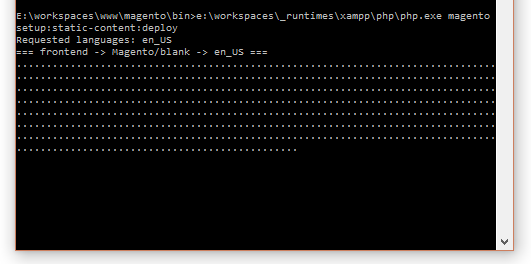
Falls man mal nach längerer Zeit wieder seine Testinstallation aufruft und irgendwie vergessen hat sich das Passwort vom Admin-Konto aufzuschreiben und nicht mehr in den Admin-Bereich kommt, ist es an sich ganz einfach das Passwort neu zusetzen. Man muss nur über die CLI Schnittstelle von Magento 2 gehen.
PHP kann ja Zahlen, die als String vorliegen, direkt als Zahl casten. Was sich erst einmal ganz praktisch anhört ist leider sehr seltsam umgesetzt, da nie validiert wurde, ob der String im Ganzen eine gültige Zahlennotation enthält.
$a = "05" + "10dings";
Der Ausdruck liefert 15 zurück. Jeder aus Java Integer.parseInt() kennt, wird es bei so einem Umgang nur kalte Scheuer über den Rücken jagen.
Einige halten dieses Verhalten zwar für vollkommen korrekt und besonders praktisch, weil einem so der Benutzer durch unsinnige Eingaben die Berechnung nicht kaputt machen kann... aber wenn man mal ehrlich ist, ist "5 stück" + "0.5 eier" + "draussen dunkel" = int(5.5) nicht wirklich ein brauchbares Ergebnis.
Ja da kommt wirklich 5.5 raus.
Aber zum Glück gibt es jetzt mit 7.1 wenigstens eine kleiner Verbesserung. Es wird eine Warnung geworfen.
Number operators taking numeric strings now emit E_NOTICEs or E_WARNINGs when given malformed numeric strings.
Damit ist man schon mal soweit, dass man seinen Code sicher machen kann, wenn man möchte. Man muss es leider nicht, aber dass man es kann ist schon mal ein Fortschritt.
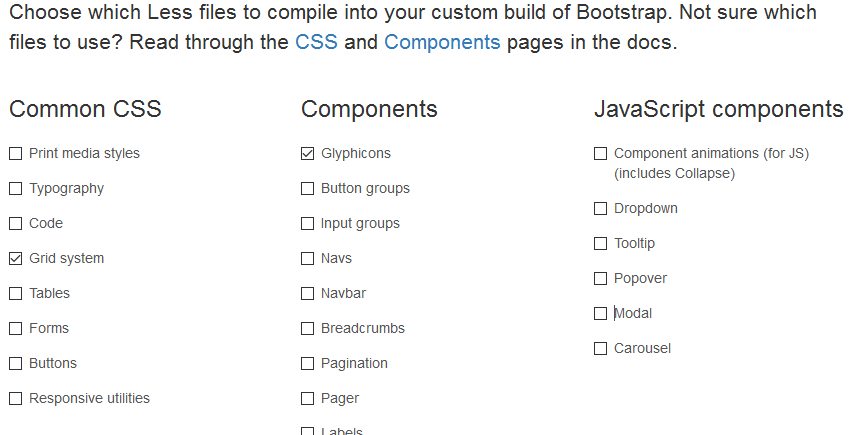
Oft hat man ja eine vorhandene Homepage mit vorhandenen CSS und möchte nur Teile davon erneuern. Wenn man nun einfach Bootstrap hinzufügt ist es bestimmt so, dass das ganze Layout zerfallen wird.
Gerade das Grid ist aber etwas was man gerne zusätzlich zum vorhandenen CSS hätte.
Dafür braucht man aber nicht alles von Bootstrap und zum Glück bietet Bootstrap selbst an sich eine Version zu compilieren, die nur die gewünschten Komponenten enthält. Man kann sich also eine Version bauen, die nur das Grid und die Icons enthält.
Seit Anfang November 2016 begleitet mich ein Microsoft Surface Pro 4 mit Core m3 und hat man altes Toshiba i3 Notebook ersetzt. Das Notebook lief mit Linux Mint echt noch sehr gut, nur die schlechte Lüftung machte mit seiner Lautstärke nicht mehr wirklich Spaß. Es war auch nicht das dünnste und der Akku war von Anfang an kein Highlight. Das Alienware ist echt super und ist schon mit mir durch nass und noch vieler nasser gegangen. Aber es ist eben auch nicht meins sondern gehört meiner Frau und in Urlauben und so, wenn wir beide gerne ein Notebook dabei haben wollen, muss ich immer den kürzeren ziehen.
Der absolute Vorteil des Surfaces ist seine Kompaktheit gepaart mit der Leistungen eines normalen x86-64 Notebooks. Kein ARM, kein Atom und nicht nur 1-2GB RAM. Damit kann ich einfach alles vom Alienware Notebook auf das Surface und direkt dort weiter arbeiten. Nur die 128GB SSD ist etwas klein.
Der Core m3 + 4GB reicht vollkommen für XAMPP (Apache + MySQL) und Eclipse + PDT gleichzeit. Natürlich läuft noch eine Firefox-Instance und meistens auch noch GitKraken. Ich hab keine Performance-Probleme oder merke, dass ich Dinge damit nicht erledigen kann. Klar ist die Xeon-Workstation in allen etwas schneller und einige Programm laden in 5 Sekunden und nicht in 8 Sekunden. Aber am Ende merkt man keinen wirklichen Unterschied mehr wenn erst einmal alle Programme geladen wurden.
Die Tastatur muss man extra kaufen. Sie ist wirklich toll und es fühlt sich nicht so an als würde man auf Gummi-Tasten schreiben. Viele günstige Desktop-Tastaturen sind schlechter. Sie ist beleuchtet und die Halterung über Magneten sorgt dafür, dass man sie schnell an und ab machen kann. Hochklappen ..und sie bleibt oben. Der Netzteilstecker ist genau so befestigt und es funktioniert einfach gut.
Das Surface versucht in einem Punkt nicht so super modern zu sein, wie z.B. das Tab Pro von Samsung: Es hat einen stink normalen USB-Anschluss. Einfach USB-Stick oder DSLR ran und es läuft. Auch eine extra Webcam wie die HD 3000 (für Visual-Distance.com oder das Switch Time-System) sind kein Problem.
Das Einzige was man als nett und an sich praktisch bezeichnen kann ist der Pen und der Digitizer. Der Pen ist irgendwie drucksensitiv. Windows benutzen klappt auch ganz gut. Zeichnen funktioniert auch mit WinTab-Treiber oft nur ohne Druckstufen. 256 Druckstufen sind sowie so nicht so toll. Im Vergleich mit einem Wacom Cintiq 13HD zieht es beim Malen und der Fotonachbearbeitung ganz klar den Kürzeren. Die Striche sind schön sauber und genau, was aber wohl mehr an einer schlechten Auflösung des Digitizers liegen mag. Außerdem muss der Pen geladen werden und wird nicht durch den Digitizer mit Strom versorgt.
Der Preis für ein Surface Pro 4 ist nicht gering, aber dafür bekommt auch ultra kompaktes Geräte in der Form eines Tablets mit der Leistung eines Notebooks und mit Windows 10 Pro, das für alle normalen Webdeveloper-Aufgaben reicht.
Man kann sehr einfach mit CSS auch die Reihenfolge von Elementen ändern. Damit kann man allein schon mit CSS viel an Templates anpassen ohne gleich Twig oder Smarty bemühen zu müssen.
Wenn man alte Software laufen hat, die dann hoffentlich schon PDO nutzt aber nicht jedes SQL-Statement
testen kann, kann man MySQL 5.7 auch dazu bringen sich wie eine alte 5.5 Version zu verhalten. Das kann nötig werden wenn man von Ubuntu 14.04 LTS auf 16.04 LTS upgradet und damit eine aktuellere MySQL-Version installiert wird, die sich meiner Meinung nach sehr viel korrekter mit Werten und Typen verhält als die alte Version.
Wenn man langem ist Oracle gearbeitet hat würde man auch nie auf die Idee kommen für einen Number/Int-Wert '1' an stelle von 1 zu übergeben.
Für mein Projekt Mein-Online-Adventskalender habe ich die alte Fancybox ersetzt und eine eigene kleine Lösung geschrieben. Kein JQuery, kein AngularJS.. einfaches kleines altes JavaScript.
function MediaViewer(){
this.dialog = null;
this.mediaContainers = [];
Man ganz einfache eigene Container in den Dialog einbauen. Der Name wird bei mv-item angegeben. Sollten nur die Tags wie mv-item angegeben sein versucht die Logik im Dialog ein Element des selben Typs (img, video, etc) zu finden.
Ich wollte nur mal kurz Magento 2 installieren (XAMPP und Windows 10 Pro). Aber das Adminpanel wollte nicht funktionieren und auch viele CSS und JS Dateien wurden nicht gefunden.
Ich habe eine Lösung aus zwei Lösungen im Internet gefunden, mit denen es am Ende dann doch alles lief.
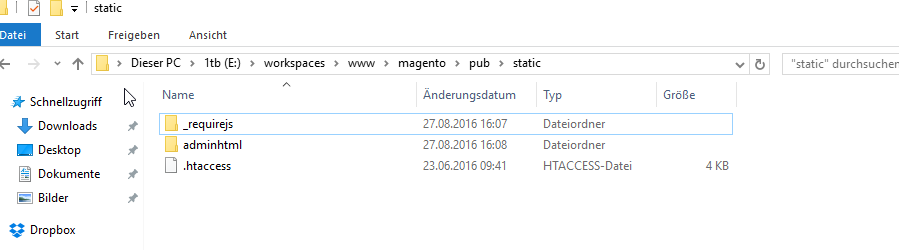
Zuerst habe ich alles bis auf die htaccess aus pub\static gelöscht.
Dann die app\etc\di.xml editiert. Die Strategie von Symbolic-Link auf Copy geändert.
Und dann ein PHP Script ausgeführt, dass alles noch mal neu anlegt. bin\magento.
Nachdem ich im letzten halben Jahr mit Neo4j und nun auch mit Elasticsearch zu tun hatte, bin ich was NoSQL-Datenbanken angeht etwas zwiegespalten. Graphen-Datenbanken sind toll um Beziehungen zwischen Entitäten abzubilden. Dokumenten-orientierte Datenbanken wie Elasticsearch ideal um unstrukturierte Daten zu speichern und neben der eigentlichen Abfrage auch z.B. Durchschnittswerte oder Übersichten von der Abdeckung von bestimmten Attributen/Feldern gleich mit abzufragen.
Die Abfragen sind schnell. Aber.. auch sind die Queries komplexer (Neo4j) bis sehr viel komplexer (Elasticsearch). Der Vorteil der NoSQL Datenbanken ist, dass man schon fertige Objekte zurück bekommt und man nicht auf Tabellenstrukturen beschränkt ist. So kann man also Listen mit Objekten die zu einer Entität gehören gleich mit abfragen und erspart sich ein zweites Query und zusätzliches Mapping.
Aber sind die NoSQL Datenbanken wirklich so viel schneller, wie man immer hört? Dafür muss man verschiedene Dinge bedenken. Zuerst ob die Datenbank die primäre Datenquelle ist oder nur zusätzlich zu einem RDBMS verwendet wird. Ich hatte bis jetzt nur mit zusätzlichen Datenbanken zu tun. Deren Daten wurden durch Cronjobs aus dem RDBMS gelesen, aufbereitet und dann in die NoSQL-Datenbank geschrieben.
Entweder per CSV-Import (Neo4J) oder direkt über die REST-API (Elasticsearch). Die gleichen Abfragen waren in der MySQL-Datenbank langsamer. Nicht viel langsamer. Aber es war doch spürbar und lagen bei der Neo4J bei so 30%-40%.
Wenn man nun aber einberechnet wie viel Aufwand der Import darstellt, der bei beiden Anwendungsfällen zwischen 1,5-5min lag, sieht es schon sehr viel anders aus. Die Importscripte reduzierten die Datenmenge natürlich sehr extrem und schrieben nur die nötigsten Daten in die NoSQL-Datenbanken. Bei der Neo4J waren es wirklich nur Ids und Relationen. Die Elasticsearch hatte alle elementaren Felder und auch Unterobjekte, die bei SQL über Joins geladen werden würden. Auf dieser reduzierten und stark vereinfachten Datenbasis waren die Abfragen sehr schnell.
Wenn man mit ein paar SQL-Statements die selben Daten in der MySQL in dem selben Umfang in eigene Tabellen schreibt, ist die MySQL Datenbank meiner Erfahrung nach genau so schnell. Im Vergleich von MySQL und Neo4J muss man sagen, dass für die Abfragen plötzlich viel mehr Daten zur Verfügung stand und diese auf genutzt wurden. Außerdem wurden doppelt so viele Queries verwendet. Am Ende war die MySQL-Lösung langsamer aber auch sehr viel komplexer und in dem Sinne besser.
Ich für meinen Teil sehe in den NoSQL-Datenbank nur einen Vorteil, wenn man die Vorteile derer auch nutzt. Wenn ich keine Graphen brauche, brauche ich auch keine Neo4J-Datenbank. Habe ich nur Entitäten und DTOs die ich schnell speichern und laden möchte, brauche ich keine Elasticsearch. Elasticsearch ist komplex und kann ein paar wirklich interessante Dinge durch deren Aggregations. Wenn ich haufenweise unterschiedliche Daten aus vielen verschiedenen Quellen zusammen fahren möchte bin ich mit Elasticsearch gut beraten. Aber wenn ich nur Geschwindigkeit haben möchte muss ich nur die Datenbasis verringern und vereinfachen. Neo4J ist auch extrem Speicher hungrig. Was bringt es mir wenn ich 96GB an RAM brauche um das zu machen was ich mit 32GB und einer MySQL oder einer Oracle-DB genau so schnell hinbekomme. Wenn ich dann sehr viel RAM habe und ganze Datenbanken im Speicher halten kann, habe ich die selbe Geschwindigkeit und bin mit der größeren Datenbasis sehr viel flexibler. Außerdem ist alles schneller und sicherer was ich direkt innerhalb der Datenbank machen kann. Ein Import von der MySQL in die Neo4J brauchte viel darum herum um sicher zu sein. In einer Oracle würde alles sowie so in einer Transaction laufen, die auch nicht noch den Server der das Script startet belastet.
Wer also in seinem RDBMS Performanceprobleme hat, soll sie auch dort lösen und nicht glauben, dass ein weiteres System anzubinden (und synchron zu halten) dieses Probleme lösen würde.
Ich benutze Linux jetzt seit über einem halben Jahr bei der Arbeit und auch privat läuft auf einem Notebook Linux. Meine letzten Entwicklungen mit PHP und Java habe ich so entwickelt, dass sie sowohl unter Windows als auch unter funktionieren. Java und PHP machen es auch mehr als einfach, wenn man nicht auf irgendwelche DLLs angewiesen ist. Die RFID-Reader werden über Ethernet angesprochen und zum Glück gibt es beide SDKs nativ für Java.
Für Windows spricht eigentlich nur noch die Adobe Software. In allen anderen Fällen gibt es kaum einen Unterschied mehr. Das sehe wohl nicht nur ich so sondern fast alle. Linux Software wie Openshot 2.0 gibt es jetzt auch für Windows. Microsoft bringt den SQL-Server und jetzt auch die PowerShell für Linux raus. Die Bash gibt es ja auch für Windows.
Und seit es Windows 10 nicht mehr kostenlos gibt, ist der Vorteil von Linux, dass es kostenlos ist, wieder bedeutender geworden. Bei Entwicklern hat man den Vorteil, dass diese sowie so lieber ihre Rechner selbst Administrieren wollen und somit keine weiteren Kosten entstehen durch höheren Administrationsbedarf bei den Benutzern.
Aber auch bei den normalen Benutzern sollte Linux eigentlich eine gute Alternative sein. Die meisten Anwendungen wandern oder sind schon in der Cloud und damit reduziert sich das Betriebssystem schon fast auf einen Luncher für den Webbrowser. Firefox/Chrome und Thunderbird sind auf Windows sowie schon sehr verbreitet und somit ist eine Umgewöhnung fast nicht mehr nötig. Linux Mint sieht fast genau so aus wie ein Windowssystem und das Updaten der Software ist sehr viel zentraler und einfacher zu managen.
Linux ist wie auch Windows 10 sehr sparsam was die Hardware-Resourcen betrifft. Ein altes Notebook mit Pentium Dual-Core und 2GB RAM läuft mit Linux sehr gut und auch Probleme wegen veralteter Windows-Treiber sind gelöst.
Mit gebrauchter Hardware und Linux Mint sollte sich eine komplette IT-Infrastruktur für kleine Büros bauen lassen. Alte aber wieder aufbereitete Hardware ist günstig zu bekommen und Geräte von HP oder Dell auch oft in entsprechenden Stückzahlen an gleichen Geräten, so das man ein paar mehr Geräte kaufen kann, um bei Hardwareausfall gleich Ersatz zur Hand zu haben. Man kann ein Installationsimage erstellen und so Installationen in wenigen Minuten durchführen. Die Kosten sollten sich damit auf vielleicht 40% der Kosten von Neugeräten belaufen und für Internet, Email und Office reicht die Hardware immer noch mehr als aus. Die Leistung eines 10 Jahre alten PCs ist heute immer noch ausreichend. Ich habe meinen PC von 2006 nur gewechselt, weil HyperV darauf nicht lief.. was ich aber trotz neuen PC immer noch nicht verwende und einfach bei VirtualBox geblieben
bin.
Bei VirtualBox wären wir auch schon beim nächsten Punkt: Virtualisierte Server. Ein gebrauchter Server ist nicht teuer und wenn man die Server an sich in VMs laufen lässt, kann man auch immer mal schnell auf einen größeren Server upgraden ohne längere Ausfallzeiten der Systeme zu haben. Bei guter Planung sollte so ein Umzug auf einen neuen Server in 10 Minuten durch geführt sein. Für die meisten Server-Anwendungen braucht man nur eine einfache LAMP-Umgebung. Groupware wie Tine 2.0 bieten Email-Client, Kalender, Adressbuch und alles mögliche und lassen sich auch mit dem Smartphone nutzen. Wer komplette Office-Umgebungen wie Office 365 braucht findet bei OwnCloud und LibreOffice eine Alternative, die leider etwas kostet aber noch relativ günstig ist.
Aber genau wie auch bei Windowsumgebungen und neuer Hardware braucht man jemanden der alles einrichtet und installiert. Wer glaubt diese Kosten mit Windows umgehen zu können, wird sich schnell wundern. Deswegen würde ich keine höheren Administrationskosten bei Linux sehen im Vergleich zu Windows.
Deswegen auch nicht einfach alte Hardware in den Müll werfen! Mit Linux kann die Hardware noch einige Jahre gut weiter verwendet werden und man spart nicht nur sich Kosten sondern schon auch etwas die Umwelt damit. Wer es noch nicht versucht hat, sollte Linux mal eine Chance geben. Ich werde jedenfalls mal Collabora testen. Es wäre sicher eine Lösung, die gerade kleineren Firmen viele Kosten sparen kann.
Die erste Komponente für den 100 Euro Office Server ist schon angekommen. Die CPU hat 7 Euro gekostet. Der wird nur aus gebrauchten Teilen bestehen.. ich werde berichten.
Eine Website wo jeder sich einen Online Adventskalender mit eigenen Bildern und Videos erstellen kann. Es wurde auch alles so angepasst, dass auch Firmen es nutzen können und ihre Weihnachtsaktionen und Gewinnspiele darüber abwickeln können.
Einfach mal ausprobieren. Es ist alles in der normalen Ausführung kostenlos und es existiert eine ausführliche Anleitung. Sollte eine speziellere Integration als der IFrame benötigt werden, kann auch hier eine spezielle Lösung auf Anfrage entwickelt werden.
Man kann sich hier einen Online Adventskalender bauen, der sich so konfigurieren lässt, um verschiedene Einsatzgebiete abzudecken. So kann man dann nicht nur einen einfachen Kalender erstellen, bei dem an jedem Tag ein neues Bild, GIF oder Video angezeigt wird, sondern auch spezielle Texte für den aktuellen Tag setzen und Links auf externe Seiten setzen.
Damit kann man also auch für jeden Tag z.B. einen Gutscheincode oder eine spezielle Gewinnspiel-Frage setzen. Dieser Text ist dann nur am vorgesehenen Tag sichtbar ohne das man händisch eingreifen muss.
Den Kalender kann man dann teilen in dem man den Link auf mit anderen teilt oder sich den Code für den IFrame kopiert und den Kalender in seine eigene Homepage einbinden.
Elastica ist sehr radikal was deprecated Methoden angeht. Es werden nicht einfach nur Warnings angezeigt sondern gleich Exceptions geworfen. Deprecated Warning ignoriert man gerne. Besonders wenn man aus dem Java-Bereich kommt, weil dort ist man gewohnt (Beispiel die Date-Klasse), dass Methoden zwar deprecated sind, aber ewig weiter existieren und dass meistens auch weiterhin fehlerfrei- Die wurden meistens nur deprecated, weil die Funktionalität in eine andere Klasse verschoben wurde oder es eine neue Funktionalität gibt, die mehr kann und die alte voll umfassend ersetzen kann.
Das werfen von Exceptions, die man mit Try-Catch auffangen könnte motiviert aber ungemein, gleich alles auf das neue Vorgehen umzubauen. Warnings sind ok.. Exception dürfen aber nicht sein. Das Warning ignoriert oder gleich ganz abgeschaltet werden führt auch immer wieder zu "lustigen" Vorkommnissen. "Wieso hast du einfach die Methode gelöscht.. die hab ich an mehreren Stellen verwendet!" - "1. war sie fast 10 Monate als Deprecated markiert.." - "... Warning hab ich abgeschaltet.. waren zu viele.." - ".. und 2. soll bitte die Service-Schnittstelle des Modules genutzt werden,weil dort wurde schon vor 11 Monaten auf die neue und schnellere Methode umgestellt"
Man sollte seinen Code immer Warning-frei halten und nicht einfach Warning ignorieren, weil man ein paar einfach nicht entfernen kann, weil z.B. der Code-Parser der IDE glaubt er könnte das SQL-Statement, dass aus mehreren Strings zusammen gebaut wird brauchbar auf Fehler untersuchen.
Older posts:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von