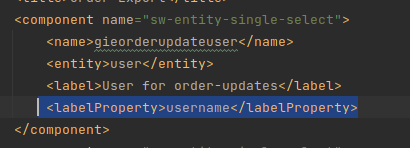
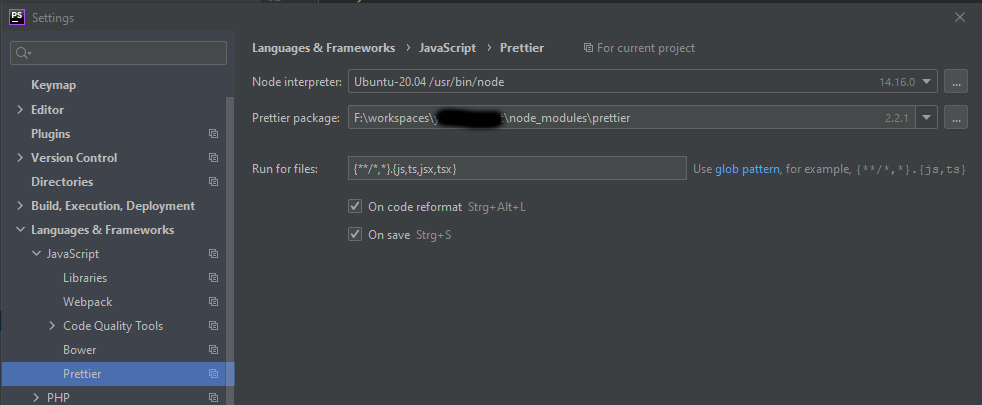
Einfach den Inhalt der id_rsa.pub zu nehmen und dort einzutragen funktioniert leider nicht, da das Format nicht übereinstimmt. Eine Datei mit mit dem entsprechenden Key kann man sich aber sehr schnell erzeugen.
ssh-keygen -i -f ~/.ssh/id_rsa.pub > openssh.pub
Hier meine aktuelle Docker-Umgebung für Shopware 6 und mit PHP 7.4
FROM php:7.4-apache
RUN apt-get update &&\
apt-get install --no-install-recommends --assume-yes --quiet ca-certificates \
curl \
git \
libxml2-dev \
libxslt-dev \
libfreetype6-dev \
libjpeg62-turbo-dev \
libpng-dev \
libcurl4-gnutls-dev \
zlib1g-dev \
libzip-dev \
&& docker-php-ext-install -j$(nproc) iconv \
&& docker-php-ext-configure gd --with-freetype=/usr/include/ --with-jpeg=/usr/include/ \
&& docker-php-ext-install -j$(nproc) gd
RUN apt-get install -y libc-client-dev libkrb5-dev \
&& docker-php-ext-configure imap --with-kerberos --with-imap-ssl \
&& docker-php-ext-install imap
RUN docker-php-ext-install pdo_mysql \
&& docker-php-ext-install json \
&& docker-php-ext-install dom \
&& docker-php-ext-install curl \
&& docker-php-ext-install zip \
&& docker-php-ext-install intl \
&& docker-php-ext-install xml \
&& docker-php-ext-install xsl \
&& docker-php-ext-install fileinfo
RUN rm -rf /var/lib/apt/lists/*
RUN echo 'memory_limit = 512M' >> /usr/local/etc/php/php.ini
RUN a2enmod rewrite
# copy conf-file to /etc/apache2/sites-enabled/000-default.conf
RUN mkdir /files;
COPY ./setup.sh /files/setup.sh
ENTRYPOINT ["sh", "/files/setup.sh"]
Config und setup.sh kann nach eigenen Bedarf ersteltl werden. ich nutze localhost:
conf
<VirtualHost *:80>
ServerName localhost
ServerAlias www.localhost
DocumentRoot "/var/www/html/public"
RewriteEngine On
RewriteMap lc int:tolower
<Directory "/var/www/html/public">
Options Indexes FollowSymLinks
AllowOverride All
Require all granted
DirectoryIndex index.php
</Directory>
</VirtualHost>
setup.sh
/usr/sbin/apache2ctl -D FOREGROUND
Hier könnten aber auch noch composer install und so eingebaut werden.
