 bezahlt von
bezahlt von Git State Konzept
Am Freitag hat mir mein Kollege 2 Links zu Blogposts geschickt, die sich mit der Frage beschäftigen ob Git-Flow in der heutigen Zeit überhaupt noch funktioniert oder ob Git-Flow veraltet ist. Der 1. Blogpost zeigt erstmal nur Probleme auf und enthält keine Lösungen. Es passiert zu leicht das Release-Branches zu lange leben und dann darin selbst Entwicklung geschieht. Es dauert relativ lange bis eine Änderung durch die verschiedenen Branches im Master ankommen und am Schlimmsten ist noch, dass bei parallelen Entwicklungen ein nicht releaster Branch einen anderen aktuelleren, der einfach schneller war, blockiert.
Ja. Das ist jetzt nicht neu. Über diese Probleme habe ich 2009 schon im dem damaligen ERP-Team diskutiert (mein Gott waren wir damals schon modern...). Die Lösung hier ist einfach dass man harte Feature- und Code-Freezes braucht. Auch darf die Fachabteilung nicht erst im Release-Branch das erste Mal die neuen Features sehen. Ich habe es so erlebt. Dann kamen die neuen Anforderungen, Änderungen der gerade erst implementierten Features. Das soll aber so sein. Wenn das so ist braucht man aber auch noch das. Das ist falsch und muss so funktionieren... Alles Dinge die schon viel früher hätten klar sein müssen und erst dann hätte es zu einem Release-Branch kommen dürfen. Der Stand eines Feature-Branchs muss genau so auf einem System für Test und Abnahmen deploybar sein wie ein Release-Branch. Anders gesagt jeder Stand muss einfach immer präsentierbar sein!
Der 2. Blogpost brachte jetzt auch nicht wirklich neue Erkenntnisse, was am Ende der Author auch selbst schreibt.
Ich halte die Darstellung von Branches in parallelen Slots oder Lanes, die in dem Sinne ein Rennen um die Aktualität austragen für vollkommen falsch. Es darf auch nicht den develop-Branch oder den einen Release-Branch geben, der auch dann immer deckungsgleich mit dem Stand des Deployments auf einem System ist. In Zeiten von Docker und Reverse-Proxies zusammen mit Wildcard-Subdomains sind feste Systeme sowie so überholt. Jeder Branch kann ein System haben, auf dem Test, Abnahmen und Dokumentation stattfinden kann.
Das gilt auch für Tags. Branches sind variabel und ändern sich immer wieder. Tags sind statisch und damit perfekt für Zwecke, wo man kontrolliert bestimmte Stände deployen möchte. Tags persitieren einen bestimmten State/Zustand des gesamten Git-Repositories. Branches bilden einen State/Zustand aus der Sicht eines bestimmten Entwicklers oder eines bestimmten Features ab.
Deswegen halte ich feste Branches wie mit festen Aufgaben für komplett falsch. Ein Feature = ein Branch und am Ende steht ein Tag, der den gewünschten State/Zustand persitiert.
Ein einfacher Feature Branch:
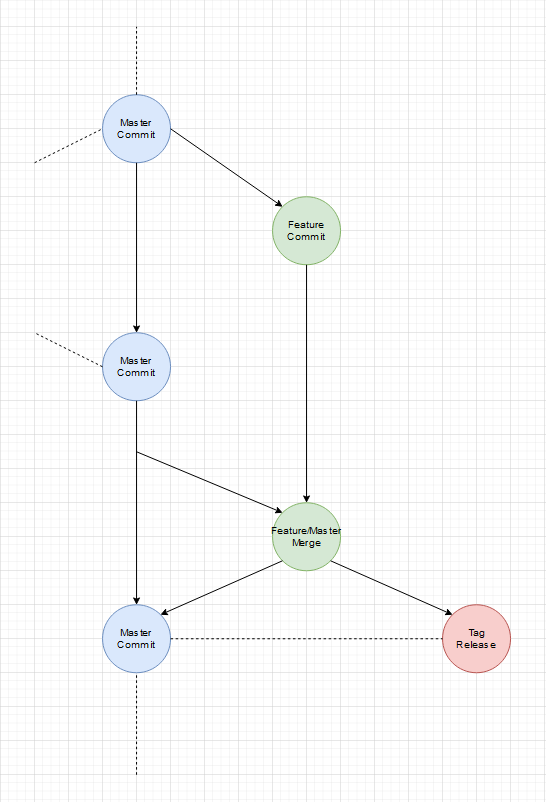
Ja es gibt noch einen Master-Branch, der aber in dem Sinne nur ein 2D Abbild des wilden mehr dimensionallen Feature Raum ist. Wenn wir jeden Feature-Branch als Vektor der auf das einzelne Feature/Tag als Ziel zeigt versteht, ist der Master einfach die Projektion aller Vektoren auf eine Fläche. Diese vereinfachte Projektion hilft Feature-Branches vor dem Release auf den aktuellen Stand (was andere Features und Fixes angeht) zu bringen.
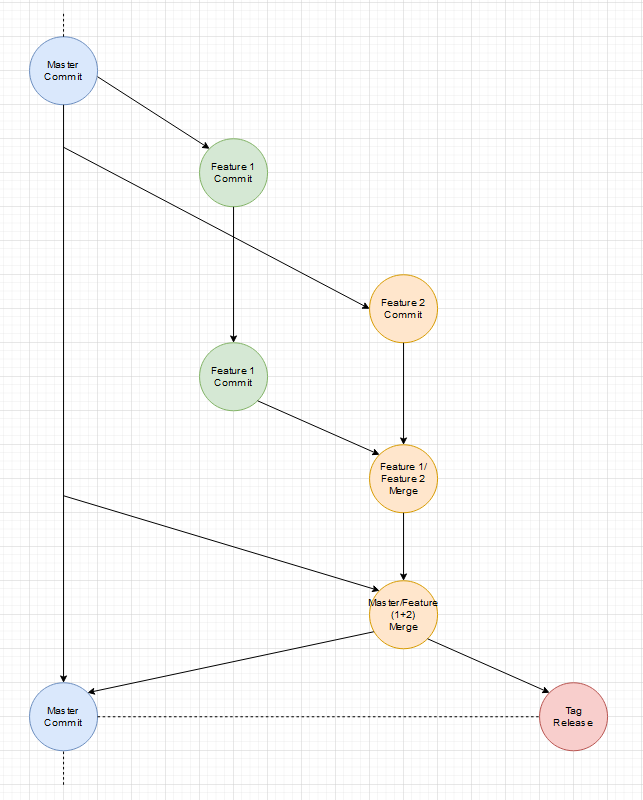
Es gibt auch immer mal Abstimmungsprobleme bei Features, die auf einander aufbauen. Interfaces haben minimale Abweichungen oder ein kleiner Satz in der Dokumentation wurde falsch verstanden. Was also wenn ein Feature doch noch eine kleine Änderung braucht, weil Entwicklungen parallel liefen?
Beides wird gleichzeitig fertig (ein extra Release-Branch wäre möglich):
Das Basis-Feature geht vorher live:
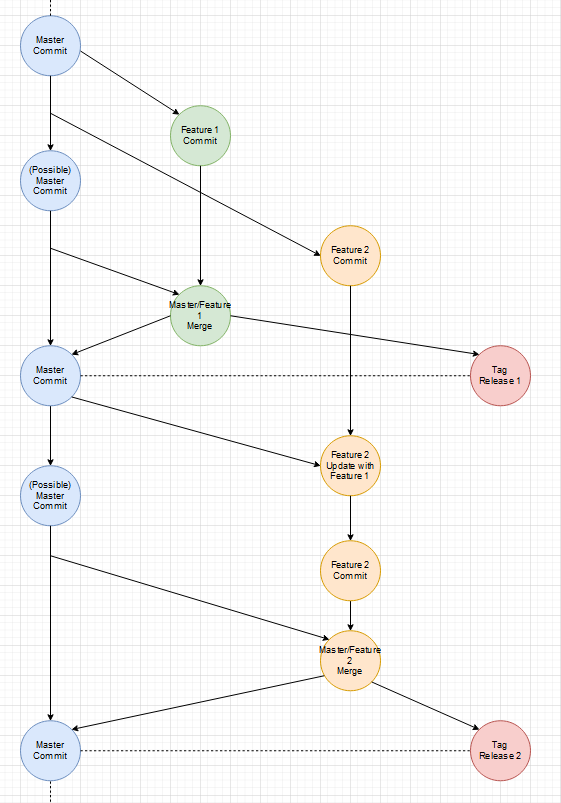
Das bessere und flexiblere Vorgehen
Gibt es einen Unterschied zwischen Fixes und Features? Nein. Beides sind Improvements des aktuellen States/Zustands. Wenn einem in einem Feature-Branch ein allgemeines Problem auffällt, fixt man das Problem und merged den Master mit der neuen Version erneut in den Feature-Branch.
Zwischenzeitlicher Fix:
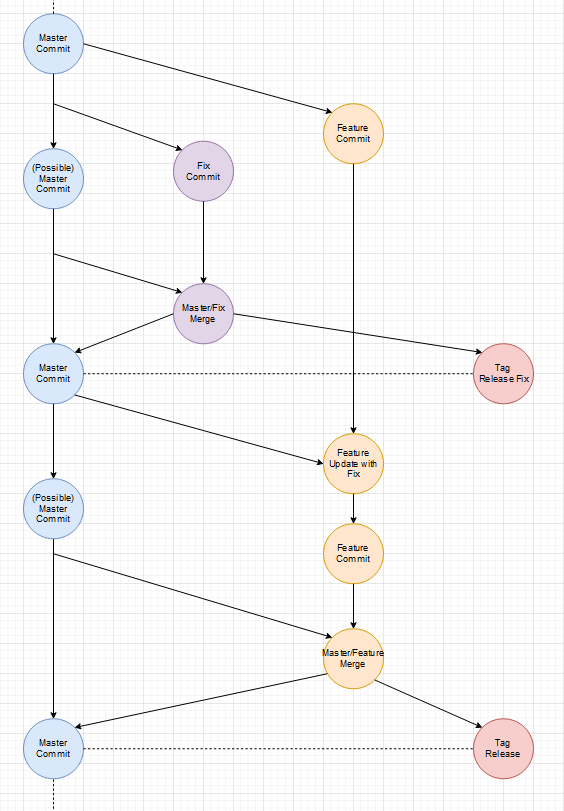
Es ist an sich kein Unterschied zwischen einem Fix und einen weiteren Feature-Branch, außer dass der Fix-Branch sehr viel kurzlebiger ist und wohl weniger Commits enthält.
Der Master ist immer stable, weil nur Release-Tags darauf abgebildet sind.
Dieses Herangehen macht es sehr einfach jeden State/Zustand auf System abzubilden. Jeder Branch ist unter seinem Namen zu finden und Tags werden nach Typ auf Systeme gemappt.
Tag auf System:
- release-XXX auf das produktive System
- staging auf das Staging-System (1:1 Namenabbildung)
- demo1-n auch 1:1 per Namen abbilden
Bei staging muss man den Tag löschen und neu anlegen, so kann jeder Zustand auf dem Staging-System deployt werden oder besser gesagt, wird ein Deployment durchgeführt das dann unter der Staging-Domain erreichbar ist. Hier gibt es eine tolle Anleitung wie man solche Systeme mit Traefik oder Kubernetes ganz einfach bauen kann. Ich werde das aber vielleicht auch noch mal genauer beschreiben, wie ich es für gut halte.
Denn Branches halte ich persönlich es nicht für wert wo anders als lokal in einem Docker-Container zu laufen. Da kann ich um es der Fachabteilung lieber schnell einen Tag erstellen und diesen nach dem Input der Abteilung auch wieder unter selben Namen neu anlegen oder unter einen neuen wenn zwei mögliche Umsetzungen verglichen werden sollen (macht das mal mit Git-Flow!).
Edit: Ich habe die per Hand gezeichneten Diagramme durch vollständigere Diagramme, die per Software erstellt wurden, ausgetauscht.
Ja. Das ist jetzt nicht neu. Über diese Probleme habe ich 2009 schon im dem damaligen ERP-Team diskutiert (mein Gott waren wir damals schon modern...). Die Lösung hier ist einfach dass man harte Feature- und Code-Freezes braucht. Auch darf die Fachabteilung nicht erst im Release-Branch das erste Mal die neuen Features sehen. Ich habe es so erlebt. Dann kamen die neuen Anforderungen, Änderungen der gerade erst implementierten Features. Das soll aber so sein. Wenn das so ist braucht man aber auch noch das. Das ist falsch und muss so funktionieren... Alles Dinge die schon viel früher hätten klar sein müssen und erst dann hätte es zu einem Release-Branch kommen dürfen. Der Stand eines Feature-Branchs muss genau so auf einem System für Test und Abnahmen deploybar sein wie ein Release-Branch. Anders gesagt jeder Stand muss einfach immer präsentierbar sein!
Der 2. Blogpost brachte jetzt auch nicht wirklich neue Erkenntnisse, was am Ende der Author auch selbst schreibt.
Ich halte die Darstellung von Branches in parallelen Slots oder Lanes, die in dem Sinne ein Rennen um die Aktualität austragen für vollkommen falsch. Es darf auch nicht den develop-Branch oder den einen Release-Branch geben, der auch dann immer deckungsgleich mit dem Stand des Deployments auf einem System ist. In Zeiten von Docker und Reverse-Proxies zusammen mit Wildcard-Subdomains sind feste Systeme sowie so überholt. Jeder Branch kann ein System haben, auf dem Test, Abnahmen und Dokumentation stattfinden kann.
Das gilt auch für Tags. Branches sind variabel und ändern sich immer wieder. Tags sind statisch und damit perfekt für Zwecke, wo man kontrolliert bestimmte Stände deployen möchte. Tags persitieren einen bestimmten State/Zustand des gesamten Git-Repositories. Branches bilden einen State/Zustand aus der Sicht eines bestimmten Entwicklers oder eines bestimmten Features ab.
Deswegen halte ich feste Branches wie mit festen Aufgaben für komplett falsch. Ein Feature = ein Branch und am Ende steht ein Tag, der den gewünschten State/Zustand persitiert.
Ein einfacher Feature Branch:
Ja es gibt noch einen Master-Branch, der aber in dem Sinne nur ein 2D Abbild des wilden mehr dimensionallen Feature Raum ist. Wenn wir jeden Feature-Branch als Vektor der auf das einzelne Feature/Tag als Ziel zeigt versteht, ist der Master einfach die Projektion aller Vektoren auf eine Fläche. Diese vereinfachte Projektion hilft Feature-Branches vor dem Release auf den aktuellen Stand (was andere Features und Fixes angeht) zu bringen.
Es gibt auch immer mal Abstimmungsprobleme bei Features, die auf einander aufbauen. Interfaces haben minimale Abweichungen oder ein kleiner Satz in der Dokumentation wurde falsch verstanden. Was also wenn ein Feature doch noch eine kleine Änderung braucht, weil Entwicklungen parallel liefen?
Beides wird gleichzeitig fertig (ein extra Release-Branch wäre möglich):
Das Basis-Feature geht vorher live:
Das bessere und flexiblere Vorgehen
Gibt es einen Unterschied zwischen Fixes und Features? Nein. Beides sind Improvements des aktuellen States/Zustands. Wenn einem in einem Feature-Branch ein allgemeines Problem auffällt, fixt man das Problem und merged den Master mit der neuen Version erneut in den Feature-Branch.
Zwischenzeitlicher Fix:
Es ist an sich kein Unterschied zwischen einem Fix und einen weiteren Feature-Branch, außer dass der Fix-Branch sehr viel kurzlebiger ist und wohl weniger Commits enthält.
Der Master ist immer stable, weil nur Release-Tags darauf abgebildet sind.
Dieses Herangehen macht es sehr einfach jeden State/Zustand auf System abzubilden. Jeder Branch ist unter seinem Namen zu finden und Tags werden nach Typ auf Systeme gemappt.
Tag auf System:
- release-XXX auf das produktive System
- staging auf das Staging-System (1:1 Namenabbildung)
- demo1-n auch 1:1 per Namen abbilden
Bei staging muss man den Tag löschen und neu anlegen, so kann jeder Zustand auf dem Staging-System deployt werden oder besser gesagt, wird ein Deployment durchgeführt das dann unter der Staging-Domain erreichbar ist. Hier gibt es eine tolle Anleitung wie man solche Systeme mit Traefik oder Kubernetes ganz einfach bauen kann. Ich werde das aber vielleicht auch noch mal genauer beschreiben, wie ich es für gut halte.
Denn Branches halte ich persönlich es nicht für wert wo anders als lokal in einem Docker-Container zu laufen. Da kann ich um es der Fachabteilung lieber schnell einen Tag erstellen und diesen nach dem Input der Abteilung auch wieder unter selben Namen neu anlegen oder unter einen neuen wenn zwei mögliche Umsetzungen verglichen werden sollen (macht das mal mit Git-Flow!).
Edit: Ich habe die per Hand gezeichneten Diagramme durch vollständigere Diagramme, die per Software erstellt wurden, ausgetauscht.
| User | annonyme | 2020-03-29 16:55 |
development, docker, entwicklung, git, git flow, git state, hannes pries, konzept, kubernetes, modern, svn, theorie, traefik, vcs
 write comment:
write comment: