Da man beim einfachen Entwickeln nicht ein AWS S3-Bucket für die Entwickler bereit stellen möchte, kann man hier sehr gut MinIO verwenden. Es lässt sich schnell in docker-compose einbinden und die FileSystems von Shopware können den normalen S3-Adapter verwenden.
Jeder der schon mal mit PHP zu tun hatte wird sicher die Installationsanleitung von getcomposer.org. Das Problem ist nur, dass seit einiger Zeit Composer 2.0 installiert wird und einige alte Projekte damit echt ihre Probleme haben. Aber wie installiert man sich eine bestimmte Version? So das nicht plötzlich der Docker-Container nach einem neuen Build eine andere Composer-Version hat und die Pipeline nicht mehr funktioniert.
Man kennt Systeme wie Satis oder Toran die sich aus einem Git bei Änderungen den aktuellen Stand holen und ihn in Versionen für die Libs umwandeln. Man darf nicht vergessen die System zu triggern, um immer die aktuellen Version zu haben. Sonst ändert man was und wundert sich, dass sich nichts ändert.
Mit Gitlab kann man alles in einem haben und das in sehr einfach. Auto DevOps ist aber diesmal nicht die Lösung. Aber man braucht nur ca. 1 Minute um alles einzurichten.
1) Package Repository aktivieren (wenn noch nicht so)
2) Pipelines aktivieren (unwahrscheinlich dass es noch nicht ist)
3) auf der Startseite des Projekt "Setup CI" wählen
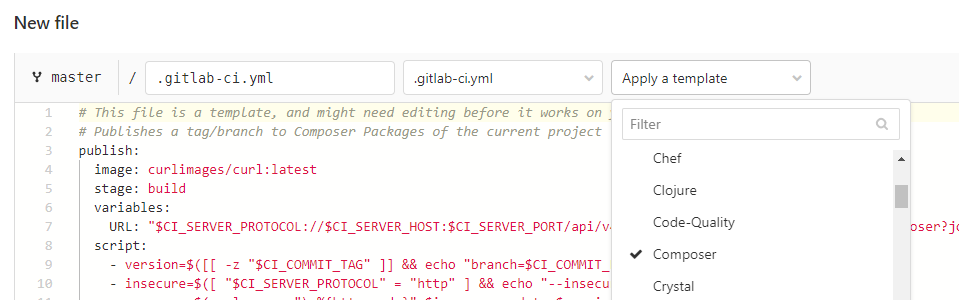
4) Bei den Templates "composer" auswählen und mergen
5) .. fertig
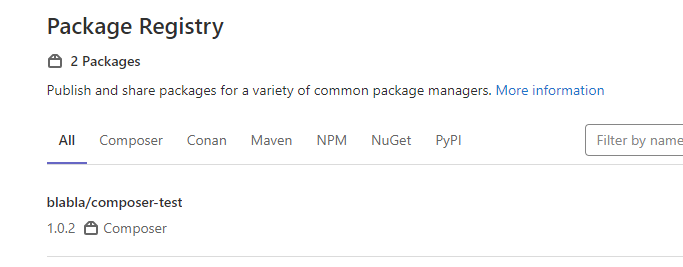
Schon findet man beim nächsten Push eines Branches oder Tags in der Package-Registry einen Eintrag für einem Composer-Package.
Um die Traefik Labels einzubauen hat man ja die Wahl diese im Image zu haben oder im Container. Während man die dem Container beim Starten geben kann, muss man die für das Image beim Build-Process schon haben. Ich benutze beides und muss sagen, dass ich an sich dafür bin die dem Container zu geben. Aber falls man sich mal fragt wie man dynamische Labels dem Image geben kann... ARG ist das Geheimnis.
Wenn ich nun eine dynamische Subdomain haben will:
FROM httpd:2.4
ARG subdomain
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:$subdomain.example.com
Hier kann man dann auch auf ENV-Variablen zurück greifen und die weiter durch reichen. Was sehr praktisch ist, wenn man sich in einem Gitlab-CI Job befindet.
Nachdem ich meine wichtigsten Projekte in Docker-Container verfrachtet hatte und diese mit Traefik (1.7) als Reserve-Proxy seit Anfang des Jahres stabil laufen, war die Frage, was ich mit den ganzen anderen Domains mache, die nicht mehr oder noch nicht produktiv benutzt werden.
Ich hatte die Idee einen kleinen Docker-Container laufen zu lassen, auf den alle geparkten Domains zeigen und der nur eine kleine Info-Seite ausliefert. Weil das Projekt so schön übersichtlich ist und ich gerne schnell und einfach neue Domains hinzufügen will, ohne dann immer Container selbst stoppen und starten zu müssen, habe ich mich dazu entschieden hier mit Gitlab-CI ein automatisches Deployment zubauen. Mein Plan war es ein Dockerfile zu haben, das mir das Image baut und bei dem per Label auch die Domains schon angegeben sind, die der Container bedienen soll. Wenn ich einen neuen Tag setze soll dieser das passende Image bauen und auf meinem Server deployen. Ich brauche dann also nur noch eine Datei anpassen und der Rest läuft automatisch.
Dafür habe ich mir dann extra einen Gitlab-Account angelegt. Man hat da alles was man braucht und 2000 Minuten auf Shared-Runnern. Mehr als genug für meine Zwecke.
Ich habe also eine index.html und ein sehr einfaches Dockerfile (docker/Dockerfile):
FROM httpd:2.4
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:darknovels.de,www.darknovels.de
Das wird dann also in einen Job gebaut und in einem nach gelagerten auf dem Server deployed. Dafür braucht man einmal einen User auf dem Server und 2 Variablen in Gitlab für den Runner.
Dann erzeugt man sich für den User einen Key (ohne Passphrase):
su dockerupload
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
exit
Vielleicht muss man da noch die /etc/ssh/sshd_config editieren, damit die authorized_keys-Datei verwendet wird.
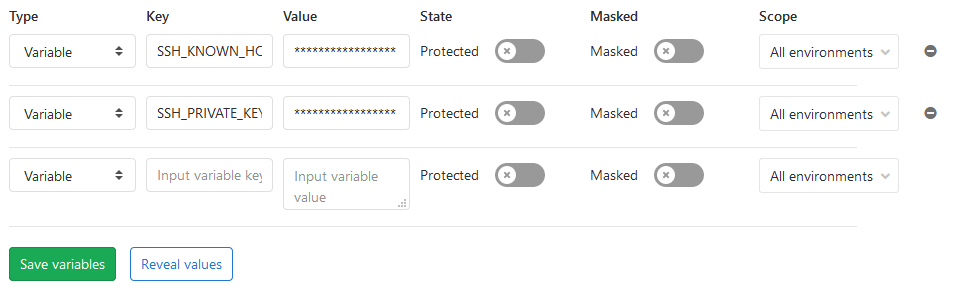
Den Private-Key einmal kopieren und in SSH_PRIVATE_KEY unter Settings - CI /DI - Variables speichern. Damit wir uns sicher vor Angriffen verbinden können müssen wir noch den Server zu den bekannten Hosts hinzufügen. Den Inhalt von known_hosts bekommt man durch:
ssh-keyscan myserver.com
Einfach den gesamten Output kopieren und in den Gitlab Variablen unter SSH_KNOWN_HOSTS speichern. Nun hat man alles was man braucht.