Nachdem ich wieder einmal Keys von Windows auf ein Linux-System umgezogen haben und wieder erstmal herausfinden musste wie die Rechte gesetzt sein müssen.. hier einmal ein kurzes Script dazu:
cd ~/.ssh
sudo chmod -R 0700 .
sudo chmod 0644 id_rsa.pub
sudo chmod 0600 id_rsa
Design-technisch sieht sowas ja immer echt hübsch aus. Das aber umzusetzen ist erstmal nicht ganz so einfach, da es keine fertige Lösung gibt. Hier muss mal wieder ein eigenes Element mit :before und einer absoluten Position helfen.
Absolute Postionen sind nicht wirklich toll, weil damit das Element aus dem Fluss der Elemente entfernt wird. Wenn man z.B. zwei Divs übereinander legen möchte ist es auch besser da CSS-Grid zu verwenden und beide mit der selben Startposition im Grid abzulegen.
Aber zurück zu den Rändern. Hier erstmal mit "absolute":
Links (80% Länge):
div.left:before {
content : "";
position: absolute;
left : 0;
top : 0;
height : 80%;
width : 50%;
border-left:5px solid #726E97;
}
Links (80% Länge und unten + oben Abstand):
div.left:before {
content : "";
position: absolute;
left : 0;
top : 10%;
height : 80%;
width : 50%;
border-left:5px solid #726E97;
}
Manchmal sind ganz einfache Dinge sehr komplex. CSS-Ellipsis ist an sich einfach. Aber mit Flexbox kann es plötzlich dazu kommen, dass es einfach nicht funktioniert. Alles funktioniert nur die "..." sind nicht zusehen, weil es einfach alles zur Seite rausragt und die Breite hält.
<div class=""flex-container">
<div class="flex-child">
<header>LONG TEXT</header>
</div>
</div>
.flex-child header{
text-overflow: ellipsis;
overflow: hidden;
white-space: nowrap;
}
Die Lösung hier ist [url=]https://css-tricks.com/flexbox-truncated-text/min-width: 0;[/url].
Also:
.flex-child {
min-width: 0;
}
.flex-child header{
text-overflow: ellipsis;
overflow: hidden;
white-space: nowrap;
}
Super schnelle Lösung.. aber wie sollte man da alleine drauf kommen, wenn man nur mal schnell Ellipsis einbauen will?
Das meiste findet man immer nur für die Bash. Aber wenn man Docker für Windows verwendet braucht man vieles für die PS. Ich habe hier mal ein paar kleine Dinge zusammen getragen.
Alle Container stoppen:
docker ps -aq | foreach {docker stop $_}
Alle (gestoppten) Container entfernen:
docker ps -aq | foreach {docker rm $_}
Alle (ungenutzen) Images entfernen:
docker images -qa | foreach {docker rmi -f $_}
Alle (ungenutzen) Volumes entfernen:
docker volume ls -qf dangling="true" | foreach {docker volume rm $_}
Alle (custom) Netzwerke entfernen:
docker network ls -q --filter type=custom | foreach {docker network rm $_}
Mein momentanes Dev-Setup für Web-Installer Installation von Shopware 6.
Verzeichnisse und Dateien:
containerData/
apache/
Dockerfile
my_vhost.conf
setup.sh
db_vol/
sw/
...
docker-compose.yml
Web-Installer Dateien kommen in das sw-Verzeichnis.
Dockerfile
FROM php:7.2-apache
RUN apt-get update &&\
apt-get install --no-install-recommends --assume-yes --quiet ca-certificates \
curl \
git \
libxml2-dev \
libxslt-dev \
libfreetype6-dev \
libjpeg62-turbo-dev \
libpng-dev \
libcurl4-gnutls-dev \
zlib1g-dev \
&& docker-php-ext-install -j$(nproc) iconv \
&& docker-php-ext-configure gd --with-freetype-dir=/usr/include/ --with-jpeg-dir=/usr/include/ \
&& docker-php-ext-install -j$(nproc) gd
RUN apt-get install -y libc-client-dev libkrb5-dev \
&& docker-php-ext-configure imap --with-kerberos --with-imap-ssl \
&& docker-php-ext-install imap
RUN docker-php-ext-install pdo_mysql \
&& docker-php-ext-install json \
&& docker-php-ext-install dom \
&& docker-php-ext-install curl \
&& docker-php-ext-install zip \
&& docker-php-ext-install intl \
&& docker-php-ext-install xml \
&& docker-php-ext-install xsl
RUN rm -rf /var/lib/apt/lists/*
#RUN pecl install xdebug-2.8.0 && docker-php-ext-enable xdebug
#RUN echo 'zend_extension="/usr/local/lib/php/extensions/no-debug-non-zts-20151012/xdebug.so"' >> /usr/local/etc/php/php.ini
#RUN echo 'xdebug.remote_port=9000' >> /usr/local/etc/php/php.ini
#RUN echo 'xdebug.remote_enable=1' >> /usr/local/etc/php/php.ini
#RUN echo 'xdebug.remote_host=host.docker.internal' >> /usr/local/etc/php/php.ini
RUN echo 'memory_limit = 512M' >> /usr/local/etc/php/php.ini
RUN a2enmod rewrite
# copy conf-file to /etc/apache2/sites-enabled/000-default.conf
RUN mkdir /files;
COPY ./setup.sh /files/setup.sh
ENTRYPOINT ["sh", "/files/setup.sh"]
my_vhost.conf
<VirtualHost *:80>
ServerName localhost
ServerAlias www.localhost
DocumentRoot "/var/www/html/public"
RewriteEngine On
RewriteMap lc int:tolower
<Directory "/var/www/html/public">
Options Indexes FollowSymLinks
AllowOverride All
Require all granted
DirectoryIndex index.php
</Directory>
</VirtualHost>
setup.sh
/usr/sbin/apache2ctl -D FOREGROUND
docker-compose.yml
version: '3.3'
services:
sw_mysql:
image: bitnami/mysql:5.7
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: sw
MYSQL_USER: sw
MYSQL_PASSWORD: sw
volumes:
- ./db_vol/:/bitnami/mysql/data
sw_http:
build: ./containerData/apache
volumes:
- ./containerData/apache/my_vhost.conf:/etc/apache2/sites-enabled/000-default.conf:rw
- ./sw:/var/www/html:rw,delegated
ports:
- 80:80
- 443:443
mail:
image: mailhog/mailhog
ports:
- 8025:8025
adminer:
image: adminer
ports:
- 8082:8080
depends_on:
- sw_mysql
Ich musste mir eine sw2-Datenbank anlegen über root/root, aber an sich sollte es wie in meinem SW5-Environment auf mit der sw-Datenbank und sw/sw gehen.
Wenn man Probleme hat die PHP IMAP-Erweiterung unter Docker zu installieren, kann dieses helfen:
RUN apt-get install -y libc-client-dev libkrb5-dev \
&& docker-php-ext-configure imap --with-kerberos --with-imap-ssl \
&& docker-php-ext-install imap
Bei mir und meiner Shopware 6 Dev-Umgebung hat es jedenfalls gut geholfen.
Es gab beim Bauen des Images vorher diesen Fehler:
utf8_mime2text() has new signature, but U8T_CANONICAL is missing. This should not happen. Check config.log for additional information.
array_merge:
let a = [23, 42, 69];
let b = [112, 256 ...a];
isset() oder ??:
let data = {a: 2, b: 3};
let result = a?.c ?? 0;
Object-Felder als Arguments verwenden:
let data = [
{
id: 0,
name: 'test'
}
];
data.forEach(
({id, name}, idx) => {
console.log(id + ' is named as ' + name + ' and has the index ' + idx);
}
);
Wo findet man die für Hooks benötigte sh.exe aus der normalen Git-Installation?
C:\Users\__your_user__\AppData\Local\Programs\Git\bin\sh.exe
Die Datei in den Preferences auswählen und dann läuft es.
 bezahlt von
bezahlt von