Es begab sich zur Weihnachtszeit, dass Notebookswieneu günstige SSDs hatte und ich eine SSD brauchte. Zusätzlich waren die WOW-Ladezeiten bei dem PC meiner Frau nicht wirklich toll, da WOW von der HDD geladen wurde, weil die SSD zu voll war. Also gleich mal 2 SSDs gekauft. Knapp 16 EUR für eine 256GB Samsung NVMe SSD konnte man ja nicht viel falsch machen.
Das Problem kam als ich fest stellen musste, dass das "alte" AM4-Mainboard nur einen PCIe 1x Slot frei hat. Also einen entsprechenden Adapter gekauft.
PCIe 1x limitiert bei ca. 450MB/s. Alles andere läuft normal, nur die Lesegeschwindigkeit limitiert. Schreibt also an sich genau so schnell wie sie liest.
Aber abschließend ist zu sagen: Selbst mit PCIe 1x ist die SSD noch bedeutend schneller als die HDD.
300 Euro ist bei PCs ein seltsames schwarzes Loch. Man kann gut was darunter bauen, in dem man APUs verbaut und man kann noch viel einfacher ein einen teureren PC zusammen bauen. Bei 300 Euro ist die Grenze zwischen "einfachen" PC und "leistungsfähigen" PC, der auch für Spiele und mal ein paar Docker-Container mehr geeignet ist. Bei neuwertigen Komponenten kommt man nicht um die APUs von AMD herum. Ein Ryzen 3 3200G kostet um die 90 Euro und bringt eine brauchbare 4-Core CPU (ohne SMT) und eine GPU (die viel schneller als die Intel iGPUs ist) mit. Ein günstiges Mainboard und man hat einen netten kleinen PC. Aber er ist eben nur nett und nicht gut. Da fehlt ein klein wenig dazu und dann ist man schon wieder gleich bei um die 500 Euro.
Also dachte ich mir, ich versuche es mit zu meist gebrauchten Komponenten und will etwas was über einem 3200G liegt. Er sollte schneller sein als mein PC von 2010. Klingt leicht, ist aber am Ende gar nicht so einfach, weil gute Komponenten von 2012-2014 auch heute noch sehr gut mit günstigen modernen Komponenten mithalten können. Es ist echt deprimierend wie wenig Mehrleistung man für doch relativ viel Geld nur bekommt.
Basis des ganzen PC ist ein Proof-Of-Concept Versuch mit einem chinesischen X99 Mainboard mit Sockel 2011-3. Alle Boards mit diesem Sockel sind noch extrem teuer. Selbst von Gigabyte oder Asus bekommt man nichts günstiges... von Supermicro und Intel brauchen wir erst gar nicht reden. Ich wollte einfach mal wissen, ob diese Mainboards aus China wirklich laufen, da sie vieles kombinieren, was es sonst so teilweise nicht gab. M.2-Slots auf solchen Boards zum Beispiel.
Dann hatte ich noch eine alte HP x4000 Workstation, deren Gehäuse ich schon immer sehr gemocht habe und gerne weiter benutzen wollte. Der Lack war teilweise ab und der Frontpanel-Anschluss passt wohl nur auf ein Tyan Thunder i860. Aber es gibt ja Lack im Baumarkt und Kabel beim Amazon um den Frontpanel-Connector Kabel für Kabel zu adaptieren. Die Belegung konnte ich einfach im Handbuch des Mainboard nachlesen.
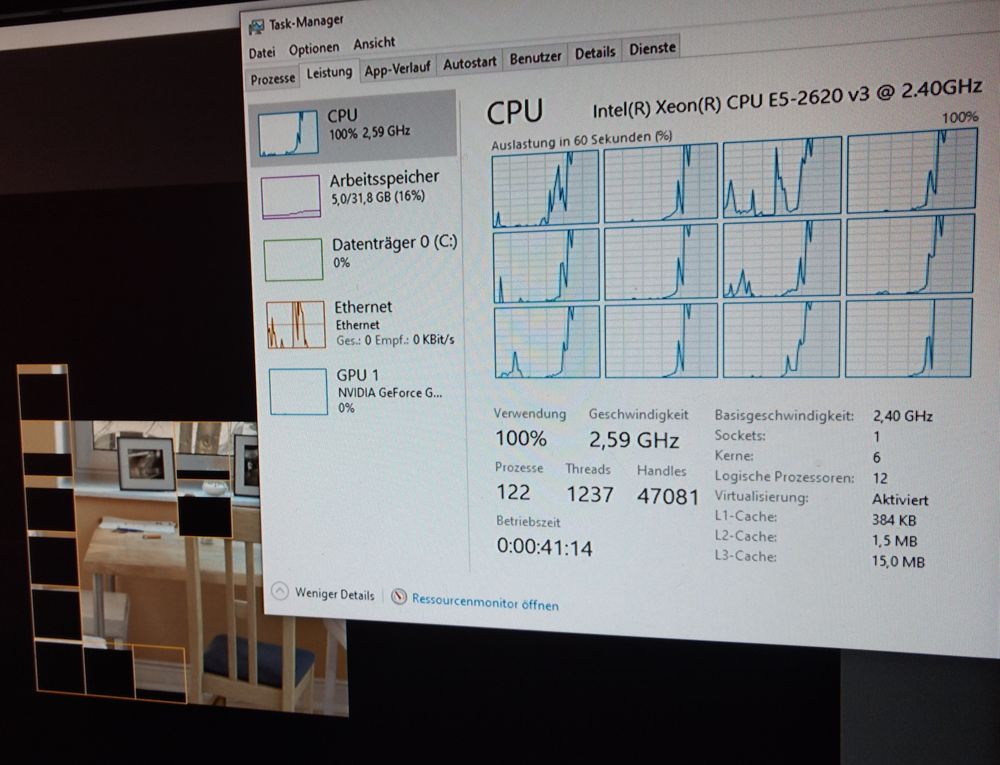
Nach viel hin und her kam dann ein E5-2620 v3 für 20 Euro aus China hinzu. War relativ günstig und ich hatte etwas Angst einen teureren Prozessor zu verwenden, weil ich mir nicht sicher war, wie sich das alte Netzteil aus der x4000 verhalten würde. Ich ging einfach davon aus, dass es ein normales ATX-Netzteil ist. Später stellte sich heraus, dass der 8pin 12V Anschluss nicht lang genug war und anstelle eines weiteren Adapters zusätzlich zu den Adaptern für die Grafikkarte, kaufte ich für 20 Euro einfach ein älteres BeQuiet Netzteil, wo ich alles ohne zusätzliche Adapter anschließen konnte. Bei der Grafikkarte wollte ich eigentlich eine RX480 oder RX570 haben, aber am Ende wurde es eine GTX 970 für 60 Eur. 32GB DDR4 ECC Speicher kam auch hinzu. 16GB ist für heutige Anwendungen einfach zu wenig. Als Kühler für den Sockel 2011-3 hab ich einen ARCTIC Freezer 33 eSports ONE der wohl auch seine Arbeit ganz gut erledigt.
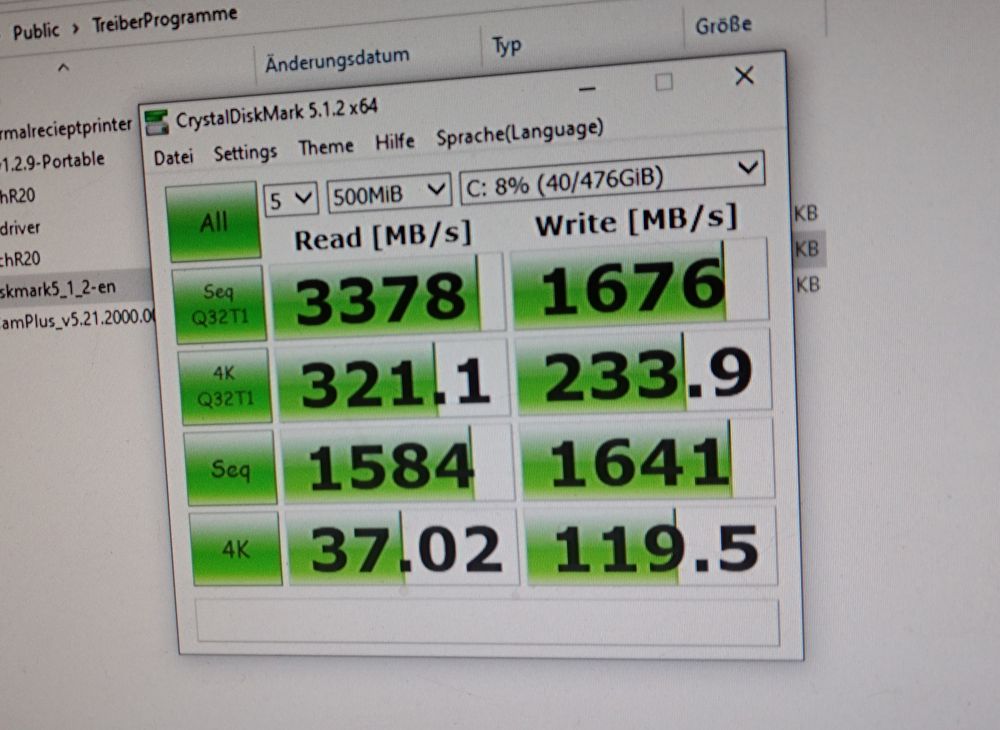
Eine Geschichte von viel Glück und Inkompetenz brachte mir zwei Samsung 512GB NVMe SSDs für je 16,20 Euro ein. Echt schnell und ausreichend groß... gerade für den Preis. Ist zwar Lenovo-OEM aber scheinen trotzdem nicht die langsamsten zu sein.
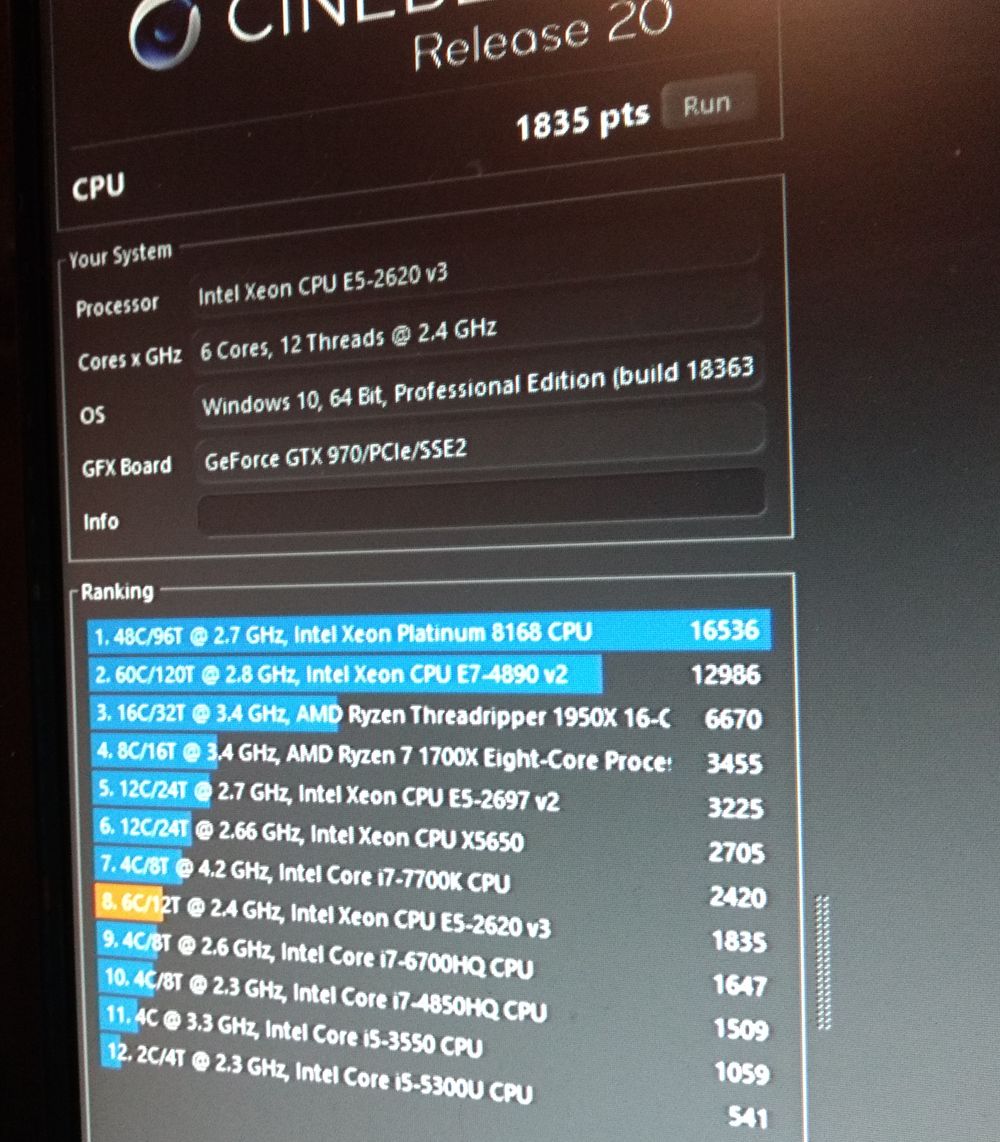
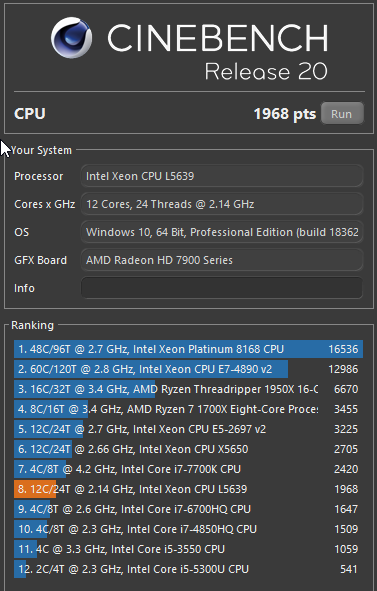
Bis jetzt läuft der PC sehr gut und ist ungefähr so schnell wie mein alter 2x L5639, nur die Grafikkarte ist bei dem neuen schneller als die alte Radeon 7950. Eine CPU leistet also an sich so viel wie vorher zwei, hat aber auch nur den Stromverbrauch einer der CPUs. Wer also mit China-Boards ein günstiges System bauen möchte, sollte nicht mehr mit dem Sockel 1366 anfangen, sondern eher dual 2011 oder ein single CPU 2011-3 System mit aktuelleren CPUs aufbauen. Aber mit den modernen Ryzen Zen2 CPUs von AMD ist es echt schwer geworden mit gebrauchten Komponenten preismäßig mithalten zu können. Man bekommt einfach heute extrem viel Leistung für extrem wenig Geld.
Hier einmal die Ergebnisse des E5 2620 v3 auf einem China X99 Board. Nur etwas langsamer als meine 2 L5639. Also sind 6C/12T fast genau so schnell wie 12C/24T.
Ich bin gerade dabei eine alte HP x4000 Workstation mit neuen Innenleben zu füllen. Das alte dual Netburst Xeon-System wird einem einfachen E5 v3 Single-CPU System weichen. Wenn man sich aktuelle HP Workstations der Z-Serie ansieht, sind die Gehäuse so speziell, dass man keine normalen Komponenten verbauen kann. Deswegen bin ich auch so von dem alten x4000er Gehäuse begeistert. Egal was man hat, es passt rein. Ich habe das alte Delta Electronics Netzteil gegen eines von BeQuiet getauscht. Das alte war natürlich höher. Aber man kann zum Glück die Stütze für das Netzteil nach oben versetzen, so dass
keine Lücke entsteht.
Auch längere Netzteile sind kein Problem, da für alle Längen eine zusätzliche Schiene eingebaut werden kann, mit der man das Netzteil verschrauben und so stabilisieren kann.
Leider hat das kleine BeQuiet Netzteil keine Möglichkeit es so fest zu schrauben. Bei der Größe ist es zum Glück auch nicht wirklich nötig.
Und mit das Tollste überhaupt: Bohrungen für Schrauben, die man gerade nicht braucht und so im Gehäuse aufbewahren kann.
Aus Shopware kennt man das Prinzip, dass man beim Erweitern von Templates einfach "parent:" angeben muss und es wird immer das vorher gehende Template mit dem selben Pfad erweitert. So kann man ein Template mehrmals durch eine unbekannte Anzahl von Plugins erweitern lassen. Twig will aber immer einen Namespace haben. Also muss man heraus finden, mit welchen Plugin man anfängt und welches Plugin dann auf das aktuelle folgt oder man auf das Basis-Template gehen muss. Ich hab mich von der Shopware 6 Implementierung inspirieren lassen und ein kleines Beispiel gebaut, bei dem man die ein Template erweitern kann und die Plugin-Namespaces immer dynamisch ergänzt werden.
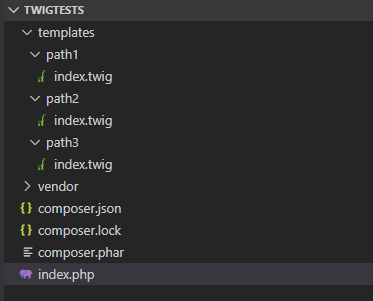
Die Verzeichnisstruktur des Beispiels ist sehr einfach:
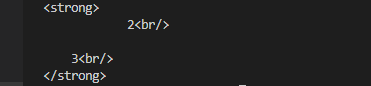
Die Basislogik habe ich in einer einfachen Function zusammen gefasst. Hier wird entweder das Plugin heraus gesucht mit dem angefangen werden muss oder das Plugin, das auf das aktuelle folgt und auch dieses Template mitbringt.
function findNewBase($template, $list = [], $currentBase = null) {
$result = 'base';
$found = $currentBase == null; //if null, took the first one
foreach($list as $key => $path) {
if($key == $currentBase) {
$found = true;
}
else if ($found && file_exists($path . '/' . $template)) {
$result = $key;
break;
}
}
return $result;
}
Die Integration wird über ein Token-Parser implementiert.
final class ExtTokenParser extends AbstractTokenParser {
/**
* @var Parser
*/
protected $parser;
private $list = [];
public function __construct(array $list)
{
$this->list = $list;
}
public function getTag(): string
{
return 'base_extends';
}
/**
* @return Node
*/
public function parse(Token $token)
{
$stream = $this->parser->getStream();
$source = $stream->getSourceContext()->getName();
$template = $stream->next()->getValue();
$stream->injectTokens([
new Token(Token::BLOCK_START_TYPE, '', 2),
new Token(Token::NAME_TYPE, 'extends', 2),
new Token(Token::STRING_TYPE, $parent, 2),
new Token(Token::BLOCK_END_TYPE, '', 2),
]);
Jetzt fehlt nur noch eine passende include-Funktion und man kann sich selbst ein System bauen, desen Templates sich über Plugins ohne Probleme erweitern lassen. Ich arbeite daran....
Edit: Die vollständige Implementierung mit extends und include ist jetzt auf GitHub zu finden.
Seit dem 14. Januar gibt es keinen kostenlosen Support mehr für Windows 7. Mircrosoft rät dringendst dazu auf Windows 10 zu wechseln und bei älterer Hardware gleich auf Surface-Geräte zu wechseln. IT-Magazine überschlagen sich mit den Analysen, ob man nicht direkt zu Linux wechseln könnte und die MacOS-Benutzer erzählen, dass sie glücklich sind solche Probleme nicht mehr zu haben.
Zum Glück gibt es in meinem Umfeld noch genau 1 Windows 7 System und da hatte man sich schon sehr früh überlegt, das so lange wie möglich so zu belassen. Einige Menschen kommen mit Veränderungen einfach nicht klar und allein die Änderungen an der Optik des Anmeldebildschirms kann dazu führen, dass Menschen in eine totale Verweigerungshaltung gehen. Allein sich den Anmeldebildschirm anzusehen wird als Zumutung und Zwang empfunden. Eine Benutzung ist kann man gleich vergessen.
Aber zum Glück war der Rest in den letzten 2 Jahren relativ problemlos zu migrieren. Einige bekamen neue Hardware. Das allein war schon schlimm, weil man dann ja alles neu installieren musste und vielleicht alte Software, die man 2006 mal benutzt hat nicht mehr funktionieren könnte. Lizenz-Keys... da darf man sowie so nicht erwarten, dass die noch da sind. Zu erst darf man sich einen erbosten Vortrag darüber anhören, wie man es einbilden könne, zu verlangen, dass man selber auf seine Sachen aufpasst und man doch der IT-Typ wäre und deshalb dafür verantwortlich ist, dass Leute ihre teuer gekauften Keys nicht in den Papierkorb werfen oder ihre Emails löschen.
Aber dann kann man anfangen mit diesen Leute eine Liste zu erstellen, was sie für Programme installiert haben und welche sie davon wirklich auch benutzen. Wichtig ist da hart zu bleiben und auf "aber vielleicht brauche ich das nach 15 Jahren ja doch mal wieder" nicht einzuknicken. Wenn es gebraucht wird kann man es ja immer noch installieren.
Auch sollte man wenn möglich dabei versuchen, neuere Versionen durch zu setzen oder alte kommerzielle Software durch OpenSource und Freeware zu ersetzen.
Niemals Updates von Windows machen! Immer alles komplett neu installieren. Da ist so viel Schrott auf den Systemen installiert dass man plötzlich mehr als doppelt so viel Speicherplatz wieder frei hat und das System wieder viel schneller läuft. Am Besten ist sogar, falls noch eine HDD verbaut ist, direkt auf eine SSD umzusteigen. Die alte Festplatte wird dann zur Seite gelegt (bei einem selber, damit der ehemalige Besitzer, die nicht einfach wieder dann dauerhaft über USB anschließt und versucht davon alte Programm zu starten oder zu kopieren) und nur in Notfällen wieder raus geholt. Nach 1 Jahr wird die dann, die Festplatte eine neuen Verwendung oder eher wahrscheinlich dem Elektromüll zugeführt.
Am schlimmsten sind aber die Personen, die nicht auf Windows 10 upgraden wollen, weil sie gelesen haben, dass viele Programme und Spiele unter Windows 10 nicht mehr funktionieren. Die vorgebrachte Liste ist lang: Sims 2, Sykrim, Sims 3, Dragon Age, Diablo 2, etc. Es ist schwer diese Liste zu widerlegen, denn selbst wenn man diesen Personen ein laufendes Sims 2 auf einem Windows 10 System unter die Nase hält, werden sie behaupten, dass man sich irren würde und doch klar im Internet jemand geschrieben hat, es würde nicht funktionieren. Bei Diablo 2 gibt es z.B. von Blizzard aktualisierte Installer, die ohne die CDs auskommen, die Probleme machen mit einem alten Kopierschutz. Am Ende läuft doch alles, wenn man es alles sauber ein mal neu installiert und nicht einfach halbe Programm-Verzeichnisse kopiert und irgendwo hinlegt.
Also bleibt am Ende noch ein Windows 7 System... das nächste Woche den Weg SSD + Win10 gehen wird.
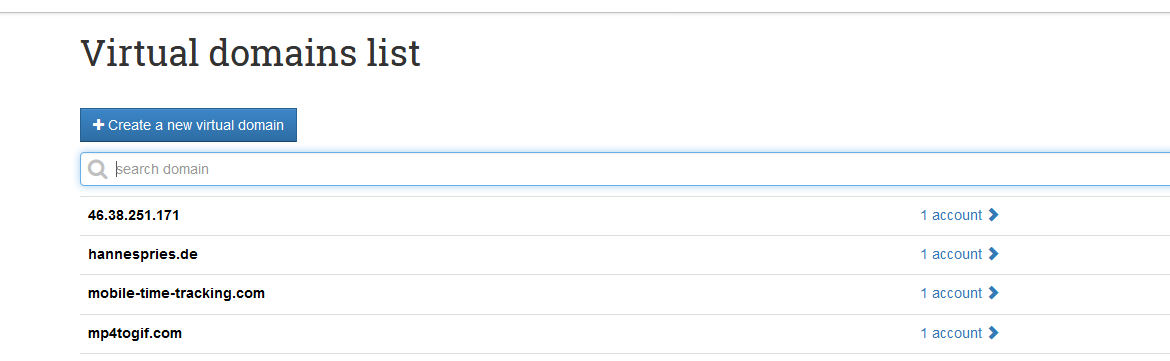
Ich hatte lange Zeit ja ein Postfix mit Dovecot laufen. Hat an sich gut funktioniert, aber es kam viel Spam durch und die Konfiguration und Erweiterung um Spamfilter war kompliziert und umständlich. Ich wollte einfach etwas was ich starten kann, meine Domains und Postfacher eintragen kann und dann alles läuft. Denn wenn es schon so viele Anleitungen gibt, hat doch sicher so etwas schon fertig als Docker-Image haben.
Am Ende bin ich bei poste.io gelandet. Dass kann man einfach mit einigen Angaben starten und es läuft dann einfach. Schnell und stabil, wie es sich wünscht. Man kann ganz einfach Weiterleitungen und eigene Postfächer für alle seine Domains anlegen und kann auch direkt mit Roundcube einen kleinen Webmailer-Service bauen. Das habe ich aber nicht gemacht.
Auf habe ich es nicht zusammen mit Traefik laufen, sondern allein auf eigenen Ports. Es soll eben allein für mich meine Weiterleitungen erledigen und dabei nicht so Spam-empfindlich sein.
Dazu kann ich sagen, dass der Spam-Filter wirklich gut funktioniert.
Ich hatte viel rumprobiert und bin mit diesem Start-Script ganz zufrieden:
Um die Traefik Labels einzubauen hat man ja die Wahl diese im Image zu haben oder im Container. Während man die dem Container beim Starten geben kann, muss man die für das Image beim Build-Process schon haben. Ich benutze beides und muss sagen, dass ich an sich dafür bin die dem Container zu geben. Aber falls man sich mal fragt wie man dynamische Labels dem Image geben kann... ARG ist das Geheimnis.
Wenn ich nun eine dynamische Subdomain haben will:
FROM httpd:2.4
ARG subdomain
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:$subdomain.example.com
Hier kann man dann auch auf ENV-Variablen zurück greifen und die weiter durch reichen. Was sehr praktisch ist, wenn man sich in einem Gitlab-CI Job befindet.
Nachdem ich meine wichtigsten Projekte in Docker-Container verfrachtet hatte und diese mit Traefik (1.7) als Reserve-Proxy seit Anfang des Jahres stabil laufen, war die Frage, was ich mit den ganzen anderen Domains mache, die nicht mehr oder noch nicht produktiv benutzt werden.
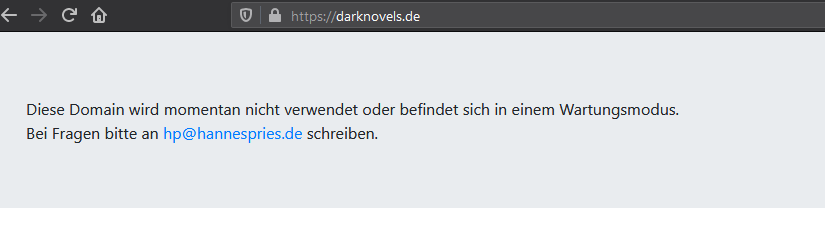
Ich hatte die Idee einen kleinen Docker-Container laufen zu lassen, auf den alle geparkten Domains zeigen und der nur eine kleine Info-Seite ausliefert. Weil das Projekt so schön übersichtlich ist und ich gerne schnell und einfach neue Domains hinzufügen will, ohne dann immer Container selbst stoppen und starten zu müssen, habe ich mich dazu entschieden hier mit Gitlab-CI ein automatisches Deployment zubauen. Mein Plan war es ein Dockerfile zu haben, das mir das Image baut und bei dem per Label auch die Domains schon angegeben sind, die der Container bedienen soll. Wenn ich einen neuen Tag setze soll dieser das passende Image bauen und auf meinem Server deployen. Ich brauche dann also nur noch eine Datei anpassen und der Rest läuft automatisch.
Dafür habe ich mir dann extra einen Gitlab-Account angelegt. Man hat da alles was man braucht und 2000 Minuten auf Shared-Runnern. Mehr als genug für meine Zwecke.
Ich habe also eine index.html und ein sehr einfaches Dockerfile (docker/Dockerfile):
FROM httpd:2.4
COPY ./index.html /usr/local/apache2/htdocs/index.html
LABEL traefik.enable=true traefik.frontend.rule=Host:darknovels.de,www.darknovels.de
Das wird dann also in einen Job gebaut und in einem nach gelagerten auf dem Server deployed. Dafür braucht man einmal einen User auf dem Server und 2 Variablen in Gitlab für den Runner.
Dann erzeugt man sich für den User einen Key (ohne Passphrase):
su dockerupload
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
exit
Vielleicht muss man da noch die /etc/ssh/sshd_config editieren, damit die authorized_keys-Datei verwendet wird.
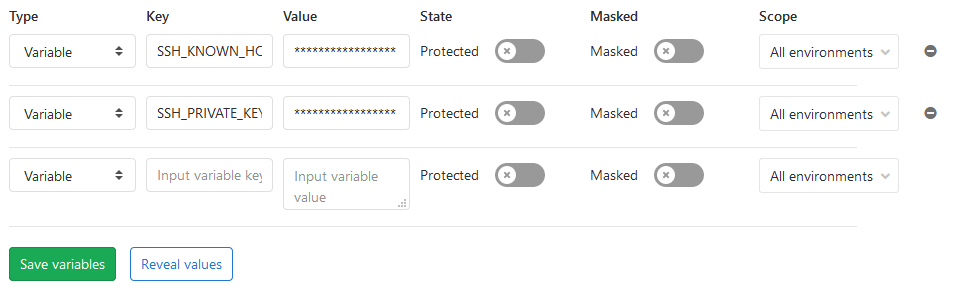
Den Private-Key einmal kopieren und in SSH_PRIVATE_KEY unter Settings - CI /DI - Variables speichern. Damit wir uns sicher vor Angriffen verbinden können müssen wir noch den Server zu den bekannten Hosts hinzufügen. Den Inhalt von known_hosts bekommt man durch:
ssh-keyscan myserver.com
Einfach den gesamten Output kopieren und in den Gitlab Variablen unter SSH_KNOWN_HOSTS speichern. Nun hat man alles was man braucht.
Nach den Weihnachtstagen frage ich mich immer, warum viele Menschen so viel gegen Sicherheit haben? Auf der einen Seite halten sie schon das Lastschriftverfahren für zu unsicher, als dass man es verwenden könnte (man kann Amazon ja nicht trauen...) und Homebanking wird in deren Vorstellungen ja auch dauernd gehackt, ohne dass der Benutzer was dafür kann. Das ganze Internet gilt als unsicher und gefährlich. Am liebsten würden sie es gar nicht nutzen... das einzige was diese Menschen noch viel weniger nutzen möchten und als noch viel schlimmer als das Internet ansehen sind Sicherheitsmaßnahmen.
Ich habe früher gelernt, dass man auf Geld, Schlüssel und Ausweispapiere gut aufpassen soll. Wenn du deinen Schlüssel verlierst, sollte man das Schloss auswechseln, weil es könnte sein, dass jemand herausfindet zu welchen Haus der Schlüssel gehört und dort einbricht. Das hab von den selben Menschen gelernt, die
einen doof angucken, wenn man denen erzählt, dass es nicht gut ist PIN und Karte zusammen in der Brieftasche aufzubewahren. "Ich merk mir doch nicht noch einen PIN" (also einen zweiten... bei zwei Karten) kommt dann als Antwort. Dass man damit sich und sein Geld schützt, ist oft nicht wirklich rüber zu bringen. PINs sind eine Gängelung des Kunden durch die Banken. Er wird nur gesehen, dass die Banken einen zwingen einen PIN auswendig zu lernen. Der Sinn und Zweck dahinter wird oft nicht mal versucht zu erfassen. Wobei momentan EC-Karten bei vielen sowie so als absolut unsicher gelten, seit man damit kontaktlos bezahlen kann. Da muss ja nur jemand in der Nähe sein und schon ist das eigene Bankkonto leer geräumt. Also auf jeden Fall solche Schutzhüllen für die Karten kaufen. Auch für alte Karten, die gar kein NFC/RFID können, weil man kann sich nicht sicher sein, dass nicht doch jemand es mit so einem Lesegerät hinbekommt, das Konto leer zu räumen. Kontaktloses Bezahlen ist also kein extra implementiertes Feature sondern eine Sicherheitslücke die in einigen Karten vorkommt (und man kann sich nicht sicher sein ob man betroffen ist).
Aber eines der schlimmsten Dinge, die in den letzten Monaten passiert ist und viele Menschen wirklich extrem geschockt hat und den Glauben an die Sicherheit der Banking-System hat verlieren lassen, war PSD2. Viele trauen sich nicht mehr Homebanking zu benutzen oder sind gar nicht mehr in der Lage dazu... weil eine zusätzliche Sicherheitsabfrage beim Login auftaucht. Wie schaltet man das ab? - Garnicht? Weil es gut ist, dass man eine 2-factor Auth auch beim Banking hat?
Allein die Abschaffung der TAN-Listen (ich war eher gesagt geschockt, dass einige Banken, die immer noch hatten) war hart. SMS-TAN ging irgendwie noch, auch wenn dem Handy (nicht Smartphone!) auch nicht wirklich getraut wurde. TANs die nicht festgeschrieben sind und geklaut werden können... denen kann man nicht trauen. Aber wenn dann noch SMS-TAN abgeschafft wird (weil SMS-Nachrichten eben nicht verschlüsselt sind) kommen viele an den Punkt, wo für die Homebanking absolut nicht mehr nutzbar wird. Foto-TAN oder noch viel schlimmer eine Smartphone-App mit Push-Benachrichtigung und Fingerabdruckscanner.
Da ist das Vertrauen dann ganz weg. Die Lösungen sind nicht komplizierter zu nutzen (teilweise sogar einfacher), ihnen wird nur nicht mehr getraut und deswegen werden sie nicht mehr benutzt. Je sicherer etwas wird, desto unverständlicher ist es für die meisten und desto größer auch die instinktive Ablehnung dagegen.
Die beste Lösung für viele war die einfache TAN-Liste. iTAN war schon etwas seltsam... weil vorher weiß die Bank (die die Liste gedruckt und mir zugeschickt hat) welche TAN hinter welcher Nummer auf MEINEM Zettel stehen?
Fazit: Desto sicherer ein System ist, desto mehr Menschen werden versuchen es zu meiden oder zu umgehen, weil viele Menschen unsicheren Systemen mehr vertrauen als sicheren Systemen.
Seit heute laufen die meisten meiner Homepages als Docker-Container mit Traefik als Reserve-Proxy. Es war teilweise ein sehr harter Kampf mit vielen kleinen Fehlern. Wenn man sauber von vorne anfängt sollten weniger Fehler auftreten.
Was man beachten sollte:
- Images müssen Port 80 exposen
- HTTPS-Umleitungen aus htaccess-Dateien entfernen (Traefik kümmert sich darum)
- Datenbanken über Adminer oder PHPMyAdmin initialisieren und nicht über init-Scripte
- Man braucht ein eigenes Netzwerk in Docker wie "web"
- traefik.frontend.rule und traefik.enable reichen als Tags
- man macht vieles ungesichert während des Setups, dass muss man später alles wieder absichern (die Traefik-UI/API!)
- Immer Versionen für die Images angeben und nie LATEST (sonst hat man plötzlich neue Probleme)
Ich habe noch Traefik 1.7 laufen, aber das funktioniert so weit sehr gut und es gibt viele Hilfen. Für 2.0 gibt noch nicht so viele Hilfen und Beispiele. Für jeden Container habe ich auch ein eigenes Dockerfile, damit man da kleine Modifikationen an den Images machen (auch wenn es nur mal zum Testen ist).
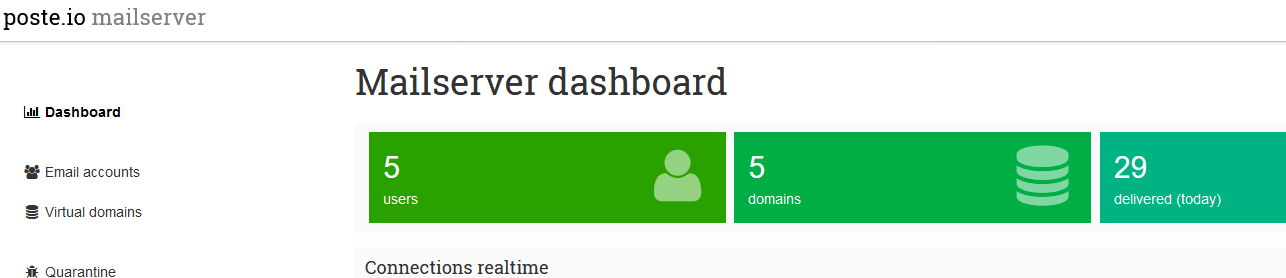
Emails laufen nun alle über poste.io der unabhängig von Traefik läuft und einen eigenen Port für die Web-UI nutzt. Das Setup ging schneller und läuft schon seit einigen Wochen extrem stabil und filtert Spam sehr viel besser als meine vorherige selbst gebaute Lösung.
Older posts:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von