Der einfachste Weg einen Shopware Shop zuinstallieren war immer, die ZIP-Datei mit dem Webinstaller downzuloaden und diese in das gewünschte Verzeichnis zu entpacken. Dann die URL aufrufen und dem Installer folgen. Das ist für automatische Deployments nicht so toll und oft wurde dort einfach die Git-Version verwendet. Die hat den extremen Nachteil, dass diese unglaublich viele Dinge mitbringt, die in einer produktiven Umgebung nichts zu suchen haben. Buildscripte, Tests, etc bringen einen wirklich nur in der Dev-Umgebung was und sollten in der produktiven Umgebung nicht mit rumliegen, weil je mehr rumliegt, desto mehr Sicherheitslücken oder ungewollte Probleme könnten mitkommen.
Seit einiger Zeit kann man Shopware aber auch sehr einfach über den Composer installieren. Dabei wird eine eher moderne Verzeichnisstruktur angelegt und auch die Basis-Konfiguration kann einfach über Env-Variablen gesetzt werden, so dass ein automatisches Deployment für einen Server damit sehr einfach wird. Im Idealfall hat man die Datenbank schon sauber und fertig vorliegen. Dann erspart man sich fast den gesamten Installationsprozess und kann direkt loslegen.
Wenn man den Composer noch nicht installiert hat, muss man diesen kurz installieren:
<Directory /var/www/your_webshop>
AllowOverride All
Require all granted
</Directory>
RewriteEngine On
</Virtualhost>
Reload des Apache und schon kann es an sich losgehen. Wenn man sehen möchte wie die DATABASE_URL verarbeitet wird, kann man einen Blick in die etwas komplexer gewordene config.php werfen die man nun unter your_webshop/app/config/config.php findet.
Sollte man noch keine fertige Datenbank auf dem Server liegen haben, muss man die ./app/bin/install.sh ausführen. Gerade für mehrere automatische Deployments, würde ich aber die Datenbank einmal local auf meiner Workstation anlegen und mit Default-Werten befüllen. Diese kommt dann auf den Datebankserver und wird beim deployment, mit den spezifischen Daten wie den Shopdaten und Admin-Zugängen versehen.
Natürlich würden Updates auch über den Composer laufen, wobei sw:migration:migrate automatisch mit aufgerufen wird, um die Datenbank mit aktuell zu halten. Das Verhalten kann man über die Deaktivierung des entsprechenden Hooks in der composer.json verhindern (aber das macht an sich nur in Cluster-Umgebungen Sinn). Ein Update über das Webinstaller-Plugin würde Probleme bereiten und sollte, wenn man es dann ,z.B. weil man eine alte Installation umgezogen hat, installiert und aktiv hat mit ./bin/console sw:plugin:uninstall SwagUpdate entfernen.
Der wirkliche Vorteil liegt jetzt darin, dass man in die composer.json seine Git-Repositories von den Plugins mit eintragen kann und die Plugins direkt über den Composer installieren und updaten kann. Man muss also nicht diese erst vom Server downloaden + entpacken oder per Git clonen (wo dann wieder viel Overhead mit rüber kommen würde).
Irgendwie hört man momentan über all von DevOps. Ein DevOp ist wohl jemand der nicht nur entwickelt sondern auch den operativen Betrieb mit überwacht und diesen vielleicht auch komplett in Eigen-Regie betreut. Jedenfalls liest man solch eine Interpreation oft (ob diese jetzt die korrekte Interpreation ist sei mal dahin gestellt...).
Dieses Konzep ist jetzt nichts neues. In kleine Firmen ist sowas einfach normal (und läßt sich nicht ändern, weil man einfach zu wenig Personen hat und man alles eben übernhmen können muss) und in großen Firmen setzt sich sowas wohl auch immer mehr durch. Wenn man meine Arbeit betrachtet, könnte man auch mich als DevOp bezeichnen.
Dann wäre ich voll hip und modern. Aber am Ende will ich dass nicht unbedingt sein. Arbeitsteilung ist an sich gut und bringt viele Vorteile:
* Man kann sich auf eine Sache konzentrieren
* Wissen ist nicht in einer Person konzentriert (Wenn diese Person ausfällt bleibt Wissen vorhanden)
* Es ist alles transparenter, da mehrere Leute eingebunden sind
* Man kann sich nicht überall perfekt auskennen, deswegen sollte man nichts machen, wo man sich nur halb auskennt, wenn jemand da ist der sich damit besser auskennt
Warum aber gibt es diesen DevOps-Gedanken und warum soll damit alles so viel schneller und einfacher gehen?
* Weil es unglaublich schwer ist brauchbare Schnittstellen zwischen Teams und Abteilungen zu etablieren
* Weil es schneller geht etwas selber zu machen, als jemanden es zu erklären und einzuarbeiten
* Weil man nicht viel Doku schreiben muss, weil man es ja selber schon alles weiß
* Weil die Software so komplex ist, dass Deployment und Fehler-Analyse nur mit tiefgreifenden Kenntnissen der Software möglich ist
* Weil Menschen schlecht skalieren... weil Menschen bei der Zusammenarbeit viel Overhead erzeugen
Das Problem ist einmal die Schnittstellen innerhalb der Firma sowie deren Prozesse und einmal die Komplexität der Software. Gerade im Java-Bereich (JEE) ist es sehr ausgeprägt. Frameworks. Es gibt tausende von Frameworks. Für jeden Zweck und wenn man alles kombiniert und alles an Libs in den richtigen Versionen hat, hat man meistens schon so ein komplexes Konstrukt, dass es dann schon oft eine Tagesaufgabe ist den Workspace auf einem anderen Rechner einzurichten.
Einen JBoss/Wildfly zu installieren, zu starten und zu stoppen ist ja noch gut möglich. Datasources einrichten und Anpassungen vornehmen braucht schon etwas wissen. Wenn man dann für eine Anwendung noch eigene Module und Adapter braucht, wird es oft schon so speziel und spezifisch für die eine Anwendung, dass man ohne grundlegendes Wissen schnell Probleme bekommt.
JPA, Logging, Module + Versionen... alles exakt so einrichten, dass es so läuft wie auf dem Entwicklungsrechner.. viel Arbeit.
Bevor man nun anderen Personen alles erklärt und dann bei Problemen tausend nachfragen kommen, denkt man sich oft: "Mache ich es doch lieber selber!".
Also am Besten einfach alles genau so übernehmen wie es auf dem eigenen Entwicklungsrecher eingerichtet ist. Aber jede Änderung abgleichen ist natürlich auch doof. Deswegen wird all das möglichst mit in die Anwendung gezogen. Besonders die Konfiguration.
Ich erinnere mich noch an meine ersten Web-Projekte mit dem Tomcat. Damals noch mit Tomcat 4. DataSource hab ich in der server.xml eingetragen und mein Projekt als WAR deployed. Dann lief es. Es gab nur die DataSource mit einem bestimmten JNDI-Pfad. Wenn diese vorhanden war lief es. Die WAR jemanden zu geben, der sie dann deployte war kein Problem.
Aber dass war dann irgendwann nicht mehr so toll, weil für jede deployte Anwendung die server.xml anzupasen war nicht toll. Die Server wurden von Administratoren verwaltet, die aber sich nicht wirklich mit Tomcat auskannten und die zentralle server.xml anzupassen konnte natürlich dazu führen, dass andere Anwendungen dann nicht mehr liefen, wenn man was falsch machte.
Also wanderte viel die in context.xml. Mit JPA kam noch die persistence.xml dazu und weil man ja Unit-Tests machen wollte, hat man den Datenbank-Server dort direkt eingetragen und keine Datasources von der Server-Umgebung mehr verwendet. Das Logging ging auch gleich mit in die Anwendung und die Anwendung hat bestimmt in welche Datei gelogt wurde und was wie gelogt wird. Wenn man mal was anderes
Loggen wollte.. tja.. Anwendung neu bauen und neu deployen.
Wenn man jetzt noch mehr Framworks hat, die auch gerne Config-Daten haben wollen, nimmt man natürlich die auch gleich mit rein, weil der Entwickler es ja einmal alles eingestellt hat und man die Dateien dann nicht kopieren muss oder am Ende sogar noch mal komplet selbst anlegen muss.
Man bekommt also eine komplet vorkonfigurierte Anwendung die man dann deployed, die aber dann auch nur für diesen ganz speziellen Fall funktioniert. Datenbankserver ändern oder URLs zu externen System wechseln.. das geht nicht so einfach und die Anwendung muss komplett neu gebaut werden, wenn sowas mal passieren sollte.
Das macht natürlich alles für die Server-Admins simpler, da einen sauberen Server zu installieren einfach ist. Der Entwickler übernimmt dafür alles. Konfigurierbare Anwendungen sehe ich immer seltener. Was aber den Admins natürlich auch einen Teil der Kontrolle über die von denen betreuten Systeme nimmt und das gefällt natürlich auch nicht wirklich.
Was wären Lösungen? Schwer zu sagen. Meine Ideen wären:
* Anwendungen sollten möglichst "unkomplex" sein
* Die Anwendung sollte nicht vorkonfiguriert sein bzw die config sollte sich im Server überschreiben lassen
* Der Admin sollte sich mit der Umgebung auskennen und sollte wissen wie man die Anwendung und Umgebung konfiguriert
* Einfaches Deployment: Anwendung + Deployment-Descriptor (Config-Daten) in die Umgebung kopieren und Deployment starten
* Anwendungen sollten gut von ein ander isoliert sein
* Anwendungen sollten sich von Außen so gut anpassen und konfigurieren lassen, so das der Admin mit etwas Glück kleine Probleme beheben kann ohne das Code angefasst werden muss
* Die Umgebung aus AppServer/Servlet-Container mit einer Zusammenstellung der benötigten Frameworks sollten bei allen Projekten standardisiert werden. Also eine Person stellt immer aktuelle Zusammenstellungen zusammen, die dann von den Entwicklern verwendet werden und wenn möglich auch immer auf die aktuellen Versionen updaten.
Natürlich sollte sich jeder Entwickler grundlegend mit allem von AppServer bis zum Logging-Framework auskennen. Aber er sollte sich auf die Entwicklung konzentrieren und den normalen Betrieb der Anwendungen jemanden überlassen der die Serverumgebung sehr gut kennt und dort auch Performance- und andere Probleme lösen kann und die gesamte Infrastruktur verwaltet. Die Infrastruktur ändert sich laufend und die Anwendung sollte sich einfach und unkompliziert darauf anpassen lassen. Eine XML in einem Package in einer JAR im Lib-Verzeichnis einer WAR in einem Tomcat ist genau so schlimm, als wenn man die Daten direkt hart in eine Klasse kodiert hätte. Meiner Meinung nach müssen Config-Daten (ob aus einer Datei oder der Datenbank) zur Laufzeit änderbar sein.
Aber am Ende muss man sagen, dass ich auch schon oft genug gedacht habe "Hätte ich es doch einfach gleich selber gemacht...". Man braucht Vertrauen und einen Draht zu einander. Deswegen sollte man Teams vielleicht nicht horizontal aufbauen, sondern vertikal. Die Idee, dass einer alles macht, ist wohl auch weniger die grundlegende Idee hinter DevOps gewesen. Auch dass alles wieder in Software-Tools und so enden muss, sehe ich eher kritisch, weil man Komplexität oft nicht durch mehr Komplexität lösen kann.
Am Ende darf es eben nur ein DevOp-Team geben, wenn man das Konzept umsetzen möchte. Ein DevOp in einer Person ist unsinnig bzw bedingt sich selbst. Im Team müssen die Schnittstellen und die Rücksichtnahme zwischen den Fachbereichen geschafen und gelebt werden. Man sollte also Kompetenzen nicht versuchen zusammen zu fassen, sondern diese nur dichter zu einander bringen.
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: