code-Freezes braucht. Auch darf die Fachabteilung nicht erst im Release-Branch das erste Mal die neuen Features sehen. Ich habe es so erlebt. Dann kamen die neuen Anforderungen, Änderungen der gerade erst implementierten Features. Das soll aber so sein. Wenn das so ist braucht man aber auch noch das. Das ist falsch und muss so funktionieren... Alles Dinge die schon viel früher hätten klar sein müssen und erst dann hätte es zu einem Release-Branch kommen dürfen. Der Stand eines Feature-Branchs muss genau so auf einem System für Test und Abnahmen deploybar sein wie ein Release-Branch. Anders gesagt jeder Stand muss einfach immer präsentierbar sein!
Der 2. Blogpost brachte jetzt auch nicht wirklich neue Erkenntnisse, was am Ende der Author auch selbst schreibt.
Ich halte die Darstellung von Branches in parallelen Slots oder Lanes, die in dem Sinne ein Rennen um die Aktualität austragen für vollkommen falsch. Es darf auch nicht den develop-Branch oder den einen Release-Branch geben, der auch dann immer deckungsgleich mit dem Stand des Deployments auf einem System ist. In Zeiten von Docker und Reverse-Proxies zusammen mit Wildcard-Subdomains sind feste Systeme sowie so überholt. Jeder Branch kann ein System haben, auf dem Test, Abnahmen und Dokumentation stattfinden kann.
Das gilt auch für Tags. Branches sind variabel und ändern sich immer wieder. Tags sind statisch und damit perfekt für Zwecke, wo man kontrolliert bestimmte Stände deployen möchte. Tags persitieren einen bestimmten State/Zustand des gesamten Git-Repositories. Branches bilden einen State/Zustand aus der Sicht eines bestimmten Entwicklers oder eines bestimmten Features ab.
Deswegen halte ich feste Branches wie mit festen Aufgaben für komplett falsch. Ein Feature = ein Branch und am Ende steht ein Tag, der den gewünschten State/Zustand persitiert.
Ein einfacher Feature Branch:
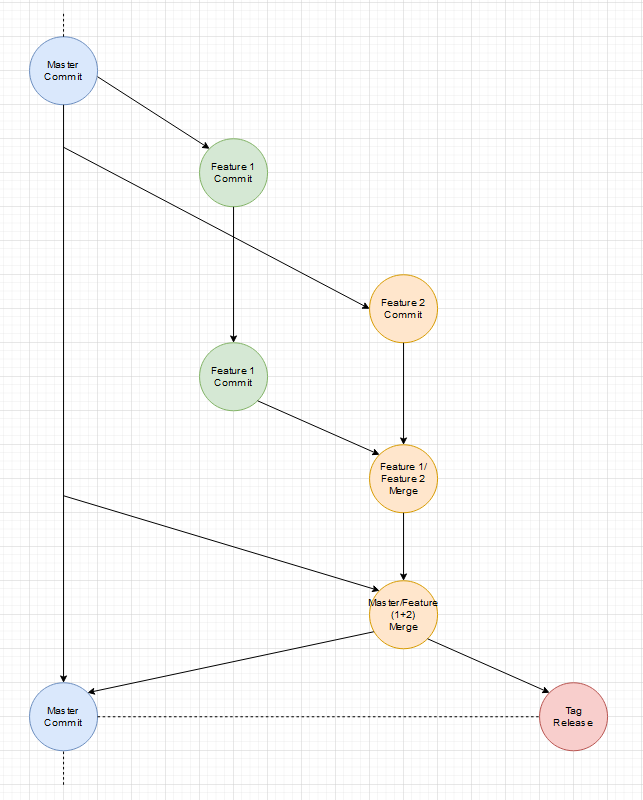
Ja es gibt noch einen Master-Branch, der aber in dem Sinne nur ein 2D Abbild des wilden mehr dimensionallen Feature Raum ist. Wenn wir jeden Feature-Branch als Vektor der auf das einzelne Feature/Tag als Ziel zeigt versteht, ist der Master einfach die Projektion aller Vektoren auf eine Fläche. Diese vereinfachte Projektion hilft Feature-Branches vor dem Release auf den aktuellen Stand (was andere Features und Fixes angeht) zu bringen.
Es gibt auch immer mal Abstimmungsprobleme bei Features, die auf einander aufbauen. Interfaces haben minimale Abweichungen oder ein kleiner Satz in der Dokumentation wurde falsch verstanden. Was also wenn ein Feature doch noch eine kleine Änderung braucht, weil Entwicklungen parallel liefen?
Beides wird gleichzeitig fertig (ein extra Release-Branch wäre möglich):
Das Basis-Feature geht vorher live:
Das bessere und flexiblere Vorgehen
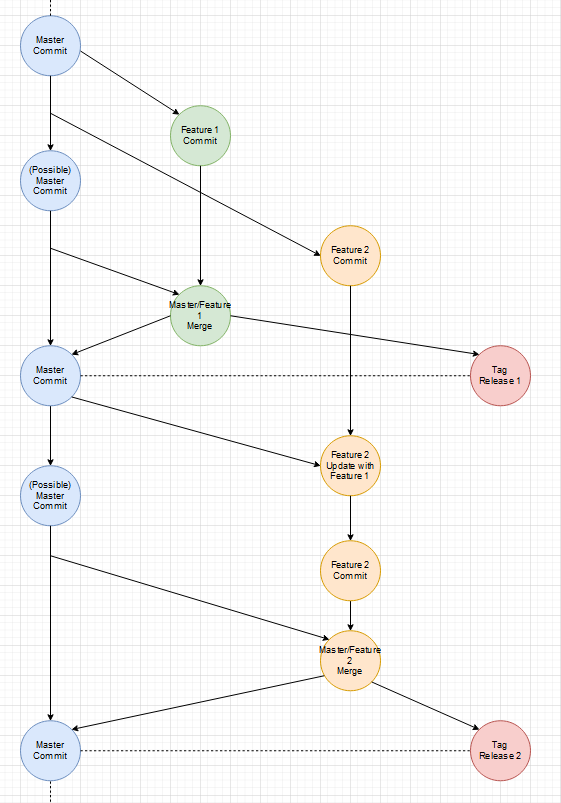
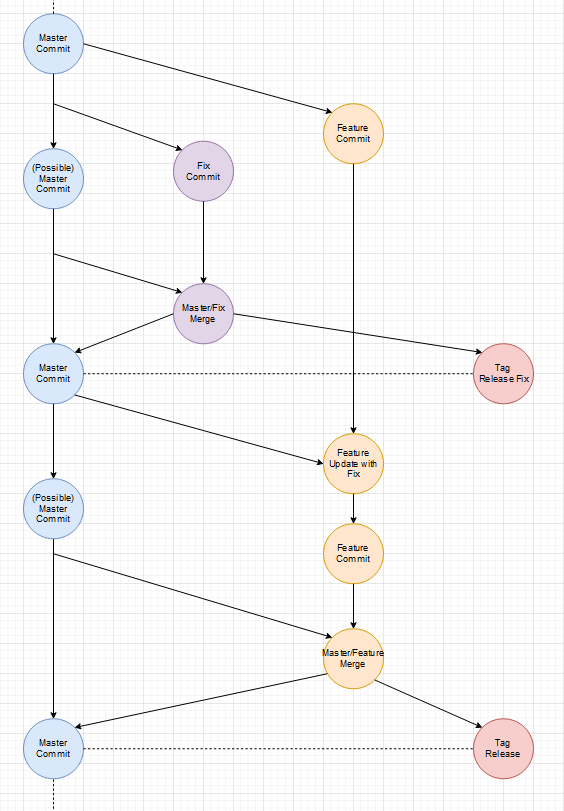
Gibt es einen Unterschied zwischen Fixes und Features? Nein. Beides sind Improvements des aktuellen States/Zustands. Wenn einem in einem Feature-Branch ein allgemeines Problem auffällt, fixt man das Problem und merged den Master mit der neuen Version erneut in den Feature-Branch.
Zwischenzeitlicher Fix:
Es ist an sich kein Unterschied zwischen einem Fix und einen weiteren Feature-Branch, außer dass der Fix-Branch sehr viel kurzlebiger ist und wohl weniger Commits enthält.
Der Master ist immer stable, weil nur Release-Tags darauf abgebildet sind.
Dieses Herangehen macht es sehr einfach jeden State/Zustand auf System abzubilden. Jeder Branch ist unter seinem Namen zu finden und Tags werden nach Typ auf Systeme gemappt.
Tag auf System: - release-XXX auf das produktive System
- staging auf das Staging-System (1:1 Namenabbildung)
- demo1-n auch 1:1 per Namen abbilden
Bei staging muss man den Tag löschen und neu anlegen, so kann jeder Zustand auf dem Staging-System deployt werden oder besser gesagt, wird ein Deployment durchgeführt das dann unter der Staging-Domain erreichbar ist. Hier gibt es eine tolle Anleitung wie man solche Systeme mit Traefik oder Kubernetes ganz einfach bauen kann. Ich werde das aber vielleicht auch noch mal genauer beschreiben, wie ich es für gut halte.
Denn Branches halte ich persönlich es nicht für wert wo anders als lokal in einem Docker-Container zu laufen. Da kann ich um es der Fachabteilung lieber schnell einen Tag erstellen und diesen nach dem Input der Abteilung auch wieder unter selben Namen neu anlegen oder unter einen neuen wenn zwei mögliche Umsetzungen verglichen werden sollen (macht das mal mit Git-Flow!).
Edit: Ich habe die per Hand gezeichneten Diagramme durch vollständigere Diagramme, die per Software erstellt wurden, ausgetauscht.
"Das steht da nirgends drin", "Das ist viel zu ungenau", "ich kann da nicht raus lesen, dass da so etwas gefordert wird"... Userstories. In einer Userstory beschreib ein User was er mit dem Produkt machen will oder wie er das Produkt bedienen will. Jeden Falls kommt die Definition von Userstory oft so rüber. Aber jeder der mal mit einem Anwender zusammen Prozesse aufgenommen hat und sich dabei beschreiben lies, was der Benutzer eigentlich immer macht um zum Ziel zu kommen, weiß dass Benutzer nicht immer die zuverlässigste Quelle für korrekte oder vollständige Informationen ist. Was da manchmal raus kam.. damit will niemand einen Sprint planen. Ich halte Userstories für eine wichtige Sache, aber würde nie eine Userstory 1:1 in Tasks transferieren.
Mir gefällt diese Interpretation der Userstory als Hypothese sehr gut, weil mehr kann eine Userstory nicht sein. Eine Userstory ist der Lösungsweg einer Interpretation eines Problems oder Ziels. Niemand kann bei einer Userstory sicher sein, dass das Ziel richtig verstanden und seine Position im übergreifenden Gesamtbild richtig verstanden worden ist. Ist der Weg im gesamten Prozessablauf sinnvoll und schlank umgesetzt?
Wenn ich eine Userstory direkt von einem Benutzer bekomme, muss diese einfach nochmal gegen geprüft werden. Es gibt immer ein Problem, das zu lösen ist oder ein Ziel, das zu erreichen ist. Gerade wenn es um die Verbesserung eines vorhandenen Produkts geht, wo mehr zu tun ist, als ein paar GUI-Elemente neu zu ordnen, ist bis zur wirklichen Verwendung durch die Benutzer nie klar, ob die erhoffte Verbesserung wirklich eintritt. Oft ist nicht einmal klar, ob es nicht auch ungewollte Nebeneffekte gibt, die nicht bedacht wurden (die aber eingeplant werden müssen).
Man kennt es ja sicher, dass eine Abteilung mit neuen Anforderungen kommt, die alles besser machen sollen und man Tätigkeiten, die man gar nicht bräuchte, entfernt hat. Oft gucken, die dann sehr doof, wenn man denen erklärt, dass diese Tätigkeiten, aber für die nach gelagerten Prozesse in einer anderen Abteilung echt wichtige Daten liefern, die auch nur da her kommen können. Die Userstory war also eine Hypothese der Abteilung, die sich als falsch heraus stellte. Zum Glück noch bevor etwas umgesetzt wurde und es sich im Test oder gar im Produktivbetrieb herausstellen konnte.
Die im Artikel beschriebene Impact-Map bringt genau diese Übersicht mit und zwängt die Userstories in einen direkten Kontext in dem sie viel besser zu beurteilen und zu interpretieren sind sind, als wenn diese allein stehen würden.
- Welches Ziel soll insgesamt erreicht werden?
- Wer ist von diesen Änderungen betroffen? (Abteilungen, Kunden, etc)
- Welche einzelnen Änderungen sollen zum Gesamtziel führen? (Wo gibt es also momentan Probleme und Verbesserungspotential)
Erst dann kommen Epics und Userstories.
So steht über jeder Userstory ein Problem, dass zu lösen ist. Wenn eine Userstory eindeutig, dass Problem nicht löst, setzt man diese nicht um. Ähnliches gilt für Dinge die eindeutig fehlen um ein Problem zu lösen. "Da steht aber nirgends, dass man eine Benutzerverwaltung mit Rollen und Hierarchie will!".. aber es steht da, dass die Bereichsleiter Reports über die Tätigkeiten ihrer Abteilungen sehen wollen. Da würde einfach der wieder der Blick auf die Übergreifenden Prozesse vergessen und nur die Prozesse in den Abteilungen betrachtet. Also fängt man damit an eine Umgebung zu schaffen, bei der man sich Anmelden kann und ein Benutzer-Objekt mit Berechtigungen erhält, bevor man anfängt sensible Ansichten zu bauen, die diese Benutzer-Daten brauchen, um die richtigen Daten anzeigen zu können (und nicht zu viele Daten, die der Benutzer nicht sehen dürfte).
Und am Ende darf man nie vergessen, zu prüfen, ob eine Userstory auch wenn sie logisch klang, den gewünschten Effekt hatte. Dabei muss man schnell prüfen und messen, damit man schnell reagieren kann, um dann wieder rum schnell nachbessern zu können.
Userstories helfen also dabei den Kontext zu verstehen, aber nehmen einen nicht die Hauptaufgabe ab, nämlich als Entwickler eine Lösung für ein Problem zu entwickeln. Der Begriff Softwareentwickler beschreibt nicht was man entwickelt, sondern mit welchen Werkzeug man entwickelt!
Am Ende eines Sprints soll etwas heraus kommen, was man dem Kunden zeigen kann bzw deliverable ist. Kunden an sich können nur sehen was klickbar ist. Dinge die nicht klickbar sind sind für die meisten Kunden einfach nicht existent, weil diese zu meist keine technischen Anforderungen stellen sondern fachliche. Man Klickt etwas an und es passiert was und das ist das was der Kunde sieht und bewertet.
Aber muss es so sein? Es gibt viele Dinge innerhalb eines Sprints, die die Entwicklung und technische Basis voran bringen ohne das ein Anwender sie bemerkt oder sehen kann. Deswegen ist es vielleicht falsch nur den Kunden die Bewertung zu überlassen. Der Kunde muss nur am Ende etwas sehen, das man messen und dann validieren kann.
Angenommen, ich möchte mehr Automatisierung in der UI haben. Formulare sollen sich automatisch erzeugen und nicht mehr per Hand zusammen gebaut werden müssen. Kann ich das in einem Sprint nach der Definition liefern? Ja! Ich baue es ein und liefere dem Kunden am Ende des Sprints einen Mess-Fall. Genau so ob die Änderung die der Kunde sieht er nach dem Spring validiert werden kann, ob der erhoffte Impact eintritt, kann meine technische Änderung genau so zur selben Zeit getestet werden. Zwar nicht durch einen Anwender sondern durch die Daten des nächsten Sprints selbst, aber das Ergebnis ist das Selbe.
Ich liefere etwas und gebe dem Kunden etwas an die Hand, um die Hypothese auf der dieses gelieferte fußt, prüfen zu können. Ich sage, ich kann mit dieser Änderung im nächsten Sprint 6 neue Formulare in der UI liefern und nicht mehr nur 2. Das ist eine gute Annahme, die sich überprüfen lässt. Ob eine andere Userstory, die vom Kunden selbst kommt, am Ende das erhoffte liefert, weis man genau so wenig, wie diese Annahme, mit der ich den Form-Generator eingebaut habe.
Nach dem folgenden Sprint, gehe ich wieder zum Kunden und zeige ihm, was wir an Formularen gebaut haben. Nun prüft er, ob meine Annahme mit 6 Formularen erfüllt wurde. Vielleicht sind es nur 5 geworden oder wir hatten sogar Zeit über, in der wir noch ein Formular mehr hätten machen können... das ist gar nicht ganz so wichtig, weil sich heraus gestellt hat, dass es eine Verbesserung gab und damit meine technische Userstory erfüllt werden konnte und nicht nochmal neu bearbeitet werden oder als Fehlschlag einzustufen ist.
Ob man also klickt oder am Ende Zahlen vorlegt, ist für den Kunden dann egal. Man hat jeweils etwas gebaut, was sich in der Zeit danach bewähren muss und nur das was dann da heraus kommt zählt und nicht was am Ende des Sprint sichtbar war. Deswegen muss ich am ende des Sprints immer nur etwas liefern, was messbar ist. Nicht etwas was direkt sichtbar ist.
Ich bin über diesen Artikel bei Heise-Developer gestolpert und das Thema hat mich gleich gefesselt. Ich vertrete ja immer die Auffassung, dass Komplexität entweder auflösbar ist oder ein Symptom eines unerkannten Fehlers/Problems. Ich halte es auch für eine sehr deutsche Tugend Komplexität zu verklären. Über die Jahre bin ich bei verschiedenen Firmen, Personen und Situationen über sehr komplexe Probleme gestolpert, die aber meistens von den Verantwortlichen mehr mit Stolz gesehen werden, als ein Problem.
Die Aufgabe der IT wird dann immer darin gesehen, dass sie komplexe Probleme, die zu komplex für Menschen sind, handhabbar und bewältigbar zu machen. Dabei gilt auch in der IT, dass eine komplexe Lösung für ein komplexes Problem eine große Sammlung für Point-of-Failure's sind, bei denen die einzelnen Fehler auch wieder eine hohe Komplexität haben. In den meisten Fällen, wäre die IT besser damit beraten, ein Beispiel zu liefern, wie die IT helfen kann einen simpleren Prozess umzusetzen und damit die Effektivität enorm zu steigern.
Leider aber gibt es immer die typischen Ausreden:
- unser Geschäftsfeld ist eben sehr komplex
- es gibt keine Standard Fälle, die unsere nötigen Abläufe abbilden können
- unsere Firma ist eben etwas Besonders und lässt sich nicht vergleichen
- das ist über die Jahre so gewachsen und unser Erfolg gibt uns recht
- wir sind nicht einfach so eine Firma.. wir machen heben uns ab
- wir sind eben innovativ und den Standardlösungen voraus
Bei manchen sieht man sehr gut das Ursache und Begründung an sich nichts mit einander zu tun haben. Aber eindeutig ist, dass man meint sich durch Komplexität einen Mehrwert gegenüber Mitbewerbern herbei zureden versucht. Es wird so getan als müsse Komplexität mit Innovation, Qualität und Alleinstellung einher gehen. Hoch komplexe Fertigungsmethoden beeindrucken natürlich, aber es wird viel zu selten überlegt, ob es nicht viel beeindrucken würde für eine komplexe Aufgabe eine sehr einfache und kostensparende Lösung bieten zu können.
Automatisierung und Digitalisierung.. momentan große Buzz-Words. Firmen die schon immer versucht haben Komplexität zu bekämpfen und ihre Prozesse schlank und einfach zuhalten, haben kein Problem damit etwas bei sich zu automatisieren bzw sind meistens schon damit durch. Das sind auch Firmen bei denen die Mitarbeiter selbst bestrebt sind, stupide Arbeit loszuwerden und sich wirklich wichtigen Arbeiten mit ausreichend Zeit widmen zu können.
Gerade größere Firmen, die an Komplexität als Vorteil oder Aushängeschild festhalten, wundern sich immer, wenn sie von kleinen innovativen Firmen mit viel weniger Mitarbeitern, Geld und Bürokratie in kurzer Zeit überholt werden. Oft hält man dann dort an der Qualität fest, die mit simpleren Fertigungsmethoden oder Prozessen ja nicht gewährleistet werden könne. Manchmal stimmt es, aber ganz oft ist die höhere Qualität auch nur eingebildet und wird allein an den komplexen Prozessen wiederum fest gemacht. Also führt die Komplexität zu hoher Qualität, die man daran erkennt, dass die Komplexität hoch ist.... man dreht sich im Kreis.
Komplexität ist immer schlecht und es gibt keinen Grund an Komplexität fest zu halten. Wenn man Komplexität an einem Punkt nicht los wird, muss man entweder etwas mehr nachforschen und kann dadurch innovativ sein oder in Betracht ziehen, dass man etwas da einfach falsch macht und denn betroffenen Prozess noch mal auch mit Blick von Außen neu planen sollte.
Unnötig Komplex zu sein und zu denken ist 60er/70er Jahre Mentalität, die man möglichst schnell ablegen sollte. Aber dafür muss man Prozesse erfassen und bewerten, mit den Mitarbeitern vor Ort reden und planen, IT nicht als Problemlöser sehen sondern als neuen Weg, der neue Impulse und Ideen liefert. IT ist ein Werkzeug zur Bekämpfung von Komplexität und nicht eins um Komplexität beherrschbar zu machen.
Der Blog liegt leider bei mir gerade etwas brach. Zu viel zu Arbeiten und auch das Haus zieht viel Aufmerksamkeit auf sich. Das Wetter ist eben so gut, dass man den Garten dann gegen Ende doch fast auf dem Niveau hat, das man sich Anfang des Jahres vorgenommen hat.
Momentan steht ein Projekt mit meinem PHP-Framework, ganz oben auf der Todo-Liste. Wenn ich mal das Blog-Modul und das Admin-Panel verbessern würde, kann man es auch über all da einsetzen, wo sonst eher WordPress eingesetzt wird. Aber ist Dabei modular, MVC, Events, etc... also doch noch eher dazu da darin selbst zu entwickeln.
Die Pflege der Shopware Plugins und die Entwicklerer weiter Shopware Plugins ist momentan auch eher zurück gestellt. Wobei dass das ist, was ich dann gegen Ende des Jahres wieder mehr verstärkt betreiben werden.
Zum Ende des Jahres, werde ich mal wieder mehr schreiben. Auch mal wieder etwas mehr über das Thema Arbeit an sich. Druck, Arbeitszeitmodelle und so, da ich in letzter Zeit doch öfters in nicht immer positiver Weise damit konfrontiert wurde.
Wobei man natürlich auch Garten heutzutage nicht ohne IT auskommt (Temperatur-Überwachung).
Auch wenn ich vieles was John Sonmez so sagt, sehr kritisch sehe (Burnout gibt es nicht, man hat nur nicht genug Disziplin.. oder um mehr Zeit zu haben sollte man einfach weniger schlafen) muss ich sagen, dass ich gerade in seinen Artikel von so vor 3 - 2 Jahren sehr viel gelernt und verstanden habe. Es war gerade eine Zeit bei mir wo ich sehr motiviert und auch engagiert an einen Projekt gearbeitet habe. Zuvor war ich Teil von einem doch relativ großen Team, wo alle Probleme und Fehler, die bei großen Teams vorkommen, gerade durch exerziert wurden. Mit einem kleineren und sich damit schneller entwickelten Projekt war ich sehr zufrieden und versucht meine Vorstellung von Vereinfachung und beschleunigter Entwicklung da einfließen zu lassen. Leider scheiterten viele dieser Bemühungen an der Skepsis vor neuen Technologien und der Situation, dass man nicht wirklich Zeitdruck hatte und das sparen von Zeit deswegen nicht wirklich ein Argument war.
Zur selben Zeit versuchte ich die gelernten Lektionen und meine Ideen, die ich dort nicht umsetzen konnte, privat in Text und manchmal auch Code zu konservieren, damit man in späteren Zeiten doch mal darauf zugreifen konnten. Außerdem war damit auch die Hoffnung verbunden von anderen Entwicklern und Firmen beachtet zu werden und irgendwie auch Bestätigung zu bekommen. Der Simple Programmer Blog traf zu der Zeit also bei mir einen Hauptnerv. Einmal wurde dort mein Verständnis davon bestätigt, dass die einfachste (also unkomplexeste Lösung, "Don't be smart!") meist auch die beste Lösung sei und auch wurde dort das Gefühl fest zu stecken und sich nicht mehr weiterentwickeln zu können oft thematisiert.
Dem ersten Tip hatte von mir aus schon umgesetzt und vielen Verbesserungen unterzogen: Schreib einen Blog. Das machte ich und hatte auch einen relativ hohen Output, weil ich vieles aus meinem Job dort verarbeiten konnte. Zusätzlich faste ich auch einfach oft, dass zusammen was ich neben lernte. Anleitung zum Aufsetzen waren auch mehr Merkzettel für mich, weil man dann nicht jedes mal neu überlegen, ob ich alles gemacht und nichts vergessen habe. Aber wohl die größte Inspiration war das Gespräch mit Kollegen. Jeder hat seine Ansichten und Meinungen. Wirklich falsch ist etwas davon nie nur immer aus verschiedenen Sichtweisen. Selbst die Sichtweisen, die Neuerungen und so schwer gemacht haben, waren ja nicht an sich falsch.
Ich fing also auch vermehrt an an privaten Projekten zu arbeiten. Das hatte ich schon vorher getan und mein PHP-Framework hatte auch zu der Zeit schon ein paar Jahre produktiven Einsatz hinter mir. Aber ich lernte von John Sonmez eine ganz wichtige Lektion, die mich wirklich weiter gebracht hat. Wenn man etwas anfängt, muss man es auch zu Ende bringen. Angefangen hatte ich viel, aber an sich ist da alles irgendwann im Sande verlaufen und ich hatte Glück, wenn etwas Prototyp-Status erreichte. Meistens war es dass eine andere Technologie dann wieder spannender war und man die andere Technologie ja irgendwie gemeistert hatte.. das Programm lief ja.. dann wäre so was wie der Go-Live gekommen und man hätte es der Öffentlichkeit präsentieren müssen. Werbung, Support, Pflege.. Kunden.. also der ganze unspannende und nervige Kram. Aber es gehört nun mal dazu und ein Projekt technologisch umzusetzen ist, dass was an sich jeder Entwickler mehr oder weniger gut am Ende hinbekommt. Abhängig davon welche Umgebungsfaktoren und Anforderungen einen so Steine in den Weg legen. Dann genau dieser letzte Teil vom Projekt, ist der der einen weiter bringt und einem Sichtbarkeit verschafft. Projekt, das zwar läuft aber nicht veröffentlicht wurde, ist nicht mehr als Beispiel für Lernzwecke, aber nie am Ende etwas richtiges.
Zu der Zeit entstand neben ein paar kleinen Firefox-OS Apps und mp4togif.com. Genau diese Softskills waren es dann auch, die mich weiterbrachten. Denn ein Projekt selbst durch zuführen ist was ganz anderes als nur Entwickler in einem Projekt zu sein. Man lernt zu Kommunizieren und irgendwie auch etwas zu Manipulieren. Umschiffe Hindernisse mit der richtigen Sprache und in dem man die richtigen Leute anspricht. Dafür muss man proaktiv nach vorne gehen. Du musst die Probleme lösen, die anderen können besten Falls unterstützen oder Hilfen geben. Und wenn man die richtigen Leute um Hilfe fragt, werden sie sich auch an dich erinnern und das nicht negativ.
Also.. Softskills. Lerne Menschen kennen bzw lass anderen Menschen dich kennen lernen. Frage um Hilfe, wenn du sie brauchst und zeige Dankbarkeit für die Hilfe. Auch sollte man genauso seine Hilfe anbieten.
Denn dass ist etwas, was ich zwar wusste, aber erst eimal bewusst forcieren musste. Sei die Person die man um Hilfe fragt. Lerne zu helfen und dein Wissen verständlich und sicher mitzuteilen. Man muss nicht alles wissen, aber man sollte seine Bereiche haben, wo man sich sicher auskennt und dieses auch offensiv nutzen. Wenn jemand ein Problem hat, soll er zu dir kommen. An sich ist das nichts anderes als Kundengenerierung. Man muss sich in eine Position bringen, wo man anderen die Hilfe nicht mehr anbieten muss sondern wo man um Hilfe gefragt wird.
Wichtig hierbei zu beachten ist natürlich: Wer Programmieren liebt und nicht seine Zeit in Meetings verbringen möchte, wo man auch mal deine Meinung zu einen Thema gerne hören würde... dann sollte man es nicht machen. Ich helfe gerne, lerne gerne die Probleme und Lösungsansätze anderer kennen und entwickle gerne Lösungen. Programmieren ist dann nur noch ein letzter Schritt zur Realisierung.
Auch wenn es immer versucht wird zu verhindern, dass sich Wissen in einer Person konzentriert (die Person ohne die bei einem Programm nichts gefixt werden kann, wenn die Person nicht da ist..), sei diese Person, aber sei auch ein Multiplikator, auch erstmal aktiv. Sag in Meetings, dass du eine ähnliche Lösung schon mal gesehen hast und eine Email schreiben wirst oder gib Tipps wo schon mal so etwas gemacht wurde. Das man dann noch mal auf dich zukommt, wenn noch Fragen sind, ist gut, weil dann dein Tipp zumeist gut und hilfreich war.
Man muss dieses Networking und die "richtigen" Menschen kennen nicht so extrem sehen wie John Sonmez und Menschen nur nach Nutzen beurteilen. Aber einige Leute zu erinnern, dass man noch existiert, kann nie schaden. Falls doch mal Hilfe braucht oder sogar man mal auf der Suche nach einem neuen Job ist (Freelancing oder fest angestellt.. egal) kann es hilfreich sein. Würde ein ehemaliger Arbeitgeber merken, dass es doch jetzt Zeit für einen B2B-Webshop wäre und man eine Anbindung (automatisierter Artikel und Bestellungen Abgleich) an ein ERP braucht.. SAP oder.. an sich egal.. würde ich natürlich gerne unterstützen und helfen. Erstens würde es mich darin bestätigen, dass mein Konzentrieren auf diesen Bereich richtig war, dass das was in meine Blog steht mein Fachwissen und Kompetenz gut transportiert hat und ich als Mensch nicht so war, dass man mit mir nicht zusammen arbeiten wollen würde. Wobei ich dann doch so bin, dass mich der letzte Punkt am meistens treffen würde, denn es gibt nur einen mit dem ich nie wieder zusammen arbeiten würde, weil es leider zu unschön aus einander ging und es wohl nie harmonieren würde bei einem erneuten Versuch der Zusammenarbeit.
Denn das habe ich auch von Simple Programmer gelernt. Wenn es nicht geht geh... egal ob man dir bei neuen Bewerbungsgesprächen dumme Fragen stellen könnte. UND die Probezeit ist für beide Seiten da! Auch der Arbeitgeber darf gehen, wenn es nicht passt.
Es gab natürlich auch Tipps, die mir nichts gebracht haben. Z. B. die Promodoro-Technik. Ich kann es nicht. Meine Arbeitsweise passt nicht zu den Zyklen.
Klar mache ich auch kurze oder etwas längere Pausen, um zwischen Workloads den Kopf wieder frei zu bekommen. Aber wenn ich einen Lauf habe will ich nicht unterbrochen werden und ich kann meine Aufgaben immer in 15min Workloads aufteilen. Gerade beim Debuggen an einer Stelle, wo man sich erst einmal hinarbeiten muss, kostet eine Unterbrechung nur unnötig viel Zeit und nervt mehr als zu nutzen.
Treibe Sport! ... jaaaaa... wenn ich wieder Zeit dafür habe... also.. nächstes Jahr? Bzw eines der nächsten Jahre.... TBA.. ja.. TBA.
Aber Ernährung war dann doch wieder besser und kann ich unterstützen. Es bedarf Überzeugung und Motivation, sich Abends was vorzubereiten oder morgens doch noch mal Brote zu schmieren. Ich mag Pizza und Burger und man findet immer jemanden der in der Mittagspause mitbestellen würde. Und selbst den Gang zum Bäcker kann man sich gut reden. Aber am Ende fühlt man sich mit eigenen gesunden (oder nicht ganz ungesunden Essen) leistungsfähiger und fit. Ich trinke auch zu viel Mate und zu wenig Wasser bei der Arbeit. ABER jedes mal wen nicht ein paar Tage doch etwas besser mache, bin ich stolz auch mich und in den letzten Monaten klappt es auch immer ein Stückchen besser: Gesundes Essen am Abend, Smoothis, oder einfach mal ein selbst geschmiertes Brot. Man merkt den Unterschied zu einer fettigen Pizza.
Also.. ich habe von John Sonmez viel gelernt oder wenigsten Hilfe dabei gehabt Sachen deutlicher zu sehen. Die Beiträge von den anderen Autoren haben mich nie wirklich begeistern können. Deswegen ist sein Weggang für mich auch mit das Ende von Simple Programmer für mich. Wirklich Schade, aber was zu sagen war, hat er gesagt und geht nicht verloren.
Außerdem war er neben Kassenzone.de der einzige mir gekannte Blog, der Transkripte der Vlogs und Podcasts hatte. Ich überfliege lieber schnell die Texte zum Filtern nach interessanten Themen als durch ein Video oder Podcast zu spülen und mit etwas Glück die richtige Stelle zu erwischen.
Wenn man mit Events und Hooks für Controller arbeitet, wird man oft die Request-Parameter manipulieren wollen. Wenn man aber nun einen Parameter entfernen will, muss man die setParam()-Methode verstehen, weil man sonst leicht in ein kleines Problem läuft, dass mit der getParam()-Methode zusammen hängt.
$request->setParam('sPage', null);
wird nicht funktionieren und getParam() wird den ursprünglichen Wert zurückliefern. Aber warum? Weil das Request-Object ein internes Array mit den Params beinhaltet. setParam() setzt aber den Eintrag im Array aber nicht auf null, sondern entfernt diesen aus dem Array. Soweit ok. Aber nun kommt das Problem. Wenn getParam den Key im Array nicht findet, get es auch $_GET und $_POST zurück und findet dort natürlich noch den Original-Wert von sPage und liefert den zurück.
$_GET oder $_POST kann man natürlich auch ändern.. ABER das fällt bei der automatischen Prüfung im Shopware Store auf und das Plugin wird instant abgelehnt (auch wenn $_GET in einem Kommentar steht....).
$request->setParam('sPage', 0);
So funktioniert es und durch das seltsame Casting von PHP ist 'if($request->getParam('sPage'))' dann auch false.
Am 24.6. war es wieder so weit und das Bremer Oldtimer-Rennen stand wieder für mich vor der Tür. Wie im Jahr davor sollte meine Aufgabe sein, die Zeitmessungen (jeden Falls einen Teil davon) durch zu führen und am Ende die Gewinner benennen zu können. Klingt erst einmal ganz einfach aber für diese Sache, die an sich voll automatisch laufen sollte, ist immer viel mehr zu tun als man so denken würde.
Dafür muss man das Grund-Setup kennen und verstehen. Bei dem Rennen nehmen 170 Autos teil. Jedes dieser Autos wird mit einem aktiven RFID-Tag ausgestattet der den Tag über die Kennung des Autos aussendet. Die Veranstaltung besteht genau genommen aus 3 Rennen. Da es natürlich unfair wäre, bei Autos von 1920 bis 1970 auf Minimalzeit pro Strecke zu fahren, wird immer auf eine Richtzeit gefahren. Der Fahrer, der am dichtesten an der Zeit dran ist gewinnt. Also kann der zweit etwas langsamer als die Zeit sein und der 3. etwas schneller. Es nur um die absolute Differenz.
Am Anfang und am Ende jeder Strecke steht dabei ein RFID-Reader, der alle Autos erfasst, die vorbei fahren.
RFID sendet aber bei einem aktiven Tag mehr als die Sekunde sein Signal und die Reader decken mit ihren Antennen einen größeren Bereich ab. Es funktioniert also grundlegend anders z.B. eine Lichtschranke. Man bekommt also eine Menge an Messwerten, die vom Auto gesendet werden, während es vorbei fährt. Daraus wird nach dem relativ einfachen Prinzip von Zuerst-Gesehen und Zuletzt-Gesehen der Mittelwert berechnet.
Dabei kann an sich schon genug schief laufen. Gerade wenn man kleine und kurze Strecken hat. Wenn das Auto schon soweit beim Start an den Reader heran fährt und schon Messwerte erfasst werden, aber das Auto noch nicht losfährt. Dann wird die Zeit in der das Auto steht, mit Pech mit in die Zeitberechnung mit hinein gerechnet.
Aber auch die Chips und Sender der Tags sind nicht immer zuverlässig. Auch wenn sie 100 mal die Sekunde senden sollen, kann man nicht immer sicher sein, dass es keine Einbrüche in dieser Frequenz gibt. Autos aus Metall können außerdem sehr gut Abschirmen und so die Sendeleistung stark beeinflussen. Bautechnische Probleme wie schlechte oder defekte Schalter zum Ein- und Ausschalten kommen noch dazu.
Diesmal hatten wir im Vorwege das Problem, dass allein durch die Bewegungen der Tags in der Kiste sich einige einschalteten und anfingen zu senden und so Tags empfangen wurden, die gar nicht zum Rennen gehörten.
Durch einen guten Aufbau und ein wenig mehr Programm-Logik kann man fast alle Probleme unter Kontrolle bringen. Aus der Menge der Messpunkte werden konkrete Werte errechnet. Mehrfachmessungen eines Autos werden entfernt und fehlende Messungen werden herausgesucht. Das benötigt etwas mehr Rechenleistung, weswegen die Messstationen mit etwas Leistungsfähigeren Notebooks ausgestatteten sein müssen.
Damit kommen wir erst einmal wieder zurück an den Anfang. Die Vorbereitung und was diesmal alles zu tun war.
Vorbereitung:
Nachdem im letzten Jahr mehr oder weniger spontan Notebooks mit dem Mess-Client ausgestattet wurden und es zu vielen Problemen kam:
- Fehlende Runtime-Umgebungen
- andere Server-Anwendungen die Ports blockierten
- Notebooks auf denen schon so viel installiert war, dass sie langsam waren
- Akkus die nicht mehr lange durch hielten und deswegen immer Strom nötig war (den es nicht immer gibt)
Ich fing also schon 2 Monate vorher an, das Problem in Angriff zu nehmen. Ich entschied mich die Hardware diesmal komplett selbst zu stellen und somit etwas mehr Sicherheit zu haben. Das Alienware sollte diesmal nicht benutzt werden, da es schwer ist und man es nicht mal schnell zur Seite nehmen kann, wenn es regnet. Außerdem ist es einfach nicht dafür gedacht, über den Akku zu laufen.. jedenfalls nicht langer als 15min.
Da ich für Notfälle aber eine Entwicklungsumgebung haben wollte, damit ein Fehler nicht ein Rennen versauen kann oder die Auswertung unmöglich macht, entschied ich mich mein Surface mit zunehmen. Es ist relativ Wetter-beständig und der Akku hält sehr lange. Die Rechenleistung ist nicht wirklich groß, aber ausreichend.
Damit waren meine eigenen Notebook Vorräte aber erschöpft und extra welche Kaufen würde sich nicht lohnen. Also kam ich auf die Idee meine Kontakte als Mitarbeiter bei Notebooks Wie Neu zu nutzen. Ich konnte mir 2 Lenovo Thinkpad T410 leihen. Mit i5, 4GB RAM waren die mehr als schnell genug und Thinkpads sind auch stabil genug, so das ich mir wegen Regen nicht zu viel Sorgen machen musste. LAN und USB Anschlüsse waren auch vorhanden. Der Akku hielt mehr als genug und am Ende waren die Akkus nicht mal halbleer, obwohl die Thinkpads ca. 2h damit beschäftigt werden durchgehend Daten abzurufen und in eine MySQL-Datebank zu schreiben.
Nur eine Sache störte mich etwas.. das war Windows 7. Egal was viele im Internet so schreiben.. bei der Bedienung ist Windows 10 sehr viel schneller und intuitiver als Windows 7. Aber da alles wie Java 1.8 und MySQL laufen, ist es nicht so schlimm, weil die Client-Software sowie so rein über die CLI bedient wird. Eine GUI Version existiert, ist aber noch auf eine Verbindung zum Server angewiesen, was da nicht gegeben war. Ein portabler UMTS-WLN-Router wäre eine gute Lösung gewesen, aber die Idee kam mir zu spät und ich wollte ja gerne den Server bei Problemen schnell ändern und fixen können. Was mit einer lokalen Instanz, die man direkt in der IDE hat, natürlich sehr viel schneller und einfacher geht als mit einem System das auf einem Server im Internet läuft.
Vielleicht bin ich nächstes Jahr mal mutiger. Es hätte auch noch andere Vorteile für die Veranstalter.. aber dazu später mehr.
Die Liste der Teilnehmer konnte ich am Abend vorher importieren und dabei noch 2 kleine Fixes einbauen. Deswegen wollte ich die Liste gerne schon vorher haben.
170 Autos. 170 importierte Rennteilnehmer am Ende. Alles perfekt.
Ich hatte also 4 Notebooks (das Alienware war als Fallback dann doch dabei), Reader, Netzwerk-Kabel und einen Switch. Was man aber immer dabei haben sollte, ist auch Essen und Trinken. Wasser und Energiedrink. Eines für den Durst und das andere für Energie. IBUs für Notfälle und natürlich das Smartphone für Navigation und Informationsbeschaffung. Beim Essen kann man sich ruhig abends vorher was kochen, denn gutes Essen macht es einen sehr viel einfacher, wenn man morgen um 4:15 aufstehen muss und dann noch kein Frühstück hatte.
Immerhin war das Wetter gut und nicht so verregnet wie im letzten Jahr... jeden Falls am Anfang
Der Tag:
Um 4:45 war ich in Stockeldorf bei "die Halle" wo die Switch GmbH ihren Sitz hat. Die Mitarbeiter wuselten durch die Gegend und packen alles in den VW Bus was man so brauchte. Dann wurde ein Karton mit Tags hochgehalten und gefragt, ob die auch mit sollen. "Nein, das sind die, die nicht funktionierten und ausgewechselt wurden".
Klingt erst einmal nicht so schlimm, aber wenn man bei 170 Teilnehmern 30 Tags für jeweils drei Rennen austauschen muss.. also 90 Einträge per Hand bearbeiten, dann klingt es nicht mehr gut. Am Ende wurden also diese Ausgetauschten alle geöffnet und Batterien getauscht. Am Ende waren es pro Rennen nur jeweils ca. 6 Tags, die per Hand übergetragen werden mussten.
Hier fiel mir auch auf, dass die Tags dieses Jahr gefühlt sehr viel Fehleranfälliger waren. Beim Testen wurden noch 4 ausgetauscht, weil sie nicht vom Reader erkannt wurden. Die Schalter schalteten in den Karton bei jeder kleinen Bewegung wie sie wollten.
Und dann kam der Regen. Viel Regen. Alles wurde unter die offene Heckklappe des VW-Bus gestellt und das Surface wechselte erst einmal in eine Plastiktüte.
Es war zum Glück nicht wirklich kalt. Nur sehr sehr nass. Wer glaubt das Regen und die Nässe nur immer von oben kommt, irrt sich. Tropfen fallen auf Tische und spritzen dann in alle Richtungen. Am Ende ist doch alles nass.
Aber es gab auch positives zu berichten. Weniger Tags streuten in den Messbereich und die Erkennung war dieses mal sehr viel besser. Das andere Team meldete sich schon kurze Zeit später und meldete, dass alles laufen würde. Ich bin immer sehr unruhig wenn ich bei so etwas nicht in der Nähe sein kann, um möglicherweise auftretende Fehler zu beheben. Ich kenne das System zu 100% und einfach unerfahrene Benutzer damit los zu schicken.. dazu gehört sehr viel Vertrauen in die eigene Software dazu.
Am Ende war alles super. Alles hatte beim ersten Rennen funktioniert und das Thinkpad konnte zeigen was es konnte. Beim Surface braucht ich so 15min mit Client in der IDE um die Daten zu übertragen. Dabei liest der Client und schreibt der Server auch in die selbe Datenbank, was auch nochmal bremst. Das Thinkpad brauchte gerade mal 4-5 Minuten. Schnelle CPU, schnelles Lesen von der Festlatte. Das Schreiben in die DB auf dem Surface war dann auch sehr entspannt, weil nebenbei nicht so viel gelesen oder gerechnet werden musste. Also Server und Entwickler-Rechner hat sich das Surface mehr als bewährt. Das selbe gilt auch für die Thinkpads als Messstationen-Clients.
Das 2. Rennen war dann die kritische Phase, die dann aber auf Grund der stabilen Bauweise der Reader und viel Nachrechnen und eliminieren von Fehlmessungen, am Ende doch gut ging. Wir hatten kaum Zeit zum Aufbauen, ein Reader lief an einem Diesel-Generator und 50m Lan-Kabel. Die ersten Autos wurden manuell gemessen mit der eingebauten App vom Time-System, während wir nebenbei den zweiten Reader aufbauten, der dann am Alienware lief. Sturm, Regen und noch mehr Regen. Wir saßen im Bus und nur die Kabel zu den Readern im Regen gingen nach draußen. Ich wüsste zwischendurch nicht ob der Reader am Start noch lebte und Daten sendete. 1,5h später war der Regen vorbei und man ordnete sich und guckte mal wieder auf die Terminal-Ausgaben auf dem Surface. Alles lief super. Es fuhr gerade das letzte Auto vor und der Reader meldete den Tag also ob vorher nicht gewesen wäre. Sein Netzteil hing so im Regen und ein Teil des Kabel lag vorher schon blank. Aber kein Aussetzer bei der Datenerfassung. Ich war wirklich stolz auf den kleinen tapferen Reader.
Das Netzwerk-Kabel wurde auch nebenbei als Streckenbegrenzung verwendet. Von der Planung her eine Katastrophe, aber mit den Fallback-Lösungen konnte man alles retten.
Danach ging es zur Test-Strecke von Mercedes und das 2. Thinkpad übernahm das Rennen dort. 1. Rennen war in 20min fertig. Ich hab bevor Korrektur-Funktionen über die Daten liefen immer lieber noch einmal die Daten gesichert. Berechnen lief schnell.
Das 2. Rennen brauchte mehr Zeit. über eine Stunde, da ich viel bei den Korrektur-Funktionen nacharbeiten musste, die Fehlmessungen eliminierten und ich lieber 3 mal die Liste der gefahrenen Autos durch ging, um sicher zu sein, dass wirklich kein Auto übersehen oder nicht gemessen wurde.
Das 3. Rennen ging dann wieder sehr schnell und es gab keine Überraschungen.
Bestes Frauen-Team musste dann per Hand berechnet werden. Waren aber nur sehr wenige Teams, deswegen ging es. Der Gesamtsieger war aufwendiger, weil man über die gesamten drei rennen Rechnen musste, zum Glück sind es doch immer die selben Fehler die vorne liegen. Damit war es ausreichend die 9 Sieger der 3 Rennen zu nehmen und für diese die Werte der 3 Rennen auszuwerten. Kontrolle bei den 4. und 5. Plätzen zeigten gleich, dass von dort keine Konkurrenz mehr kam.
Auch fiel dabei auf, dass man kein großes Kopf-an-Kopf-Rennen hier hatte. Die ersten Plätze waren immer sehr eindeutig, eher am Ende des ersten Drittels konzentrierten sich die Zeiten auf eine geringe Zeitspanne.
Das Fazit:
Das Event lief sehr viel besser als das letzte Jahr und die Zeiten für die Auswertungen war sehr viel geringer. Die automatischen Analysen und Korrekturen von Fehlmessungen hat viel gebraucht und sehr viel besser und zuverlässiger funktioniert, als es per Hand war.
Trotzdem hätte ich gerne eine andere Lösung für das nächste mal. Die Tag an sich sind eine Fehlerquelle für sich und diese würde ich gerne eliminieren. Eine Lösung wäre eine Kamera gestützte Erfassungsmethode mit QR-Codes. Wie Lichtschranken, gibt es da aber Probleme bei parallel fahrenden Autos. Deswegen müsste man ein Gestell haben, um die Kameras von oben auf die Start- und Ziellinie gucken zu lassen. Dann muss man die Autos erkennen, da man so wirklich von vorderen Punkt des Autos messen kann und nicht nur die Position des RFID-Tags (was viele Teilnehmern nicht klar war, sich aber natürlich auf die Messungen auswirkt).
So ein System ist sicher zu bauen, aber braucht seine Zeit. Am Ende hätte man aber sicher gute Ergebnisse mit Beweisfoto.
Auch sollte alles so aufbaubar sein, dass die Technik die Autos nie verlassen muss. Mehr Schutz vor Regen und man kann schneller aufbauen, wenn nur noch Kabel verlegt werden müssen.
Ein großer Traum wäre es, es wirklich als Cloud-Anwendung laufen zu lassen, so dass die Clients direkt vor Ort über einen WLAN-UMTS-Router ihre Daten direkt an den Server schicken können. Vielleicht sogar kurz nach dem sie gemessen wurden. Damit hätte man auch die Möglichkeit eine Echtzeit Anzeige zu realisieren.
Wie man überall lesen kann will Oracle nun auch JEE gerne abgeben. Aber sie sichern zu weiterhin an Java festzuhalten.
In den meistens News klingt es so als wäre das ein Widerspruch in sich. Ich kann Oracle aber vollkommen verstehen. Der Java-Core ist so oder so OpenSource und JEE ist optional und kann durch andere Lösungen wie Spring ersetzt werden. Wie Standards wie JMS, EJB3 und so sind wirklich toll und funktionieren super. Sie werden auch viel genutzt, also kann man die auch nicht wirklich sterben lassen, gerade wenn man selbst damit viele Anwendungen gebaut hat.
Oracle auch wirklich viel mit Java gemacht und auch sehr gute Anwendungen damit entwickelt. Nur warum sollte man dafür im Besitz eine Standards sein? Als das alles noch bei Sun lag lief auch alles super und (jetzt folgt der wichtige Punkt) man musste sich nicht mit dem ganzen Drumherum rumärgern.
Als PHP Entwickler hat man ja auch nicht gleich Lust sich den PHP-Standard noch mit auf zu halsen.
Bei der Eclipse Foundation wäre JEE gut aufgehoben und Oracle kann weiterhin mit Java entwickeln und sich sogar einbringen ohne gleich für alles verantwortlich gemacht zu werden.
Ich bin jeden Fall gespannt wie es weiter geht und sehe da mehr Zuspruch in die Zukunft Javas von Oracles Seite als mögliches Abwenden von JEE oder gar Java an sich.
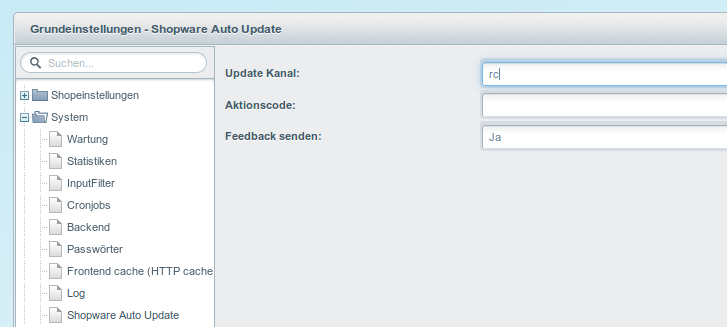
Momentan steht bei mir an ein Plugin für Shopware zu entwickeln.
Das erste Problem dabei ist nicht mal, wie das funktioniert, weil das ist im Internet mehrfach gut erklärt, sondern wie man seine Entwicklungsumgebung aufsetzt.
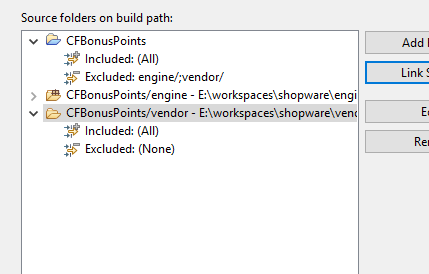
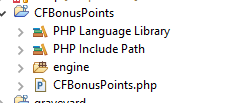
Shopware ist schnell installiert. Aber man will für ein Plugin ja nicht immer das gesamte Shopware mit im Projekt haben. Also wird nur das Verzeichnis aus custom/plugins/ als Projekt-Verzeichnis gewählt.
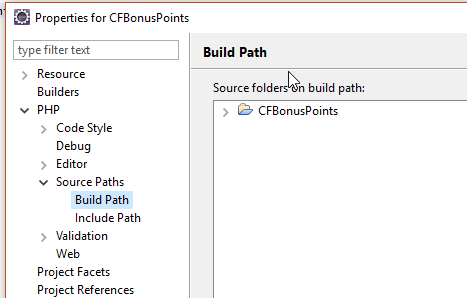
Bei Eclipse kann man Projektverzeichnisse außerhalb des Workspaces anlegen.
Nun hat man das Problem, dass einem die ganzen Klassen von Shopware fehlen und man so viele Warnings und keine Autovervollständigung hätte.
Über Properties > PHP > Source Paths > Build Path kann man externe Source-Verzeichnisse verlinken.
ich habe das engine-Verzeichnis von Shopware gewählt und noch zusätzlich dessen vendor-Verzeichnis.
Die PHPUnit Tests werfen dann zwar noch Fehler. Aber die Plugin-Klasse von Shopware wird schon einmal gefunden und damit ist der erste Schritt schon getan.
Damit kann meine Arbeit an meinem ersten Shopware-Plugin jetzt anfangen.
Wenn man mit dem sBasket von Shopware zutun hat und auch mal selbst was in den Basket legen möchte und dann vielleicht ist das was man rein tun möchte kein standard Artikel sondern ein Rabat oder ähnliches, kommt man schnell zu dem Feld Modus/Mode.
Um die Magicnumbers zu decodieren muss man etwas tiefer suchen.. in der cart_item.tpl.. wäre jeder sofort drauf gekommen.. oder?
{* Constants for the different basket item types *}
{$IS_PRODUCT = 0}
{$IS_PREMIUM_PRODUCT = 1}
{$IS_VOUCHER = 2}
{$IS_REBATE = 3}
{$IS_SURCHARGE_DISCOUNT = 4}
Gutscheine findet man also dann bei Einträgen mit dem Mode 2. Gerade bei Exports von Bestellungen für externe Systeme kann dieser Mode sehr praktisch sein.
Die Einträge mit der 3 werden bei jedem Anzeigen neu aufgebaut und somit werden Positionen, die man einfach in die DB schreibt auch sofort wieder gelöscht. Für den Zweck scheint Mode 4 der richtige zu sein. Wobei ich dort noch Probleme mit dem Löschen habe, aber das kann ich sicher noch über ein Event oder Hook lösen.
foreach ($this->getListeners($event) as $listener) {
if (null !== ($return = $listener->execute($eventArgs))) {
$eventArgs->setReturn($return);
}
}
$eventArgs->setProcessed(true);
return $eventArgs->getReturn();
}
und da sehen wir
$eventArgs->setReturn($value);
Also ist die Lösung
public function eventMailListener(\Enlight_Event_EventArgs $args){
/** @var \Enlight_Components_Mail $mail */
$mail = $args->getReturn();
echo $mail->getPlainBodyText();
die();
}
Wenn man das erst einmal verstanden hat, ist alles plötzlich ganz einfach. Ach ja, wenn man das Subject überschreiben möchte erst einmal $mail->clearSubject(); ausführen.
Elastica ist sehr radikal was deprecated Methoden angeht. Es werden nicht einfach nur Warnings angezeigt sondern gleich Exceptions geworfen. Deprecated Warning ignoriert man gerne. Besonders wenn man aus dem Java-Bereich kommt, weil dort ist man gewohnt (Beispiel die Date-Klasse), dass Methoden zwar deprecated sind, aber ewig weiter existieren und dass meistens auch weiterhin fehlerfrei- Die wurden meistens nur deprecated, weil die Funktionalität in eine andere Klasse verschoben wurde oder es eine neue Funktionalität gibt, die mehr kann und die alte voll umfassend ersetzen kann.
Das werfen von Exceptions, die man mit Try-Catch auffangen könnte motiviert aber ungemein, gleich alles auf das neue Vorgehen umzubauen. Warnings sind ok.. Exception dürfen aber nicht sein. Das Warning ignoriert oder gleich ganz abgeschaltet werden führt auch immer wieder zu "lustigen" Vorkommnissen. "Wieso hast du einfach die Methode gelöscht.. die hab ich an mehreren Stellen verwendet!" - "1. war sie fast 10 Monate als Deprecated markiert.." - "... Warning hab ich abgeschaltet.. waren zu viele.." - ".. und 2. soll bitte die Service-Schnittstelle des Modules genutzt werden,weil dort wurde schon vor 11 Monaten auf die neue und schnellere Methode umgestellt"
Man sollte seinen Code immer Warning-frei halten und nicht einfach Warning ignorieren, weil man ein paar einfach nicht entfernen kann, weil z.B. der Code-Parser der IDE glaubt er könnte das SQL-Statement, dass aus mehreren Strings zusammen gebaut wird brauchbar auf Fehler untersuchen.
Oft hat man das Problem, dass man verschiedene Einheiten verarbeiten muss und nicht alle sich an Standardeinheiten (SI) halten. Mag es daran liegen, dass die Person historisch gewachsene Einheiten wie Liter oder Pfund verwendet oder auch einfach daran, dass diese Person Amerikaner ist. Natürlich gibt es genug Frameworks, die einen helfen mit allen möglichen Einheiten klar zu kommen, aber es ist an sich gar nicht schwer sich so etwas selber zu schreiben.
Man muss nur die Basis-Einheit (SI) bestimmen und alle anderen Einheiten sich darauf beziehen lassen. Ein gutes Beispiel ist hier Inch/Zoll um das ganze zu demonstrieren.
Wir befinden uns in der Gruppe der Einheiten zur Bestimmung von Längen. Die Basiseinheit ist laut SI der Meter. Wir bauen uns jetzt 3 Einheiten Entitäten (die man am Besten in einer Datenbank anlegen sollte).
Wie kommen wir jetzt ganz einfach von Inch auf Zentimeter? Wir nehmen den Inch-Wert und multiplizieren ihn mit dem Conversionfactor. Dann haben wir bei 1 Inch einen Wert von 0,0254 Meter. Nun nehmen wir uns unseren Zentimeter und teilen den Meter-Wert durch den Conversionfactor des Zentimeter. 0,0254 / 0.01 = 2.54 damit haben wir Inch in Centimeter umgerechnet. Einfacher Dreisatz. Wenn wir nun Einheitenwerte zu irgendwas speichern wollen, ist es eine gute Idee, diese vor dem Speichern immer auf die Basis-Einheit umzurechnen.
Das vereinfacht die Ausgabe, weil eine Methode sich so direkt die Einheit bilden kann, die sie gerne hätte.
In dem Zusammenhang ist auch eine Methode gut, die eine ideale Maßeinheit für einen Wert bestimmt. Wenn wir nun 0,001cm haben sollte diese Methode uns sagen können, dass die Repräsentation 1m für den Benutzer sehr viel einfacher zu lesen ist und uns den Wert und die Einheit liefern können.
Auch praktisch ist, dass man so dem Benutzer es überlassen kann in welcher Einheit er Ausgaben gerne sehen würde. Würden wir uns im Bereich der Flächeneinheiten befinden und die Fernsehsendung Galileo über die Größe der Flächen von bestimmten Dingen berichten wollen, können wir für sie direkt die Einheit "Fußballfeld" definieren und sie ihnen als Ausgabemöglichkeit anbieten.
Weitere Gedanken zu Einheiten/Units
Bei Bestellsystemen bereitet oft die Pseudo-Einheit "Stück" Probleme. Aber hier muss man sich einfach von der Vorstellung von Stück als eigene Einheit trennen. Maßeinheiten werden gemessen.. Stück werden einfach gezählt. Am Ende wird alles auf eine Verpackungseinheit herunter gebrochen und diese ist alleinstehend "1 Stück". Wenn ich 5L Wasser bestellen möchte ist es weiterhin sehr wichtig wie dieses Verpackt ist. 5x 1L oder 10x 0,5L. Verpackungseinheiten können auch rein virtuell sein. 100L = 100x 1L wobei nicht gesagt ist, dass dieses "verpackt" sein muss und nicht einfach direkt von einem Tank in einen anderen umgefüllt werden kann. Also.. Stück ist keine Maßeinheit sondern existiert parallel dazu um beschreibt nur eine Portionierung der in der Maßeinheit gemessenen Sache, die so geliefert werden kann.
Wo ist der Unterschied zwischen einer 1L Flasche Wasser und einem Stuhl? Beides ist "1 Stück" wobei man bei der Flasche den Inhalt in eine Maßeinheit fassen kann und bei einem Stuhl nicht. Ok.. man könnte.. es ergibt aber einfach keinen Sinn sich 25kg Stuhl zu bestellen.
Für Produktionssysteme ist der obige Ansatz sogar ohne solche Überlegungen einfach direkt umsetzbar und funktioniert sehr gut.
In den letzten Tagen liest man immer mehr, dass sich viele Sorgen um die Zukunft von Java und gerade um Java EE machen. Wie schon vorher bei JavaFX gilt auch hier immer der Vorwurf Oracle würde sich nicht genug einbringen und auf Fragen um die Zukunft nicht weiter äußern. Oracle ist leider nicht Sun und da sie keine Rechte an der API gegenüber Google mit Android geltend machen konnten, scheint wohl das Interesse noch Mals wieder gefallen zu sein.
Die nächsten Jahre wird man sich um Java sicher keine sorgen machen müssen. Java ist immer noch mit die wichtigste Plattform für Enterprise Entwicklungen und die angebotenen Lösungen sind sehr mächtig und nehmen einen vielen wichtigen Bereichen eine Position ein, bei denen man nicht einfach mal schnell eine andere Lösung einführen kann.
Auch wenn Oracle selbst das Interesse verlieren sollte, gibt es immer noch genug eine große Mitspieler, die Java nicht so einfach sterben lassen würden. IBM, Apache und Red Hat sind die wichtigsten hierbei. So lange diese hinter Java stehen und Eclipse und Jetbrains entsprechende Entwicklungsumgebungen anbieten, werden sich viele sehr zurück halten auf etwas anderes umzusteigen und wo ein Markt ist werden auch Firmen sein, die diesen Markt bedienen. Wenn Oracle nicht mehr Teil dieses Marktes sein will, dann soll es eben so sein. Wichtige Entwicklungen wie Microservices und alternativen zu Node.js kamen am Ende ja auch nicht von Oracle sondern von anderen Anbietern. Oracle ist Besitzer von Java aber die Java-Welt wird meistens von anderen Bestimmt.
Aber ähnliches hat man auch lange über Zend gehört.. aber jetzt ist man bei PHP 7.0 und auch wenn es lange dauerte, zweifelt wohl niemand mehr an der Zukunft von PHP. Genau so wird es bei Java sein, es mag mal Zeiten geben wo es langsam voran geht, aber solange von Außen der Input bleibt wird es weiter gehen und am Ende ging es mit Java immer voran.. wenn auch zu vor schon oft eher langsam.
Im Serverbereich ist Java sehr stark und wird es sicher auch noch viele Jahre bleiben.
Komplexe Probleme führen zu komplexen Code. Einfache Probleme führen zu einfachen Code. Das sind die Gesetzmässigkeiten, die immer gelten. Sollte mal ein einfaches Problem zu komplexen Code führen, muss man den einfach wegwerfen und noch mal von Vorne anfangen, weil man irgendwas falsch gemacht hat. Das passiert, aber man erkennt den Fehler schnell und kann ihn korrigieren.
Schwierig wird es wenn ein Problem ein komplex ist. Komplexität ist sowie so ein Problem für sich. Jeder der schon mal Planning Pokergespielt hat, weiß wie schlecht sich Komplexität erkennen und bewerten läßt. Ich habe für mich eine kleine Staffelung erstellt, nach der ich mich richte. Der Knackpunkt bei der Bewertung sind Schnittstellen. Egal ob es andere Systeme sind oder andere Menschen.. sobald Schnittstellen da sind hat man mehr Komplexität und Overhead. Jeder muss das Problem verstehen, seine Aufgaben ausführen und Zeiten einhalten. Wenn das nicht klappt ist es oft auch nicht mal das Problem der anderen Menschen oder Systeme. Fehlerhafte Dokumentation und unklare oder unteschiedlich verwende Begriffe sind fast immer am Anfang dabei und müssen ereinmal geklärt werden.
Deswegen ist zum Beispiel Dokumentation für mich eine hoch komplexe Sache, weil dort immer gleich 2 Schnittstellen existieren. Einmal müssen die Infos rein und dann wieder verständlich für andere raus. Jeder der mal eine 70 Seiten Dokumentation über eine System für andere Entwickler geschrieben hat, wird mir hoffetnlich beipflichten können.
Aber nun zur Tabelle:
* 0: nichts zu tun, da schon erledigt oder obsolete
* 1/2: es müssen Texte oder andere statische Werte geändert werden
* 1: es muss vorhandere Code in der Logik minimal angepasst werden (if-Bedinungen anpassen oder Try-Catch Blöcke setzen)
* 2: Es muss in einer vorhanden Struktur Code erzeugt werden (eine Methode hinzufügen oder Hilfs-Klasse erstellen)
* 3: Es werden Daten verarbeitet (Einfacher Importer oder Ein- und Ausgaben)
* 5: Daten werden um gewandelt oder einfache einfache Schnittstellen entgegen genommen oder ausgegeben (Importer wo die Daten aufbereitet werden müssen)
* 8: Es wird Logik erstelle (Berechnungen und Daten operationen, einfache Planung ohne große Konzeption)
* 13: Logik mit Schnittstellen, wo die andere Seite beeinflusst werden kann, z.B. Fehler wirft, wenn fehlerhafte Daten geliefert werden (Man muss Planen und die Konzeption muss besprochen werden)
* 20: Die Schnittstellen oder Funktionsweisen sind noch zu erarbeiten (Die Realisierung ist machbar, aber es ist noch nicht klar, wie man zum Ziel kommt)
* 40: Man weiß, was man will, aber die Realiserung benötigt Forschung (Viele Meetings und es gibt Ansätze wobei diese auch sich noch als nciht zielführend erweisen können)
* 100: Die Realiserbarkeit kann angenommen werden, aber nicht mit bekannten Mitteln (man muss also richtige Grundlagenforschung betreiben und sich viel Rat einholen)
* unendlich: Man geht von einer Realiserbarkeit aus, aber weiß, dass bis jetzt niemanden gelungen ist so etwas umzusetzen.... z.B. wenn man vorhat einen Fusionsreaktor zu bauen
Da komplexe Probleme zu komplexen Code führen und für diesen gilt, dass er schwer zu warten, lesen und zu erweitern oder ändern ist, muss man den Code vereinfachen. Wer mal versucht hat ohne Neibewertung des Problems von gleichen Ausgangslagen den Code zu verbessern wird gelernt haben, dass man nur wieder anderen komplexen Code geschrieben hat. Man kann Codenicht vereinfachen ohne die Komplexität des Problems runter zu brechen. Das sollte man tun. Probleme in kleinere und einfachere Probleme aufbrechen. Lieber eine Woche länger das Problem analysieren, als Code schreiben der andere und einen selber später noch viel mehr Zeit kosten wird.
Deswegen.. nie versuchen den Code zu vereinfachen sondern immer das Problem vereinfachen und dann den Code anpassen oder besser noch einfach auch neuschreiben.
Ging dann ja doch schneller als erwartet. Der Marketplace wird wohl 2017 geschlossen.
Alle nicht Firefox OS Apps haben sich wohl schon 29. März erledigt. Ich werde dann also meine Einreichungen, die abgelehnt wurden, auch auf dem Stand belassen und keine weitere Arbeit mehr in die Richtung investieren.
Mich würde aber wirklich mal interessieren wie viele Firefox OS Smartphones es auf der Welt wirklich gibt und wie viele diese noch weiter verwenden würden. Einen eigenes Repository zu schreiben, wo Entwickler ihre Anwendungen hochladen oder verlinken könnten. So etwas ist bestimmt in 2-3 Tagen zu machen. Bei nicht gepackten Anwendungen ist es sehr einfach, weil man nur die URL zur Manifest-Datei an eine JavaScript-Funktion übergeben muss. Bezahl-Apps oder Support für In-App Käufe wäre da natürlich nicht drin. Keine großen Freigaben oder so.. jeder lädt einfach den Link oder die Zip-Datei hoch... und andere können sich die App über einen Klick auf einen Button installieren.
So etwas wäre ein lustiges kleines Projekt und Firefox OS ist eigentlich eine tolle Umgebung für Entwickler, weil man keine großen Entwicklungsumgebungen oder ähnliches braucht und ein Firefox-Browser zum Testen vollkommen reicht.
Dafür Apps zu entwickeln hat immer viel Spaß gemacht und ging immer sehr schnell.
Am Ende glaube ich nicht, dass es sich lohnen würde, in das gesamte Firefox OS Ökosystem noch mal Zeit zu investieren. Es ist wirklich schade um das System.
Heute zum Geburtstag habe ich von meiner Frau Soft Skills geschenkt bekommen. Es ist von John Z. Sonmez, dem Besitzer von http://simpleprogrammer.com und ich habe schon sehr viel Gutes darüber gehört und gelesen. Ein Buch für Programmierer bei dem das Programmieren und die Technik nicht im Mittelpunkt stehen, sondern das ganze Drumherum. Wie auch auf dem Buchcover steht: "coding is the fun part". Kommunikation, Produktivität und Stress sind der nicht so spannende Teil, aber man muss da immer durch.
Wenn ich es lese werde ich sicher noch ein oder zwei mal meine Gedanken dazu hier veröffentlichen.
Gehen wir mal davon aus, ich hätte doch mal das Geld für einen neuen PC und würde alles neu installieren müssen.
Was wäre das alles? Bei vielen Programmen nehme ich die portable-Version wenn vorhanden, weil man dann einfach das
Programm inkl. alle Einstellungen und Daten kopieren kann und sich nicht über die Migration der Daten Gedanken machen braucht.
* Notepad++ (Portable): Seit man einfach den Editor schließen kann und er speichert auch nicht gespeicherte Texte automatisch mit, ist er ideal für Notizen, kleine Text und schnelle Bearbeitungen einzelner Dateien. EmEditor kann es nicht, dafür paar andere tolle Dinge, wie Zeilen mit Such-Treffen in ein neues Dokument extrahieren, aber gerade dass ich EmEditor nicht einfach schließen kann ohne zu speichern, empfinde ich als großen Nachteil.
* WinSCP (Portable): Der eingebaute Editor ist kein Highlight, aber besser als wenn per Default immer der von Windows verwendet werden würde. Das Programm läuft auch stabil und hat mich bis jetzt nie im Stich gelassen. Bitvise finde ist als SFTP oder SSH Client irgendwie schlechter zu bedienen und es ist eben nicht Opensource.
* Eclipse + PDT: Bei Eclipse reicht es auch die ZIP-Datei zu entpacken. Über das Software-Menü dann einfach PDT nach installieren und vielleicht nochmal die Zuordnung der *.php-Dateien zum entsprechenden Editor bearbeiten.Wie man Unterstützung für Getter und
Setter installiert findet man hier: PDT-Extensions. PHPStorm kann auch einiges. Ich finde es aber auch unübersichtlich. RemoteHost-View.. ist unter Deployment zu finden. An sich ja nicht verkehrt, wenn man das weiß. Bei Eclipse einfach bei den Views gucken. Da kann man auch suchen und findet alles innerhalb von Sekunden. Vielleicht liegt es auch daran dass ich Jahre mit Eclipse verbracht habe und es lieben und auch oft
genug hassen gelernt habe, aber bei PHP ist es mein Favorit und es ist eben Opensource.
* Oracle SQLDeveloper: Wenn man mal mit Oracle zu tun hat oder keine Lust auf phpMyAdmin hat, ist es immer noch meine Lieblingssoftware für Datenbank-Entwicklung. phpMyAdmin ist eben sehr träge (für eine Webanwendung aber noch wirklich schnell.. nur im Vergleich). HeidiSQL ist einfach nicht so professionell. Man merkt dass Oracle sich mit Datenbanken auskennt.
* Source Tree für GIT-Repositories. Die GIT-Integration in Eclipse war jedenfalls nie wirklich toll, wie ich fand. Der Konsolen-Client funktionierte,war aber für Nicht-Programmierer wirklich zu umständlich. Tortoise.. ja.. hat bei mir noch aus Delphi+SVN Zeiten einen schlechten Nachgeschmack hinterlassen. Auch wenn deren SVN Client manchmal durch mergen zerstörte Projekte wieder retten musste zusammen mit Notepad++.
* XAMPP oder Bitnami... Benutze ich beides und am Ende mag ich XAMPP minimal lieber. Deren Kontroll-GUI ist etwas aufgeräumter und ich kann auch hier einfaches von einem PC auf den anderen kopieren. Aber funktionieren tun beide gut.
* ein aktuelles JDK: Weil viele der oben genannten Programme Java-Programme sind und ich unter Umständen auch mal ein kleines Java-Programm schreiben oder pflegen muss. Eine aktuelle JDK8-Version installieren und die reicht erst einmal lange ohne Updates. Sollte ich nicht doch plötzlich wieder voll auf Java setzen. Dann aber nur mit Tomcat und vielleicht der aktuellsten JSF-Version oder meinen REST-Framework und das Frontend entsteht komplett in AngularJS (habe ich so schon benutzt und funktioniert extrem gut und ist PHP mit dem Application-Scope und echten Singletons teilweise
weit voraus bei der Performance.. mal PHP7 abwarten).
Und dann eben noch der ganze Rest wie Firefox Developer Edition (64-Bit), Thunderbird, Chrome, etc. Was man auch zum Testen und dem Alltag so
braucht.
Irgendwann kommt der Zeitpunkt, da ist eine Anwendung langsam. Es liegt nicht am Datenbankserver oder der Netzwerkanbindung oder der Auslastung des Servers. Es liegt einfach ganz allein daran, dass die Anwendung langsam ist.
Oft findet man einige Dinge von selbst heraus. Aber oft ist man einfach überfragt in welchen Teilen der Anwendung die Zeit verloren geht. Was braucht lange? Werden einige Dinge unnötig oft aufgerufen? Zu viele Dateisystem-Zugriffe?
Hier hilft dann nur noch ein Profiling der Anwendung. Profiling ist einfach die Anwendung eine Zeit lang zu überwachen und zu protokollieren, wie viel Zeit in der Zeit auf welche Methoden oder Funktionen verwendet wird.
Das alleine sagt natürlich erstmal nicht wo Probleme vorhanden sind. Deswegen halte ich die Idee ein separate Team solche Performance-TEst durch zu führen und zu analysieren für nicht ganz so zielführend. Denn manchmal brauchen einige Methoden viel Zeit. Da man Zeit sowie so meistens nur in Verhältnis der Methoden zu einander betrachtet muss man wissen was schnell sein soll und was langsam sein sollte oder darf.
Ich hatte mal bei Bouncy Dolphin das Problem, dass alles an sich ganz schnell lief, aber beim Profiling auf eine Methode fast 40% der Zeit ging, die nur den aktuellen Punktestand auf das Canvas zeichnete. Nach viel hin und her Probieren kopierte ich den Inhalt eines Canvas mit dem Punktestand auf das Haupt-Canvas. Das Canvas mit dem Punktestand wurde nur neu gezeichnet wenn sich der Punktestand auch änderte. Danach verbrauchte die Methode nur nach 15%. Also war es schneller das gesamte Canvas zu kopieren als eine oder zwei Ziffern zeichnen zu lassen.
document.getElementById["aaaaa"].value=score verursacht z.B. auch extrem hohe Kosten. Also immer alle wichtigen Elemente in Variablen halten und nicht jedesmal neu im Document suchen!
Wärend man in Java extrem mächtige Tools wie VisualVM hat und der Profilier des Firefox oder Chrome einem bei JavaScript Problem sehr gut hilft, ist die Situation bei PHP etwas umständlicher. Zwar kann man so gut wie immer XDebug verwenden, aber so einfaches Remote-Profiling wie mit VisualVM ist da nicht zu machen.
Aber da man meistens sowie so lokal auf dem eigenen PC entwickelt und testet, reicht es die Daten in eine Datei schreiben zu lassen und diese dann mit Hilfe eines Programms zu analysieren.
Aber ich habe bis jetzt WinCacheGrind verwendet. Damit ließen sich nach etwas Einarbeitung dann schnell heraus finden, wo die Zeit verloren ging und welche Methoden wie oft aufgerufen wurden.
Der Class-Loader durchsuchte das System-Verzeichnis zu oft, weil an der Stelle nicht richtig geprüft wurde, ob die Klasse schon bekannt war. So konnte ich die Ladezeit einer Seite in meinem Framework am Ende nach vielen solcher Probleme von 160ms auf ungefähr 80ms senken. Viel Caching kam auch noch dazu und das Vermeiden von Zugriffen auf das Dateisystem.
Aber es gibt noch andere Profiler als XDebug für PHP. Hier findet man eine gute Übersicht:
PHP Profiler im Vergleich
Ich hab schön öfters gehört, dass solche Test und das Profiling ans Ende der Entwicklung gehören und man so etwas nur macht wenn man keine andere Wahl hat. Aber am Ende findet man viele Fehler dabei und ich halte es für falsch nicht schon am Anfang zu testen ob eine Anwendung auch später mit vielen produktiven Daten noch performant laufen wird. Denn am Ende sind grundlegende Fehler in der Architektur schwerer und auf wendiger zu beheben als am Anfang oder in der Mitte der Entwicklung.
Nachträglich an einzelnen Stellen Caching einzubauen ist auch nicht so gut wie von Anfang an ein allgemeinen Caching-Mechanismus zu entwerfen, der an allen relevanten Stellen automatisch greift.
Deswegen sollte man auch schon ganz am Anfang immer mal einen Profiler mitlaufen lassen und gucken, ob alles so läuft wie man es sich dachte.
Da es ja eigentlich um Web Frontend-Tools geht fehlt mir dabei etwas eine Übersicht zu den CSS-Frameworks, da diese doch schon sehr oft verwendet werden. Bootstrap, Foundation und UIKit hätten mich dabei sehr interessiert. Ich würde jetzt spontan vermuten,dass Bootstrap deutlich vorne liegen würde.
Bei den JavaScript Frameworks bin ich aber der Meinung, dass z.B. Frameworks wie AngularJS und jQuery eher schlecht mit einander zu vergleichen sind. jQuery arbeite auf einem viel nähren Level am DOM und AngluarJS durch sein Templating und Databinding auf einem eher höheren Level angesiedelt ist. Wenn man viel mit dem DOM arbeitet ist jQuery natürlich sehr von Vorteil. Bei AngularJS muss man dann öfters auf eigene Direktiven zurück greifen.
Wenn man schnell Prototypen mit grundlegenden Funktionen und paar Dummy-Daten bauen will ist AngularJS aber sehr viel besser. Man muss meistens nur das HTML-Layout um die AngularJS eigenen Attribute ergänzen und hat dann schon nach wenigen Minuten gefüllte Listen und Selects. Gerade bei Listen und Selects spielt AngularJS seine Vorteile, dann mit ein ng-repeat oder ng-options ist in wenigen Sekunden zuschreiben, wärend das Erzeugen und Befüllen und Hinzufügen von Options und LIs sehr viel aufwendiger ist.
So hat man sehr viel schneller etwas wo man meistens dann am Ende nur noch die AJAX-Request ergänzen muss um richtige Daten anstelle der Dummy-Daten zu haben.
Wenn ich aber Klick-Koordinaten in einem DIV oder einem CANVAS berechnen möchte und mit der Metrik der Elemente arbeite, dann ist natürlich jQuery die erste Wahl.
Bei den Frameworks wird also einfach zu viel einfach zusammen geworfen und in Konkurrenz gesetzt was nie konkurrieren wollte oder sich eher noch perfekt ergänzen kann. Es gibt Artikel darüber wie AngularJS und React.js. Google und Facebook zusammen kann toll sein.
Bei den Module Bundlers kann ich nur zustimmen, dass die eine tolle Sache sind und ich bei meinem cJS auch RequireJS als Möglichkeit eingebaut Controller zu laden. Aber auch ist selbst benutze es irgendwie nie. Bei großen Anwendungen ist es bestimmt toll und eine Art JS-Class-Loader. Aber bei kleinen Anwendungen mit 6 Controllern ist das einfache einbinden irgendwie übersichtlicher.
Aber an sich sind die toll und man sollte sie viel öfter verwenden. Leider werden alle Controller am Anfang direkt instanziert. Ideal wäre es wenn der Controller erst geladen wird, wenn er das erste mal auch wirklich angesprochen wird. Also die Bindings auch erst erstellt werden, wenn diese das erste mal in Aktion kommen.
So ein Framework würde sicher viel Speicher sparen.
Ein wirklich gutes Buch. Der Vorteil ist, dass Kapitel so geschrieben sind, dass man auch mal welche überspringen kann. Zum Beispiel das Kaptiel über Sourcecode Management Systeme wie SVN oder CVS werden heute kaum noch jemanden neues zeigen können.
Auf die Zusammenfassungen am Ende der Kaptiel und des gesamten Buches sind toll. Es gibt Listen wie es laufen sollte, wie man es verbessern kann und welche Anzeichen dafür sprechen, dass Verbesserungsbedarf besteht.
Ich fand das Kapitel über Daily-Meetings und "The List", also priorisierte Todo-Listen wirklich gut und sie gaben mir neue Denkanstöße. Ich werde mal versuchen Daily-Meetings in meinen Arbneitstag einzubringen und umzusetzten.. mal sehen was mein Chef dazu sagt :-)
Ich kann jedem Entwickler, Projektleiter und Kontakt-Person, die mit einem der beiden erst genannten für einen Kunden Kontakt halten muss empfehlen.
Denn wenn der Kunde die Probleme der Entwickler versteht und der Entwickler die Probleme der Kunden (etwas technisches zu Formulieren und Zeiten abschätzen zu können), dann kann man viele Missverständnisse schon mal vermeiden. Und dieses Buch ist einfach formuliert mit Reallife-Beispielen und könnte als neutraler Dritter zwischen beiden Seiten einen gemeinsamen Konsens vermitteln.
Der erste Release Candidate von PHP 7 ist verfügbar und der auch von HHVM gibt es eine neue Version. Ich würde mir beides gerne mal ansehen. Aber ich habe nicht die Zeit mir alles komplet einzurichten und mir noch extra ein Linux zu installieren. Ich benutze Windows und werde auch erstmal dabei bleiben. Also fällt leider HHVM schon mal für einen kurzen Test raus. Aber PHP7 ist für Windows verfügbar und auch Bitnami bietet schon ein WAMP-Paket mit PHP7 an. Also werde ich mir das in den nächsten Tagen mal ansehen. Einmal kurz gucken, ob aoop darauf funktioniert oder nicht. Ich bin mal gespannt.
Gerade beim Laden großer Datenmengen wie Lagerstrukturen oder bei Exporten ganzer Datenbestände, kommt man schnell in Bereiche, wo das Laden und Aufbereiten mehr als ein paar Minuten dauern kann. Bei normalen Desktop-Programmen und Skripten ist das nicht ganz so relevant. Wenn man aber im Web-Bereich arbeitet, kann es schnell zu Problemen mit Timeouts kommen. 3 Minuten können hier schon ein extremes Problem sein. Asynchrone Client helfen hier, aber keiner Wartet gerne und Zeit ist Geld.
Es gibt dann einen Punkt, wo die Zeit pro zu ladenen Element sich nicht mehr weiter verringern lässt. Hier hilft dann nur noch die Verarbeitung der einzelnen Elemente zu parallelisieren. Bei Java gibt es den ExecutorService, in JavaScript die WebWorker und in PHP gibt es pthreads. Es ist nichts für Leute mit einem Shared-Hosted Webspace, weil man eine Extension nach installieren muss.
Hier ist ein kleines Beispiel wo eine Liste von MD5-Hashes erzeugt werden soll. Die Threaded-Variante lief bei mir meistens fast doppelt so schnell
wie die einfache Variante mit der Schleife.
Man kann also auch in PHP moderne Anwendungen schrieben die Multi-Core CPUs auch wirklich ausnutzen können und muss sich hinter Java in den meisten Bereichen nicht mehr verstecken.
Nachdem ich noch bei einem Abschiedsessen mit meinen alten Kollegen, doch noch mal auf der Thema der Entwicklungsgeschwindigkeit und Qualität an dem Abend gekommen bin, werde ich mir dieses Thema hier doch mal annehmen. Es ist ein kompliziertes Thema, dass keine richtige einzelne richtige Lösung kennt, aber dafür Raum für viele Fehler bereit hält. Ich stütze mich jetzt einfach mal auf 10 Jahre Erfahrung in der Softwareentwicklung und der Mitarbeit in Teams, die eben auch mit diesen Problemen zu kämpfen hatten und auch noch haben. Denn auch wenn man Lösungen kennt, muss man den Weg immer noch gehen.
Neben der verlorenen Zeit stellen diese Probleme auch für die Entwickler eine nicht zu unterschätzende Belastung da.
Frameworks vs eigenen Code
Einer der größten Fehler wurde gleich am Anfang gemacht. Es sollte schnell los gehen und da wurde auf Abstraktion und der Suche nach vorhandenen Lösungen verzichtet. Es wurde alles auf der untersten Ebene begonnen. Also keine Kapselung oder ähnliches. Entitäten-Objekte wurden direkt vom Service an den Client geschickt. Eine allgemeine Kommunikationsstruktur zwischen den beiden wurde nicht entwickelt.
Oberflächen und Logik wurden einfach zusammen in eine Klasse geschrieben. DTOs, DAOs und DataBindung waren aber schon da keine neuen Konzepte mehr. Das alles führte dazu, dass man sich mit EJB und SWT jeweils auf der untersten Ebene auseinander setzen muss, selbst um einfache Oberflächen und Service zu implementieren.
Es entwickelte sich zu der Vorgehensweise, dass man es lieber alles schnell selbst machten sollte, als externe Frameworks und Libs zu verwenden. Wenn man nur genug eigene Dinge implementieren würde, würde am Ende schon ein fertiges Frameworks dabei heraus kommen. Das Ein Framework in seiner Gesamtheit durchdacht sein muss und eine gewisse Konsistenz in der Benutzung und im Verhalten zeigt, war dabei egal. Die Idee, jeder Entwickler würde mal so nebenbei für sich ein oder zwei Komponenten entwickeln und wenn man nach einem Jahr alles zusammen wirft, würde ein fertiges GUI-Framework heraus kommen, war zu verlockend und so wurden auch alle komplizierteren Ansätze, die so etwas beachten wollten, als nicht notwendig erachtet.
Wenn man ein auch nicht mehr ganz so neues AngularJS nun betrachtet, dass einmal für die GUI-Elemente auf HTML5 setzen kann und für die Oberflächen eine sehr gute und flexible Template-Engine mitbringt, merkt man erst wie viel Zeit allein mit dem Kampf des SWT-Gridlayouts oder der selbst gebauten Input-Box für Zahlenwerte verbracht wurde.
Das Problem, dass zu viel grundlegende Technologie selbst entwickelt wird und dann alles zu sehr mehr der eigentlichen Anwendungslogik verzahnt wird, ist in so fern ein wirklich großes Problem, als dass hier sehr schnell sehr viel Code produziert wird und durch die fehlende Abstraktion Änderungen mit fortlaufender Zeit immer schwieriger werden. Am Anfang müsste man einige Klassen neu schreiben, aber ein Jahr später, kann man schon die halbe Anwendung weg werfen. Ob man das vielleicht auch tun sollte, werde ich später noch mal ansprechen.
Jedenfalls braucht man entweder jemanden aus dem Team der das Framework für das Team(!) entwickelt und auch die Zeit dafür bekommt oder aber man muss einige Woche am Anfang einplanen, um ein geeignetes Framework zu finden.
Hier lauter schon der nächste Fehler. Oft wird eine Person dazu abgestellt, sich über Frameworks zu informieren und eins oder zwei vorzuschlagen. Da aber viele Entwickler damit arbeiten sollen, sollten auch alle bei dem Findungsprozess mit wirken können. Jeder achtet auf andere Dinge und erkennt Vor- oder Nachteile wo andere nur eine weitere aber nicht so wichtige Komponente sehen. Und auch hier werde ich auf die Probleme,
die hierbei entstehen können, später noch mal eingehen. Es hängt alles zusammen und beeinflusst sich gegenseitig, so führen Probleme zu anderen Problemen.. vielleicht.
Vertrauen in die Technologie muss da sein
Gehen wir mal davon aus, dass wir nun jemanden haben, der das Framework entwickelt oder man eines gefunden hat, das auf dem Papier echt toll aussieht, aber viele Fehler hat und Lösungen dafür kaum zu finden sind.
Das kann an Fehler, einer schlechten Dokumentation oder einem eher ungewöhnlichen Benutzungskonzept liegen. Aber am Ende besteht das Problem, dass die Entwickler dem Framework nicht vertrauen. Das für dann oft auch zu Punkt 1 zurück, in dem dann lieber eine Funktionen und Methoden geschrieben und verwendet werden, weil man diesen mehr traut als dem Framework. Weiter werden dann mindestens 2 Entwickler das Selbe nochmals neu implementieren, aber natürlich dann so verschieden, dass man nicht eines davon wieder abschaffen könnte. Wenn diese mindestens Doppelung an gleicher Funktionalität auffällt, muss das Framework so angepasst werden, dass es mindestens seine und die beiden anderen Funktionsweisen abbilden kann und hoffentlich dabei nichts kaput geht. Dadurch haben wir dann wieder eine große Inkonsistenz Framework, weil es plötzlich Sachen machen soll, die einfach anders sind und anderer Herangehensweisen haben. Weil es inkonsistent geworden ist kommen die Entwickler nicht mehr wirklich damit klar und schreiben sich im besten Falle eine eigene Abstraktionsschicht für das Framework, oder versuchen es wieder zu umgehen, was dann am Ende mindestens die 4. Implementation für die selbe Funktionalität mit sich bringt.
Ich ziehe hier mal wieder AngularJS als positives Beispiel heran. Wenn man ein Problem hat, wird man eine Lösung im Internet finden. Irgendwer hatte das Problem schon und irgendwer hat den Fehler schon behoben, die richtige Vorgehensweise noch mal erklärt oder eine passende Direktive geschrieben. Es stellt sich nicht die Frage, ob etwas an sich möglich ist. Es ist möglich und man versucht es erst einmal und wenn es nicht funktioniert, guckt man eben wie die anderen es gelöst haben. Im Notfall gibt es immer noch das native JavaScript mit document.getElementById().
In Java versuchen Frameworks einen oft komplett in sich gefangen zu nehmen und alle anderen Wege als den eigenen unmöglich zu machen. Durch Interfaces die eingehalten werden müssen, klappt es ganz gut. Das verhindert, dass andere Lösungen entwickelt werden, die das Framework um gehen. Aber es schränkt oft auch mehr ein als es hilft. Das Framework soll dem Entwickler helfen und nicht über ihn bestimmen. Als Entwickler mag man es nicht, nur die Konzepte und Denkweisen eines anderen unterworfen zu sein, der, wie man schnell merkt, das ganze nicht mit dem Anwendungsfall im Hinterkopf entwickelt hat, den man selber gerade umsetzen möchte.
Deswegen muss ein Framework alles bieten und so flexibel sein, dass auch Abweichungen vom Konzept möglich sind und sich direkt ins Framework integrieren lassen, dass es zu einem Teil des Frameworks wird. So wird verhindert, das Entwickler das Framework umgehen oder eigene Lösungen einbauen, die zwar den Anwendungsfall entsprechen aber sich komplett als Fremdkörper im Framework präsentiert. Das wichtigste ist aber eine gute Doku und eine zentrale Stelle wo man Probleme zusammen beheben kann. Für ein eigenes Framework ist daher ein Forum im Intranet vielleicht gar nicht so verkehrt. Man kann suchen, nachlesen und diskutieren. Auch weiß der Entwickler des Frameworks, wo er die Dokumentation verbessern oder nochmal überarbeiten sollte. Auch werden Ansätze etwas neu zu schreiben oder zu umgehen schneller erkannt und es kann mit Aufklärung oder Fehlerbehebung und neuen Features darauf reagiert werden.
Ich habe auch schon erlebt, dass ich von einer Lösung erfahren habe, wie man etwas im Framework bewerkstelligen kann und ein Ergebnis erhält wie man es möchte und das auch schon von einige Entwicklern so eingesetzt wurde und die auch ganz Stolz auf diese Lösung waren. Das Problem war nur, dass das Framework an der Stelle eigentlich genau das liefern sollte, was die über Umwegen dann auch bekommen haben und eine einfache kleine
Meldung bewirkt hätte, dass aufgefallen wäre, dass es ein einfacher Bug im Code war, der dann auch in 5min behoben war. Aber dadurch dass eine alternative Lösung jetzt ein falsches Ergebnis erwartete, war es viel Arbeit alles mit der Fehlerfreien Komponente des Frameworks wieder zum laufen zu bekommen.
Da fehlte dann auch das vertrauen ins Framework. Denn wenn man Vertrauen hat und etwas nicht wie erwartet funktioniert, geht man von einem Bug aus und nicht von einem normalen Verhalten, dem man selbst entgegen wirken muss.
Entscheidungen überdenken und schnell reagieren
Manchmal klingt etwas sehr gut und die Beispiele liefen gut und die Tutorials im Internet ging schnell von der Hand. Entität anlegen, laden, ändern, löschen und eine Liste der vorhandenen Entitäten laden. Alles super.
Aber dann kommt die Komplexität der echten Welt, wo man nicht nur Listen lädt und etwas hinzufügt oder ein Element hinzufügt. Hier beginnen Probleme und manchmal zeigt sich erst hier, ob dass alles wirklich so gut war wie gedacht. Bei JavaFX kann ich einfache DTOs in Tabellen verwenden. Wenn sich aber ein Wert in einem der DTOs ändert wird es nur erkannt, wenn es ein Property ist. Das ist dann plötzlich ein Sprung von "geht ja ganz einfach" zu "jetzt muss alles in Properties umkopiert werden und die normalen Getter und Setter reichen nicht mehr und also doch wieder eine Wrapper-Klasse bauen."
Oder wir treffen auf das Problem aus Punkt 1. Entweder probieren wir es erst einmal weiter und bauen erst einmal eine Version und damit und gucken dann mal oder aber wir haben uns doch am Anfang darauf festgelegt und die Entwickler haben gerade gelernt damit umzugehen.. oder aber ganz radikal: Zusammen setzen, noch mal Alternativen suchen und wenn es was gibt schnellst möglich wechseln. Erstmal mit einer nicht passenden Technologie oder so einem Framework weiter zu arbeiten ist das schlimmste was man machen kann. Denn es müssen Teile neu geschrieben und angepasst werden und dass sollte man machen, wenn noch nicht zu viel davon entstanden ist. Wenn man ein Jahr wartet, wird es zu viel und die Ansicht wird sich durch setzen, dass fertig machen nun doch schneller geht als "neu" machen. Es wird aber mit den Jahren immer langsamer und langsamer entwickelt und es zeigt sich, dass die Annahme falsch war und man doch schon viel weiter wäre, wenn man gewechselt hätte.
Nie mit etwas entwickeln was Probleme macht ohne das die Möglichkeit gegeben ist, das entwickelte später in einem besseren Technologie-Kontext weiter verwenden zu können. Hier Zahlt sich Abstraktion wie MVC/MVVM oder auch einfaches Databinding dann schnell aus, wenn man mit einfachen DTOs und POJOs gearbeitet hat.
Hier ist aber oft die Angst vor dem Mehraufwand und auch vor neuen Technologien das Problem, was die Entwickler daran hindert, schnell und angemessen zu reagieren. Denn die Entwickler kennen fehle Technologien und Frameworks und können bestimmt eine oder zwei Alternativen nennen. Man sollte immer dafür offen sein, dass es etwas besseres gibt und vielleicht ein Umstieg die Zukunft einfacher macht. Auch ohne zu große Probleme sollte so ein Vorschlag immer mal wieder überdacht werden. Es kann auch helfen sich andere Lösungen anzusehen und davon zu lernen in dem man Konzepte übernimmt (wenn diese dann in die alte Struktur passen!)
Ich habe bei meinen Frameworks, die ich so geschrieben habe gelernt, dass man manchmal einfach alte Dinge weg werfen muss, Kompatibilität gut ist aber nicht bis in die Steinzeit reichen muss und man teilweise ein neues Framework anfängt, dass alles besser machen soll und am Ende portiert man es in das alte Framework zurück und wundert sich wie flexibel man das erste doch entwickelt hat, dass man die Konzepte am Ende auch dort in wenigen Stunden komplett implementieren konnte.
Mutig sein und Entwickler dafür abstellen sich auf dem Laufenden zu halten und die Aufgabe zu geben Vorhandenes zu hinterfragen und zu kritisieren.
Die eine zukunftssichere Technologie
Damit kommen wir direkt zum nächsten Problemkomplex. Es wird analysiert und diskutiert und sich für eine Technologie entschieden. Das geht auch erst einmal ganz gut und so lange niemand danach über den Tellerrand schaut bleibt auch alles gut.
Um eine Technologie für ein Projekt, das auch mal mehrere Jahre laufen wird, muss sie stabil sein, gut zu benutzen, es darf sich nichts groß an ihr ändern, damit man nicht dauernd alte Module anpassen muss und sie sollte gut unterstützt werden (also schon viel im Internet darüber zu finden sein). Das alles ist am Anfang gegeben. Aber es soll ja auch so bleiben. Eine Technologie bei der sich in 3 Jahren nichts mehr groß ändern wird ist an sich tot. Was vor paar Jahren noch sehr toll war z.B. SOAP-Webservice über Annotationen zu erzeugen wird heute keiner mehr wirklich benutzen wollen. SOAP war mal komfortabel, wirkt heute aber einfach umständlich im Vergleich zu REST-Services.
Es gibt keine Technologie, die über Jahre hinweg die beste und einfachste Lösung bleibt. Man kann sich aber auch modernen Entwicklungen nicht komplett entziehen. Das Grundsystem wie der Application-Server und das GUI-Framework sollten immer bei neuen Versionen mit geupdatet werden. Es bedeutet nicht, dass die produktiven Server jedes mal ein Update erhalten müssen, aber die Anwendung sollte immer auch auf der aktuellsten Version laufen können. Das kostet den Entwickler natürlich immer etwas Zeit, aber sollt wirklich mal ein Wechsel der Produktivumgebung anstehen, wird dies wenigstens kein Problem mehr sein und es entsteht kein Zeitdruck alles
doch noch schnell auf die neue Version anzupassen. Wir wissen ja das solche Ankündigen nie rechtzeitig vor her kommuniziert werden.
Es muss nicht immer eine neue Technologie sein, aber wenn man bei der Entwicklung der benutzen Technologie nicht mit macht wird man schnell Probleme bekommen und von allen Vorteilen der neuen Versionen nicht profitieren können. Das deprimiert die Entwickler und gibt denen das Gefühl, als würde man ihnen bewusst Steine in den Weg legen. Man siehe nur den Wechsel von EJB2 auf EJB3.
Jeder Entwickler ist anders
Wir brauchen ein Konzept, damit nicht alles wild durch einander geht und jeder so programmiert wie er gerne möchte und kein Modul aussieht wie das anderen. Also soll jemand festlegen, wie der Code-Style, die Packages und die Oberflächen auszusehen haben. Das geht natürlich ganz schnell, es wird programmiert wie man es selber machen, weil man ist überzeugt von seinem vorgehen und man selbst kommt damit ja super zurecht. Oberflächen guckt man sich seine Anwendungsfälle an... andere werden ja wohl keine Anwendungsfälle haben, die sich von der Struktur her groß unterscheiden. Aber leider dreht sich die Welt nicht um einen. Jeder kommt mit seinen Sachen gut zurecht, sonst hätte man es ja schon längst geändert. Also muss man davon ausgehen, dass auch der der die Dinge entwickelt hat, mit denen wir nicht zurecht kommen, damit super zurecht kommt. Also sich im Team zusammensetzen und am Besten mit offenen Standards anfangen. Ein Tab ist fast immer 4 Zeichen lang. Warum sollte man 3 nehmen? Eine persönliche Vorliebe, weil man ein besseres Lesegefühl dabei hat? So etwas hat sich nicht umsonst durchgesetzt und es haben sich Menschen Gedanken gemacht. Wichtig ist zu realisieren, dass vor einem schon andere Leute über solche Dinge nachgedacht haben und diese Leute auch nicht dumm waren oder sind. Wer glaubt er hätte die einzige wahre Lösung gefunden und jegliche kleine Abweichung wäre falsch, der sollte alles wegwerfen und noch mal von vorne beginnen.
Das Framework sollte verschiedene Ansätze von sich auf unterstützen. JavaFX mit Objekten, FXML, HTML im Web-View und auch sonst noch die alte SWT-Variante. Klingt nach viel, aber es gibt für jeden dieser Ansätze einen Anwendungsfall wo er besser als der Rest ist. Das Framework sollte den Entwickler unbemerkt dazu bringen, dass egal wie er an die Aufgabe heran geht, der Code am Ende den der anderen Entwickler ähnelt. Gleich wird der Code nie sein. Es ist schwer so ein flexibles Framework zu entwickeln, wo sich jeder ransetzen kann und ohne viel Lernen und Anpassungen damit anfangen kann zu entwickeln. Databindung oder direkt Zugriff auf das Element.
POJOs oder komplexe Beans. Wiederverwendbare Komponenten oder eine Komponente aus einzelnen kleinen Komponenten direkt beim Aufbau der GUI konstruieren. Alles ist manchmal nötig und manchmal ist das Gegenteil der bessere Weg. Aber nie ist eines davon an sich falsch. Jeder Entwickler ist anders und geht anders an Probleme heran und in einem Projekt sollte es nie so sein, dass sich die Entwickler darin an einen anderen anpassen müssen, weil sie dann nicht mehr die Leistung bringen, die sie könnten.
Unit-Tests
Unit-Tests sind meiner Erfahrung oft eher Belastung als eine Hilfe. Ein wirklich guter Test braucht Zeit und meistens sind diese Test nichts weiter als Entität speichern, laden, freuen, dass der selbe Wert drin steht, wie beim Speichern. Bei Berechnungen sind die Tests super, weil man schnell prüfen kann, ob eine Berechnung noch korrekt ausgeführt wird. Aber für komplexe Workflows und Anwendungsfälle sind diese Tests meistens sinnlos. Ein paar gute Tester bringen mehr als Unit-Tests. Lieber keine oder wenige Unit-Tests und dafür genug Tester haben. Ein Tester ist ein Mensch und für Schnittstellen, die von Menschen verwendet werden, sind Menschen die besseren Tester,
weil sie an Dinge unterschiedlich heran gehen. 2 Tester können eine Workflow-Schritt durch testen und 2 unterschiedliche Fehler finden, während der Entwickler ohne Fehler getestet hat.
Bloß weil etwas toll ud hip ist, ist es für das eigene Projekt nicht auch immer die beste Lösung. Man muss gucken, ob es einen etwas bring und sich klar sein, dass es nicht die eine richtige Lösung für alles gibt. Unit-Tests für Services sind toll und für GUIs meistens vollkommen unbrauchbar.
Dokumentation ist genau so ein Thema. Ein freier Text kann viel mehr erklären wie ein JavaDoc, wären JavaDoc toll ist während des Programmieren kleine Infos zur Methode zu erhalten. Aber brauch ich eine Info was die Methode load($id) macht?
Team-Leader und Lead-Developer als Unterstützung und nicht als Diktatoren
Ich hatte ja schon mehr Mals im Text erwähnt, dass man viele Dinge im Team klären muss und nicht eine Person, wichtige Dinge für alle entscheiden lassen sollte. Es ist die Aufgabe eine Lead-Developers das Team zu fördern und die Leistung zu steigern und dem Team die Probleme vom Hals zu halten. Es ist nicht die Aufgabe des Teams alles zu tun um dem Team-Leader zu gefallen. Lead-Developer und Team-Leader sind undankbare Jobs und man muss sie machen wollen. Wenn man das nicht will und nur etwas mehr zusagen haben möchte, ist man dort falsch. Auch wenn man nur immer zu allen "Ja" sagt, was von oben kommt und dann die Probleme direkt nach unten zum
Team leitet.
Wenn das Team das Gefühl hat sich in bestimmten Situationen nicht auf den Team-Leader verlassen zu können, hat man ein Problem. Es muss deutlich sein, dass er Verantwortung übernimmt und hinter oder besser noch vor seinem Team steht.
Das selbe gilt für den Lead-Developer und seine Entscheidungen. Er muss Erfahrung haben und seine Entscheidungen erklären können und auch die Verantwortung dafür übernehmen, wenn er eine falsche Entscheidung getroffen hat und den Mut haben diese zu Korrigieren. Wenn also ein falsches Framework ausgewählt wurde mit dem kein Entwickler zurecht kommt, ist es sein Fehler und nicht der Fehler der Entwickler. Dann muss er handeln und
den Fehler beheben.
Fazit Das waren jetzt meine groben Gedanken zu dem Thema und meinen Erfahrungen. Es ist aber klar, dass zur Behebung eines Problems erst einmal das Gespräch gesucht werden muss, denn die Entwickler wissen schon meistens sehr genau was schief läuft. Eine Lösung für das Problem müssen die aber deshalb nicht präsentieren können. Wenn nicht ganz klar sein, sollte wo das Problem liegt und man wirklich mit dem Projekt in Bedrängnis kommt, sollte man sich jemanden holen der Erfahrung hat und solche Situationen kennt und am besten mal durchlebt hat. Auch hier wieder die Feststellung, dass vieles immer sehr ähnlich ist und man von den Problemen und Fehler der anderen oft sehr viel lernen und dann verwenden kann.
Solche Leute sind nicht günstig, aber wenn man mal dagegen rechnet wie viel Zeit eingesperrt werden kann, sind die oft ihr Geld wert.
Probleme innerhalb des Teams könnte auch da sein. Aber das ist ein sehr sensibles Thema und dort gibt es noch weniger als bei den deren Problemfeldern keine einfache Lösung.
Wenn man ein Angestellter Entwickler ist und in relativ großen Teams an interner Software arbeitet, die nur durch andere Abteilungen verwendet wird, wird man nicht wirklich über den Begriff des ROI (Return of Investment) stolpern. Wenn man aber eine kleinere Firma hat und diese mit dem was entwickelt wird, ist dieser Begriff allgegenwärtig. Man bekommt nicht einfach erst einmal viel Gehalt und dann wird geguckt ob man etwas kann oder nicht. In großen Firmen ist es auch nicht so schlimm mal weniger zu können wenn man im Team arbeitet oder einfach erst einmal angenommen wird, dass man die Stärken und Begabungen noch finden muss und man vielleicht dafür eben auch mal das Team wechseln muss.
Außerdem ist es einfach schwer zu bestimmen wie hoch der ROI bei etwas ist. Was ist besser? Wenn ich von JavaFX auf AngularJS wechseln möchte und damit mir 3 Wochenarbeit spare oder wenn mein Teamleiter, der ja mehr verdient, selbst noch mal Zeit investieren muss um meinen Wunsch verstehen, bewerten und nachvollziehen zu können. Beides kostet Geld. Am Ende würde auch die Abteilung von den 3 Wochen profitieren. Entweder weil die die Anwendung 3 Wochen früher bekommen und 3 Wochen früher als gedacht produktiver arbeiten können oder weil die Zeit in weiter Verbesserungen fließt und dann die Abteilung noch effektiver und produktiver arbeiten kann.
In kleinen Firmen mit direkten Draht zu Kunden ist so etwas immer sehr viel einfacher zu messen. Ich kann pro Monat so und so viele Auftrage der Kunden erledigen und bringe so und so viel Geld. Geld ist messbar.. spätestens auf den Kontoauszügen.
Schwer den ROI zu bestimmen ist, wenn du interne Frameworks entwickelst. Weil es ist nichts was eine andere Abteilung oder ein Kunde jemals bemerken wird. Die anderen werden schneller Entwickeln und einen höheren ROI haben. Aber man muss sehr hinterher sein auch immer mal fest zu stellen, dass es auch am guten Framework liegt. In Meetings immer erzählen, was sich verbessert hat und am besten ein Beispiel bringen, was nun ganz einfach möglich ist, was vorher andere viel Zeit gekostet hat. Ein gutes Framework ist für den Anwender unsichtbar.. ein schlechtes.. dann wird man nicht so schnell übersehen.
Am Ende finde ich es aber doch momentan sehr gut, direkt mit so etwas zu tun zu haben. Etwas wo Zeit Geld ist und gute Lösungen, die einen Zeit sparen, nicht als etwas neues und damit potenziell unsinniges gesehen wird und Zeitersparnis eher neben sächlich ist.
Vor einiger Zeit kam bei der Arbeit eine Email herum. Irgendwer wollte gerne wissen mit welchen Zeitschriften und Homepages sich der Informatik-Bereich informiert und weiterbildet. Da wenn man den Durchschnittbetrachtet natürlich nur Heise und die c't übrig blieb, hab ich mir mal meine eigene kleine Liste gebastelt. Auch um selbst mal einen Überblickt zu bekommen, wo meine Infos und mein Wissen teilweise herkommen.
Es sind alles Seiten, die einen gewissen Output pro Tag/Woche haben. Es gibt viele tolle Blogs, aber meistens kann man die sich auch schnell komplet durchlesen und muss dann wieder Wochen warten, bis was neues kommt. Es steht sehr viel sehr nützliches in solchen Blogs, aber für den täglichen "Gebrauch" sind sie eher nicht so geeignet.
Neben DevOps hört man viel über Microservices. Oft sogar zusammen. Der gute Gedanke bei Microservices ist meiner Meinung nach jeden Falls, dass eine gute Modularisierung angetrebt wird. Etwas was ich auch immer in meinen Projekten versuche, aber viele doch es immer wieder für zu kompliziert halten und bei riesigen monolithischen Klötzen bleiben wollen. Aber sich auch dann beschweren, dass das Deployment immer so lange dauert und dass einige Entwickler einfach so frech waren und ihre Methoden geändert haben. Bei diesen riesigen monolitisches Klötzen ohne Abschottungen neigen viele dazu direkt mit fremden Klassen oder NamedQueries zu arbeiten. Wenn ich aber eine Service-Fascade hat und dort meine Methode auf eine andere interne umleite, die sehr viel schneller ist als die alte und die alte entferne, kommen Beschwerden, weil die eine Methode nicht mehr auffindbar ist und ein anderer Teil der Anwendung jetzt nicht mehr funktioniert.
Antworten wie "Benutz einfach die Service-Methode, die liefert dir immer genau was du brauchst", sind dann aber nicht gerne gehört.
Microservices haben eben diesen Vorteil, dass viel mit Schnittstellen gearbeitet werden muss. Damit kommt dann vielleicht auch ein Gefühl dafür Service-Methoden kompatibel zu halten. Nicht einfach vorhandene Methoden von der Aufrufstruktur zu vrerändern, sondern eine neue Methode anzulegen und die alte dann mit standard Werten auf die neue weiter zu leiten.
Der einfachste Gedanke zu Microservices ist bei mir immer eine WAR-Datei. Eine Anwendung auch auf mehrere WAR zu verteilen. Die inter-Modul Kommunikation ist dann auch über URLs oder intern über vielleicht JNDI zu realisieren. Aber alles ist sehr isoliert und man kann einzelene
Teile deployen ohne dass andere auch neu deployed werden müssen.
In PHP habe ich das mit meinem Framework von Anfang an (bzw es hat sich entwickelt) so umgesetzt. Module sind 100%ig getrennt und ein Update eines Modules ist durch einfaches Kopieren in das richtige Verzeichnis möglich. Die Module orientieren sich an sich schon etwas an klassischen WAR-Dateien aus der Java-Welt. Jedes Modul bringt seine eigenen Klassen, seine eigene Admin-Oberfläche, seinen eigenen REST-Service und eben Views mit. Es ist nichts fest in Config-Dateien eingetragen, deswegen sich das System auch nicht beschweren kann, wenn ein Modul plötzlich weg ist. Das dynamische Zusammensuchen und Instanzieren von Modulen und Addons kostet natürlich Zeit, aber hält das System sehr flexibel und robust, weil meistens nichts vom Grundsystem vorraus gesetzt wird. Caching ist hier natürlich doch ein gewisses Problem, aber das kann man auch lösen. Meistens reicht es Module zu dekativieren und man muss sie nicht löschen. Neue Klassen werden einfach gefunden und Klassen bei denen sich der Pfad geändert hat sind nach ein oder zwei Refreshes meistens auch wieder da. Das System ist also im Notfall sogar in der Lage sich selbst zu heilen.
Aber in den meisten Fällen kommt ja immer nur neues hinzu.
Also jeden Teil einer Anwendung als eigenes Modul realisieren. Module isoliert von einander halten und so ein unabhängiges Deployment ermöglichen.
Ein wirkliches Problem sind dann nur Oberflächen und Oberflächen-Fragmente. Wären ich es oft über die Addons gelöst habe wäre es bei Anwendungen mit AngularJS und REST-Backend sehr viel einfacher über einzelene Templates zu realisieren, die dann immer bei Bedarf und Vorhandensein nachgeladen werden können.
Aber es ist und bleibt so erst einmal mit das größte Problem.
Wirklich "micro" sind die Services am Ende auch nicht, aber sie sind doch sehr viel kleiner und einfacher zu handhaben als eine riesige monolithische Anwendung, wo alles von einander abhängig ist und eine Änderung an einem Teil theortisch Auswirkungen auf andere Teile haben kann, weil man nicht sicherstellen kann, dass nicht andere Entwickler die geänderten Klassen wo anders auch direkt verwenden. Auch wenn Microservices nicht die Lösung für alles ist und viele Problem
dadurch auch nciht gelöst werden können, sollte man wenigstens das Prinzip der isolierten Module und deren Fähigkeit unabhängig von einander deployed werden zu können aus diesen Konzept mitnehmen. Wenn das Deployment dann nur noch 5 Sekunden an Stelle von 30 Sekunden dauert, hat man oft gefühlt schon viel gewonnen. (Ich hab mit solchen Zeiten gearbeitet und es ist sehr nervig immer solange warten zu müssen nur um eine kleine Änderung in einer Zeile testen zu können!)
Irgendwie hört man momentan über all von DevOps. Ein DevOp ist wohl jemand der nicht nur entwickelt sondern auch den operativen Betrieb mit überwacht und diesen vielleicht auch komplett in Eigen-Regie betreut. Jedenfalls liest man solch eine Interpreation oft (ob diese jetzt die korrekte Interpreation ist sei mal dahin gestellt...).
Dieses Konzep ist jetzt nichts neues. In kleine Firmen ist sowas einfach normal (und läßt sich nicht ändern, weil man einfach zu wenig Personen hat und man alles eben übernhmen können muss) und in großen Firmen setzt sich sowas wohl auch immer mehr durch. Wenn man meine Arbeit betrachtet, könnte man auch mich als DevOp bezeichnen.
Dann wäre ich voll hip und modern. Aber am Ende will ich dass nicht unbedingt sein. Arbeitsteilung ist an sich gut und bringt viele Vorteile:
* Man kann sich auf eine Sache konzentrieren
* Wissen ist nicht in einer Person konzentriert (Wenn diese Person ausfällt bleibt Wissen vorhanden)
* Es ist alles transparenter, da mehrere Leute eingebunden sind
* Man kann sich nicht überall perfekt auskennen, deswegen sollte man nichts machen, wo man sich nur halb auskennt, wenn jemand da ist der sich damit besser auskennt
Warum aber gibt es diesen DevOps-Gedanken und warum soll damit alles so viel schneller und einfacher gehen?
* Weil es unglaublich schwer ist brauchbare Schnittstellen zwischen Teams und Abteilungen zu etablieren
* Weil es schneller geht etwas selber zu machen, als jemanden es zu erklären und einzuarbeiten
* Weil man nicht viel Doku schreiben muss, weil man es ja selber schon alles weiß
* Weil die Software so komplex ist, dass Deployment und Fehler-Analyse nur mit tiefgreifenden Kenntnissen der Software möglich ist
* Weil Menschen schlecht skalieren... weil Menschen bei der Zusammenarbeit viel Overhead erzeugen
Das Problem ist einmal die Schnittstellen innerhalb der Firma sowie deren Prozesse und einmal die Komplexität der Software. Gerade im Java-Bereich (JEE) ist es sehr ausgeprägt. Frameworks. Es gibt tausende von Frameworks. Für jeden Zweck und wenn man alles kombiniert und alles an Libs in den richtigen Versionen hat, hat man meistens schon so ein komplexes Konstrukt, dass es dann schon oft eine Tagesaufgabe ist den Workspace auf einem anderen Rechner einzurichten.
Einen JBoss/Wildfly zu installieren, zu starten und zu stoppen ist ja noch gut möglich. Datasources einrichten und Anpassungen vornehmen braucht schon etwas wissen. Wenn man dann für eine Anwendung noch eigene Module und Adapter braucht, wird es oft schon so speziel und spezifisch für die eine Anwendung, dass man ohne grundlegendes Wissen schnell Probleme bekommt.
JPA, Logging, Module + Versionen... alles exakt so einrichten, dass es so läuft wie auf dem Entwicklungsrechner.. viel Arbeit.
Bevor man nun anderen Personen alles erklärt und dann bei Problemen tausend nachfragen kommen, denkt man sich oft: "Mache ich es doch lieber selber!".
Also am Besten einfach alles genau so übernehmen wie es auf dem eigenen Entwicklungsrecher eingerichtet ist. Aber jede Änderung abgleichen ist natürlich auch doof. Deswegen wird all das möglichst mit in die Anwendung gezogen. Besonders die Konfiguration.
Ich erinnere mich noch an meine ersten Web-Projekte mit dem Tomcat. Damals noch mit Tomcat 4. DataSource hab ich in der server.xml eingetragen und mein Projekt als WAR deployed. Dann lief es. Es gab nur die DataSource mit einem bestimmten JNDI-Pfad. Wenn diese vorhanden war lief es. Die WAR jemanden zu geben, der sie dann deployte war kein Problem.
Aber dass war dann irgendwann nicht mehr so toll, weil für jede deployte Anwendung die server.xml anzupasen war nicht toll. Die Server wurden von Administratoren verwaltet, die aber sich nicht wirklich mit Tomcat auskannten und die zentralle server.xml anzupassen konnte natürlich dazu führen, dass andere Anwendungen dann nicht mehr liefen, wenn man was falsch machte.
Also wanderte viel die in context.xml. Mit JPA kam noch die persistence.xml dazu und weil man ja Unit-Tests machen wollte, hat man den Datenbank-Server dort direkt eingetragen und keine Datasources von der Server-Umgebung mehr verwendet. Das Logging ging auch gleich mit in die Anwendung und die Anwendung hat bestimmt in welche Datei gelogt wurde und was wie gelogt wird. Wenn man mal was anderes
Loggen wollte.. tja.. Anwendung neu bauen und neu deployen.
Wenn man jetzt noch mehr Framworks hat, die auch gerne Config-Daten haben wollen, nimmt man natürlich die auch gleich mit rein, weil der Entwickler es ja einmal alles eingestellt hat und man die Dateien dann nicht kopieren muss oder am Ende sogar noch mal komplet selbst anlegen muss.
Man bekommt also eine komplet vorkonfigurierte Anwendung die man dann deployed, die aber dann auch nur für diesen ganz speziellen Fall funktioniert. Datenbankserver ändern oder URLs zu externen System wechseln.. das geht nicht so einfach und die Anwendung muss komplett neu gebaut werden, wenn sowas mal passieren sollte.
Das macht natürlich alles für die Server-Admins simpler, da einen sauberen Server zu installieren einfach ist. Der Entwickler übernimmt dafür alles. Konfigurierbare Anwendungen sehe ich immer seltener. Was aber den Admins natürlich auch einen Teil der Kontrolle über die von denen betreuten Systeme nimmt und das gefällt natürlich auch nicht wirklich.
Was wären Lösungen? Schwer zu sagen. Meine Ideen wären:
* Anwendungen sollten möglichst "unkomplex" sein
* Die Anwendung sollte nicht vorkonfiguriert sein bzw die config sollte sich im Server überschreiben lassen
* Der Admin sollte sich mit der Umgebung auskennen und sollte wissen wie man die Anwendung und Umgebung konfiguriert
* Einfaches Deployment: Anwendung + Deployment-Descriptor (Config-Daten) in die Umgebung kopieren und Deployment starten
* Anwendungen sollten gut von ein ander isoliert sein
* Anwendungen sollten sich von Außen so gut anpassen und konfigurieren lassen, so das der Admin mit etwas Glück kleine Probleme beheben kann ohne das Code angefasst werden muss
* Die Umgebung aus AppServer/Servlet-Container mit einer Zusammenstellung der benötigten Frameworks sollten bei allen Projekten standardisiert werden. Also eine Person stellt immer aktuelle Zusammenstellungen zusammen, die dann von den Entwicklern verwendet werden und wenn möglich auch immer auf die aktuellen Versionen updaten.
Natürlich sollte sich jeder Entwickler grundlegend mit allem von AppServer bis zum Logging-Framework auskennen. Aber er sollte sich auf die Entwicklung konzentrieren und den normalen Betrieb der Anwendungen jemanden überlassen der die Serverumgebung sehr gut kennt und dort auch Performance- und andere Probleme lösen kann und die gesamte Infrastruktur verwaltet. Die Infrastruktur ändert sich laufend und die Anwendung sollte sich einfach und unkompliziert darauf anpassen lassen. Eine XML in einem Package in einer JAR im Lib-Verzeichnis einer WAR in einem Tomcat ist genau so schlimm, als wenn man die Daten direkt hart in eine Klasse kodiert hätte. Meiner Meinung nach müssen Config-Daten (ob aus einer Datei oder der Datenbank) zur Laufzeit änderbar sein.
Aber am Ende muss man sagen, dass ich auch schon oft genug gedacht habe "Hätte ich es doch einfach gleich selber gemacht...". Man braucht Vertrauen und einen Draht zu einander. Deswegen sollte man Teams vielleicht nicht horizontal aufbauen, sondern vertikal. Die Idee, dass einer alles macht, ist wohl auch weniger die grundlegende Idee hinter DevOps gewesen. Auch dass alles wieder in Software-Tools und so enden muss, sehe ich eher kritisch, weil man Komplexität oft nicht durch mehr Komplexität lösen kann.
Am Ende darf es eben nur ein DevOp-Team geben, wenn man das Konzept umsetzen möchte. Ein DevOp in einer Person ist unsinnig bzw bedingt sich selbst. Im Team müssen die Schnittstellen und die Rücksichtnahme zwischen den Fachbereichen geschafen und gelebt werden. Man sollte also Kompetenzen nicht versuchen zusammen zu fassen, sondern diese nur dichter zu einander bringen.
Du kannst keinen klaren Gedanken mehr fassen? Du hast das Gefühl dein Gehirn wäre geschmolzen und nur noch ein Haufen Matsch? Du hast eine komplexe Klassen-Struktur im Kopf und wunderst auf dem Weg zum Auto warum dein Autoschlüssel sich da nicht richtig einfügt?
Dann hast du wohl denn ganzen Tag Doku geschrieben.
Doku schreiben schlaucht einen irgendwie immer extrem. Endlose Listen von Klassen, die man alle beschreiben soll. Bei den meisten ist vom Namen her schon eigentlich klar was die machen und bei den wenigen Ausnahmen, weiß man nicht wie man es gut Beschreiben soll oder ob man gleich refactoren sollte.
Der der das Projekt übernimmt soll ja möglichst ohne die Doku damit zurecht kommen. Die Doku sollte nur zur Einleitung und bei Unstimmigkeiten bemüht werden.
Nach ein paar Wochen intensiven Doku-Schreibens habe ich mir folgende Regeln aufgestellt:
* Pausen machen und abschalten. Dann noch mal in Ruhe das davor geschriebene nochmal lesen bevor man weiter macht
* Die Punkte für den Tag aufschreiben und abarbeiten
* dazu am Besten noch sich den Roten-Faden vorher auf schreiben (habe ich am Anfang nicht gemacht und bereue ich jetzt sehr)
* Sich lieber mal wiederholen als irgendwelche Verweise auf andere Textstellen einbauen
* Immer auch beschreiben, warum etwas so gemacht wurde und welche Überlegungen und Ideen dahinter stehen
* Wenn man auf nicht mehr verwendete Klassen, Code, etc trifft.. sofort löschen
* lieber Refactoring als viel Text schreiben nur weil man bei einem Namen einer Klasse mal nicht gut überlegt hatte
* 10min schreiben oder 10min etwas aufräumen und in 5min beschreiben? Immer das zweite, denn dem der das Projekt übernimmt wird dadurch mehr Zeit sparen als du mehr aufgewendet hast
Was die Pausen angeht frage ich mich auch immer wieder, ob so etwas nicht fest zur Arbeitszeit dazu zählen sollte. Die Pause um den Kopf wieder so frei zu bekommen um gut weiter arbeiten zu können und Geschriebens noch mal mit Abstand neu zu betrachten geschieht nicht einfach so neben bei. Manchmal ist Pause machen schwieriger als weiter zu arbeiten, weil man sich zwingen muss jetzt an was ganz anderes zu denken... dann bleibt auch die Frage an was man dann denken soll.
Wie macht man effizient Pause?
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: