Subscriber bei Shopware-Plugins sind immer so ein Problem. Sie nehmen Daten manipulieren diese und reichen sie an den nächsten Subscriber weiter. Wenn ein Subscriber in einen Fehler läuft und z.B. leere Daten in die Arguments zurück schreibt, ist am Ende alles kaputt und die Daten sind verloren gegangen. Das ist mir jetzt einmal passiert und deswegen, bin ich darauf umgeschrieben, dass Subscriber nur noch auf einer Kopie arbeiten
dürfen.
Sollte nun etwas schief gehen und die Daten verloren gehen, werden einfach die Ursprungsdaten weiter verwendet. Wenn nun zusätzliche Daten nicht dazu dekoriert werden, ist es zwar doof und man muss in das Log-File gucken, ob Fehler auftraten, aber der Ablauf funktioniert weiter und es kommen immer hin die Grunddaten weiter dort an wo sie hin sollen.
Gerade bei Exports oder Imports mit kritischen und unkritischen Daten zusammen, ist es immer besser wenigstens die kritischen Daten sicher zu haben als gar nichts zu haben. Unkritische Daten kann man meistens dann sogar per Hand nachpflegen.
Ich habe mich jetzt die letzten 2-3 Monate doch relativ ausführlich mit Shopware beschäftigt. Das erste Projekt das live ging war das Creditfair Fair-Vereinsprogramm. Dafür mussten 2 Plugins geschrieben und einige Theme-Anpassungen vorgenommen werden.
Die Plugin-API mit den Events ist wirklich einfach zu erlernen. Einzig die Suche nach dem passenden Event kann immer etwas länger dauern, wobei am Ende weniger die Frage ist, ob es das richtige Event ist, sondern ob es das beste Event ist. Events für jeden Fall gibt es mehr als genug, wobei die Unterschiede wirklich oft in Feinheiten zu suchen sind.
Nebenbei habe ich als Test ein kleines Plugin geschrieben, das das Kunden-Objekt (wenn denn ein Kunde eingeloggt) ist auch beim Versenden von Forms im Template verfügbar macht. Forms verwenden eine eigene kleine und sehr einfache Template Engine. Für die Erweiterung um den Kunden kommt aber dann Smarty3 zum Einsatz. Damit kann man bei Anfragen über Forms, die nur angemeldeten Kunden zur Verfügung stehen, die Kundendaten direkt zur Email hinzufügen, ohne dass der Kunde es selber tun muss.
Insgesamt macht es viel Spass mit Shopware zu entwickeln.. nur.. nur eine Sache gibt.. die bereitet mir noch Kopfzerbrechen.
STAGING
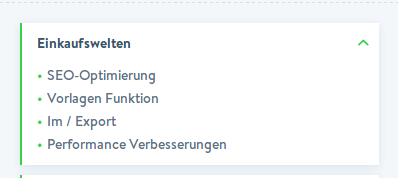
Mit der 5.3 kann man wenigstens Einkaufwelten exportieren und wieder importieren. Das ist schon mal wirklich eine große Hilfe, da so Designer auf dem lokalen System arbeiten und testen können und man erst dann nach der Freigabe die Einkaufwelten auf das produktive System verschieben kann.
Themes kann auch relativ einfach kopieren. Plugins aus dem Community-Store sollte man so oder so nicht durch ein Staging laufen lassen, sondern auf dem produktiven Server neu installieren und konfigurieren.
Content-Seiten sind der Punkt, wo ich noch am Überlegen bin wie man damit umgehen soll. Hier fehlt eine vergleichbare Import/Export Funktion wie bei den Einkaufwelten.
Ein anderes Thema betrifft Shopware aber auch fast alle anderen Shop-Systeme. Das Problem beginnt damit Produkte, Hersteller, etc in das Shop-System zu bekommen. Denn wenn man keinen winzigen Shop mit 10-50 Artikeln hat, wird man sicher die Produkte aus einem Waren-Wirtschafts-System beziehen wollen. Die REST-API von Shopware ist toll und man kommt schnell zu Ergebnissen. Der CSV-Import ist auch nicht schlecht. Aber das Problem ist, dass man dann immer eine Lösung für Shopware baut. Bei anderen Shops eben für das jeweilige System.
Es gibt wohl kaum Shop-Systeme (oder ich konnte sie nicht finden), die Standard-Formate als Core-Feature lesen oder schreiben können.
Bei der Arbeit dürfte ich nun mit CSV, XML und IDocs aus SAP kämpfen. IDocs sind für den Datenaustausch wirklich nicht toll. Jedenfalls nicht, wenn man die SAP-Welt verlässt. In dem Artikel Warum Sie beim Datenaustausch im E-Commerce auf Standardformate setzen sollten von Daniel Peters trifft es sehr gut gut. Ich stimme da zu 100% zu und er trifft wirklich den Punkt, den ich schon seit Jahren nicht verstehe. Wenn ich ein neues System entwickle, dass mit anderen Systemen kommunizieren und Daten austauschen muss. Warum baue ich mir dann immer wieder ein eigenes Format und nehme mir nicht von Anfang an ein Standard-Format. Damit habe ich auch schon mal eine Art Blaupause, wie man mit dieser Art von Daten umgehen kann und sollte mal ein System ausgewechselt werden, muss ich hoffentlich nicht wieder ein neues proprietäres Format in eine Schnittstelle für mein System umwandeln.
Ich hatte mir ein kleines Plugin geschrieben, dass Bestellungen direkt nach dem Speichern als JSON auf dem Server abgelegt hat. Es war zuerst zur Kontrolle und zum Debuggen auf dem Live-Server da. Es hat nicht lange gedauert und ich hatte auch einen XML-Export und 2 Stunden später auch einen rudimentären [url=]OpenTrans[/url] 1.0 export. Auch wenn der Standard sicher noch nicht zu 100% korrekt umgesetzt ist, habe ich doch schon mal ein Export-Format für Bestellungen, das alles enthält was man braucht, strukturiert ist und auch einfach wieder gelesen werden kann.
Ich werde auf jeden Fall an dem Plugin noch mal weiter rumbauen und vielleicht nochmal OpenTrans 2.1 implementieren.
Ich glaube auch das man einfacher eine OpenTrans zu IDoc Lösung findet, ohne selbst was machen zu müssen, als eine Shopware-internes-Format zu IDoc.
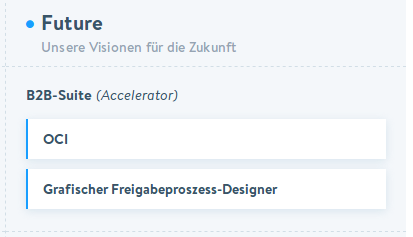
Auch der Import der Produkte... warum kann ich nicht einfach OCI oder BMEcat verwenden, um meinen Shop mit Daten zu befüllen. WWS und andere ERP-Systeme können ja diese Format ausgeben. Die Formate, gerade OCI, sind ja auch sehr verbreitet. Warum kann der Shop diese also nicht nativ lesen und benötigt Zusatzsoftware oder Plugins?
Auf der Roadmap von Shopware-Enterprise steht bei B2B jetzt OCI in der "Unsere Visionen für die Zukunft". Richtiges Punchout muss ja nicht mal sein.
Aber die OCI-XML Daten importieren zu können wäre schon einfach toll und würde an vielen Stellen sehr viel Arbeit und Geld sparen.
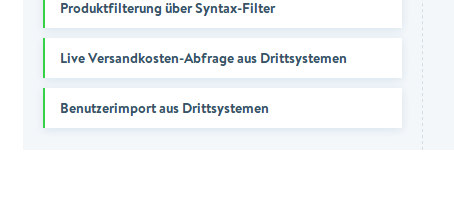
Das wohl gerade an einem Import für Kunden aus Drittsystemen gearbeitet wird kommt wohl für mich auch zu spät, aber ist schon mal eine tolle Sache.
Momentan überlege ich einen kleines Plugin zu schreiben, dass BMEcat versteht. Nichts all umfassendes mit User-Data-Extensions und so. Ein einfaches kleines, dass nur dafür sorgt, dass Systeme die BMEcat ausgeben können, grundlegend den Shop mit Produkten befüllen können. Wenn ich dann mal wieder Daten aus einem System in Shopware importieren soll, würde ich einfach die Daten auf BMEcat umbiegen können (mit einer Middleware oder XSLT oder so) und müsste an Shopware nichts mehr ändern. Shopware hätte dann eine stabile Schnittstelle, die nicht nur für mich sondern allgemein genutzt werden kann und sogar ein sehr gut dokumentiertes Format nutzt.
Sich der Welt mit Standard-Formaten als Core-Feature zu öffnen, würde vielen Shop sehr gut tun. ... aber wohl auch einen Markt der sich nur auf das verschieben von Daten zwischen Systemen spezialisiert hat, empfindlich treffen können. Für den normalen Entwickler und seinen Shop wäre es aber wirklich ein großer Vorteil.
Nachdem ich im letzten halben Jahr mit Neo4j und nun auch mit Elasticsearch zu tun hatte, bin ich was NoSQL-Datenbanken angeht etwas zwiegespalten. Graphen-Datenbanken sind toll um Beziehungen zwischen Entitäten abzubilden. Dokumenten-orientierte Datenbanken wie Elasticsearch ideal um unstrukturierte Daten zu speichern und neben der eigentlichen Abfrage auch z.B. Durchschnittswerte oder Übersichten von der Abdeckung von bestimmten Attributen/Feldern gleich mit abzufragen.
Die Abfragen sind schnell. Aber.. auch sind die Queries komplexer (Neo4j) bis sehr viel komplexer (Elasticsearch). Der Vorteil der NoSQL Datenbanken ist, dass man schon fertige Objekte zurück bekommt und man nicht auf Tabellenstrukturen beschränkt ist. So kann man also Listen mit Objekten die zu einer Entität gehören gleich mit abfragen und erspart sich ein zweites Query und zusätzliches Mapping.
Aber sind die NoSQL Datenbanken wirklich so viel schneller, wie man immer hört? Dafür muss man verschiedene Dinge bedenken. Zuerst ob die Datenbank die primäre Datenquelle ist oder nur zusätzlich zu einem RDBMS verwendet wird. Ich hatte bis jetzt nur mit zusätzlichen Datenbanken zu tun. Deren Daten wurden durch Cronjobs aus dem RDBMS gelesen, aufbereitet und dann in die NoSQL-Datenbank geschrieben.
Entweder per CSV-Import (Neo4J) oder direkt über die REST-API (Elasticsearch). Die gleichen Abfragen waren in der MySQL-Datenbank langsamer. Nicht viel langsamer. Aber es war doch spürbar und lagen bei der Neo4J bei so 30%-40%.
Wenn man nun aber einberechnet wie viel Aufwand der Import darstellt, der bei beiden Anwendungsfällen zwischen 1,5-5min lag, sieht es schon sehr viel anders aus. Die Importscripte reduzierten die Datenmenge natürlich sehr extrem und schrieben nur die nötigsten Daten in die NoSQL-Datenbanken. Bei der Neo4J waren es wirklich nur Ids und Relationen. Die Elasticsearch hatte alle elementaren Felder und auch Unterobjekte, die bei SQL über Joins geladen werden würden. Auf dieser reduzierten und stark vereinfachten Datenbasis waren die Abfragen sehr schnell.
Wenn man mit ein paar SQL-Statements die selben Daten in der MySQL in dem selben Umfang in eigene Tabellen schreibt, ist die MySQL Datenbank meiner Erfahrung nach genau so schnell. Im Vergleich von MySQL und Neo4J muss man sagen, dass für die Abfragen plötzlich viel mehr Daten zur Verfügung stand und diese auf genutzt wurden. Außerdem wurden doppelt so viele Queries verwendet. Am Ende war die MySQL-Lösung langsamer aber auch sehr viel komplexer und in dem Sinne besser.
Ich für meinen Teil sehe in den NoSQL-Datenbank nur einen Vorteil, wenn man die Vorteile derer auch nutzt. Wenn ich keine Graphen brauche, brauche ich auch keine Neo4J-Datenbank. Habe ich nur Entitäten und DTOs die ich schnell speichern und laden möchte, brauche ich keine Elasticsearch. Elasticsearch ist komplex und kann ein paar wirklich interessante Dinge durch deren Aggregations. Wenn ich haufenweise unterschiedliche Daten aus vielen verschiedenen Quellen zusammen fahren möchte bin ich mit Elasticsearch gut beraten. Aber wenn ich nur Geschwindigkeit haben möchte muss ich nur die Datenbasis verringern und vereinfachen. Neo4J ist auch extrem Speicher hungrig. Was bringt es mir wenn ich 96GB an RAM brauche um das zu machen was ich mit 32GB und einer MySQL oder einer Oracle-DB genau so schnell hinbekomme. Wenn ich dann sehr viel RAM habe und ganze Datenbanken im Speicher halten kann, habe ich die selbe Geschwindigkeit und bin mit der größeren Datenbasis sehr viel flexibler. Außerdem ist alles schneller und sicherer was ich direkt innerhalb der Datenbank machen kann. Ein Import von der MySQL in die Neo4J brauchte viel darum herum um sicher zu sein. In einer Oracle würde alles sowie so in einer Transaction laufen, die auch nicht noch den Server der das Script startet belastet.
Wer also in seinem RDBMS Performanceprobleme hat, soll sie auch dort lösen und nicht glauben, dass ein weiteres System anzubinden (und synchron zu halten) dieses Probleme lösen würde.
Wer sich mit CSV-Importen in Neo4j 3.0 versucht wird schnell merken, dass die angegebene File-URL sich irgendwie immer auf das Neo4j Verzeichnis bezieht auch wenn man sich auf das Root Verzeichnis bezieht. Der Fehler liegt nicht an der File-URL, sondern an einer Einstellung in Neo4j, wo als default Verzeichnis das eigene import-Verzeichnis gewählt ist und die File-URL sich nur auf Dateien innerhalb dieses Verzeichnisses bezieht.
Man kann einfach in der conf/neo4j.conf das import Verzeichnis von import auf / (Linux) ändern und es verhält sich wieder wie in der 2.x Version.
Oft werden NoSQL für sehr spezielle Fälle eingesetzt. Die normale Datenhaltung bleibt weiter hin den SQL-Datenbanken überlassen. Also müssen regelmäßig die Daten aus dem SQL-Bestand in die NoSQL Datenbank kopiert werden. Das dauert oft und viele aufbereitungen der Daten wird schon hier erledigt. die NoSQL Varianten sind deswegen auch oft schneller, weil man eine Teil der Arbeit in den Import-Jobs erledigt, die sonst bei jedem Query als Overhead entstehen. Natürlich haben die NoSQL auch ohne das ihre Vorteile, aber man sollte immer im Auge behalten, ob die Performance von der Engine kommt oder auch von der Optimierung der Daten, weil die Optimierungen der Daten könnte man auch in die SQL-Struktur zurück fließen lassen und diese in die Richtung hin verbessern.
So ein Import dauert... wenn man in der Nacht ein Zeitfenster von einer Stunde hat, ist alles kein Problem. Will man aber auch in kurzen Abständen importieren, muss der Import schnell laufen. Auch wenn man als Entwickler öfters mal den Import braucht, ist es wichtig möglichst viel Performance zu haben.
Hier geht es darum wie man möglichst schnell und einfach Daten aus einer MySQL Datenbank in eine Neo4j Graphen-Datenbank importieren kann, ohne viel Overhead zu erzeugen. Ich verwende hier PHP, aber da an sich keine Logik in PHP implementiert werden wird, kann man ganz leicht auf jeden andere Sprache, wie Java, JavaScript mit node.js und so übertragen. Es werden keine ORMs verwendet (die extrem viel Overhead erzeugen und viel Performance kosten) sondern nur SQL und Cypher.
Wie man einfach sich eine oder mehrere Neo4J-Instanzen anlegt (unter Linux) kann man hier sehr gut sehen:
Wir verwenden bei Neo4j den Import über eine CSV-Datei. Wir werden also nicht jeden Datensatz einzeln Lesen und Schreiben, sondern immer sehr viele auf einmal. Ob man alles in einer Transaktion laufen lässt und erst am Ende commited hängt etwas von der Datenmenge ab. Bis 200.000 Nodes und Relations ist alles kein Problem.. bei Millionen von Datensätzen sollte man aber nochmal drüber nachdenken.
PERIODIC COMMIT ist da eine super Lösung, um alles automatisch laufen zu lassen und sich nicht selbst darum kümmern zu müssen, wann commited wird. Alle 1000 bis 10_000 Datensätze ein Commit sollte gut sein, wobei ich eher zu 10_000 raten würde, weil 1000 doch noch sehr viele Commits sind und so mit der Overhead noch relativ groß ist.
Unsere Beispiel Datenbank sieht so aus:
CREATE TABLE USERS(
USER_ID INT(11) UNSGINED NOT NULL,
USER_NAME VARCHAR(255) NOT NULL,
PRIMARY KEY (USER_ID)
);
CREATE TABLE MESSAGES(
MESSAGE_ID INT(11) UNSIGNED NOT NULL AUTO_INCREMENT,
MESSAGE_TITLE VARCHAR(255) NOT NULL,
FROM_ID INT(11) UNSIGNED NOT NULL,
TO_ID INT(11) UNSIGNED NOT NULL,
CC_ID INT(11) UNSIGNED NOT NULL,
PRIMARY KEY (MESSAGE_ID)
);
Wir legen uns 50.000 User an dann noch 100.000 Messages mit jeweils einen FROM, einem TO und einem CC (hier hätte man über eine Link-Table sollen, aber das hier ist nur ein kleines Beispiel, wo das so reicht). Das sollten erst einmal genug Daten sein. (Offtopic: da ich das gerade neben bei auch in PHP schreibe.. warum kann ich für eine 100000 nicht wie in Java 100_000 schreiben?)
Die erste Schwierigkeit ist es die Daten schnell zu exportieren. Ziel ist eine CSV. Wir könnten entweder über PHP die Daten lesen und in eine Datei schreiben oder aber einfach die OUTFILE-Funktion von MySQL nutzen, um die Datenbank diese Arbeit erledigen zu lassen. Wir werden es so machen und erstellen für jede Art von Nodes und Relations eine eigene CSV. Weil wir Header haben wollen fügen wir diese mit UNION einmal oben hinzu
$sql="
SELECT 'user_id', 'user_name'
UNION
SELECT USER_ID,USERNAME
FROM USERS
INTO OUTFILE ".$exchangeFolder."/users.csv
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'
";
Damit schreibt MySQL das Ergebnis des Queries in die angegebene Datei. Falls ein Fehler auftritt, muss man gucken, ob der Benutzer unter dem die MySQL-DB läuft in das Verzeichnis schreiben darf und ob nicht eine Anwendung wie apparmor unter Linux nicht den Zugriff blockiert. Es darf keine Datei mit diesen Namen schon vorhanden sein, sonst liefert MySQL auch nur einen Fehler zurück. Wir müssen
die Dateien also vorher löschen und dass machen wir einfach über PHP. Also muss auch der Benutzer unter dem die PHP-Anwendung läuft entsprechende Rechte haben.
Man kann das gut einmal direkt mit phpmyadmin oder einem entsprechenden Programm wie der MySQL Workbench testen. Wenn die Datei erzeugt und befüllt wird ist alles richtig eingestellt.
Mit dem Erstellen der CSV-Datei ist schon mal die Hälfte geschafft. Damit der Import auch schnell geht brauchen wir einen Index für unsere Nodes. Man kann einen Index schon anlegen, wenn noch gar kein Node des Types erstellt wurde. Zum Importieren der User benutzen wir folgendes Cypher-Statement:
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/messages.csv" AS row
MERGE (m:message{mid:row.msg_id,title:row.msg_title});";
Der Pfad zur Datei wird als File-URL angegeben. Hier merkt man auch Neo4J seine Java-Basis an. Wenn man mal in eine Temp-Verzeichnis schaut sieht man dort auch Spuren von Jetty.
Am Ende wird der Importer nur eine Reihe von SQL und Cypher Statements ausführen. Wir benötigen um komfortabel zu arbeiten 3 Hilfsmethoden. Dass alles in richtige Klassen zu verpacken wäre natürlich besser, aber es reicht zum erklären erst einmal ein Funktionsbasierter Ansatz.
Da MySQL keine Dateien überschreiben will, brauchen wir eine Funktion zum Aufräumen des Verzeichnisses über das die CSV-Dateien ausgetauscht werden. Wir räumen einmal davor und einmal danach auf. Dann ist es kein Problem den Importer beim Testen mal mittendrin zu stoppen oder wenn er mal doch mit einem Fehler abbricht.
function cleanFolder($folder){
$files=scandir($folder);
foreach($files as $file){
if(preg_match("/\.csv$/i", $file)){
unlink($folder."/".$file);
}
}
}
Für Neo4J bauen wir uns eine eigen kleine Funktion.
use Everyman\Neo4j\Client;
use Everyman\Neo4j\Cypher\Query;
$client = new Everyman\Neo4j\Client();
$client->getTransport()->setAuth("neo4j","blubb");
function executeCypher($query){
global $client;
$query=new Query($client, $query);
$query->getResultSet();
}
Der Rest ist nun sehr einfach und linear. Ich glaube ich muss da nicht viel erklären und jeder Erkennt sehr schnell wie alles abläuft. Interessant ist wohl das Cypher-Statement für die Receive-Relations, da neben der Relation diese auch mit einem Attribute versehen wird im SET Bereich.
//clear for export (if a previous import failed)
cleanFolder($exchangeFolder);
//export nodes
echo "create users.csv\n";
$sql=" SELECT 'user_id', 'user_name' UNION
SELECT USER_ID,USER_NAME
FROM USERS
INTO OUTFILE '".$exchangeFolder."/users.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
echo "create messages.csv\n";
$sql=" SELECT 'msg_id', 'msg_title' UNION
SELECT MESSAGE_ID, MESSAGE_TITLE
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/messages.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
//export relations
echo "create relations_etc.csv\n";
$sql=" SELECT 'user_id', 'msg_id', 'type' UNION
SELECT TO_ID, MESSAGE_ID, 'TO'
FROM MESSAGES
UNION
SELECT CC_ID, MESSAGE_ID, 'CC'
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/relations_etc.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
echo "create relations_from.csv\n";
$sql=" SELECT 'user_id', 'msg_id', 'type' UNION
SELECT FROM_ID, MESSAGE_ID, 'FROM'
FROM MESSAGES
INTO OUTFILE '".$exchangeFolder."/relations_from.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY '\n'";
$db->execute($sql);
//create indexes for fast import
echo "create index's in neo4j\n";
$cyp="CREATE INDEX ON :user(uid);";
executeCypher($cyp);
$cyp="CREATE INDEX ON :message(mid);";
executeCypher($cyp);
//import nodes
echo "import users.csv\n";
$cyp="USING PERIODIC COMMIT 10000\n
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/users.csv" AS row\n
MERGE (u:user{uid:row.user_id,name:row.user_name});";
executeCypher($cyp);
echo "import messages.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/messages.csv" AS row
MERGE (m:message{mid:row.msg_id,title:row.msg_title});";
executeCypher($cyp);
//import relations
echo "import relations_from.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/relations_from.csv" AS row
MATCH(u:user{uid:row.user_id})
MATCH(m:message{mid:row.msg_id})
MERGE (u)-[r:send]->(m);";
executeCypher($cyp);
echo "import relations_etc.csv\n";
$cyp="USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM "file:///".$exchangeFolder."/relations_etc.csv" AS row
MATCH(u:user{uid:row.user_id})
MATCH(m:message{mid:row.msg_id})
MERGE (m)-[r:receive]->(u)
SET r.type=row.type;";
executeCypher($cyp);
//clear after import
cleanFolder($exchangeFolder);
Hier sieht man wie der Importer die 50.000 User, 100.000 Messages und insgesamt 300.000 Relations von einer MySQL in die Neo4J Instanz importiert.
Die Festplatte ist nur über SATA-2 Angeschlossen und nicht besonders schnell. Eine SSD, wie für Neo4J empfohlen, würde alles sehr beschleunigen.
Zum Löschen aller Daten aus der Neo4J kann man diese Statement verwenden:
MATCH (n)
DETACH DELETE n
Blog-entries by search-pattern/Tags:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von  Blog: Blog-entries by search-pattern/Tags:
Blog: Blog-entries by search-pattern/Tags: