Mal ein kleines Beispiel wie man Closures im
Zend Framework 2 zusammen mit dem TableGateway verwendet.
Die meisten Beispiele nutzen leider nicht die Möglichkeit Objekte in der Function zu nutzen, die außerhalb erzeugt wurden. Dabei ist das eigentlich ja das spannende daran und nur ein "Order By" ist ja in den seltensten Fällen allein was man möchte.
Also hier ein kleines Beispiel, um direkt dazu zu kommen. Man achte auf das Schlüsselwort use.
if($test!=null && $test->getId()>0){
$rset = $this->select(
function (Select $select) use ($test) {
$select->where->equalTo('test_id',$category->getId());
$select->where->lessThan('test_date','CURRENT_DATETIME');
$select->order('test_date DESC')->limit(20,0);
}
);
}
Die Klasse leitet von TableGateway ab. Deswegen $this->select().
Ein kleines Beispiel wie man sich eine eigene Validierung für Inputs in JavaScript basteln kann. Man kann es natürlich beliebig komplex machen und es sollte auch super mit Ajax funktionieren. Nur mit nicht required Inputs habe ich so mein Problem, da ich die gerne in neutraler Farbgebung hätte, wenn nichts eingegeben ist. So wären sie momentan einfach "valid" und damit grün. Falls dort jemand eine Lösung kennt, wäre es echt toll.
<html>
<head>
<style type="text/css">
input:valid{
border-color:#00FF00;
}
input:invalid {
box-shadow: none;
border-color:#FF0000;
}
</style>
</head>
<body>
<label>Test (should be 'allo')</label> <input id="blubb" type="text" required/>
<script type="text/javascript">
var func=function(){
var el=document.getElementById("blubb");
if(el.value=="allo"){
el.setCustomValidity("");
}
else{
el.setCustomValidity("value is not allowed");
}
}
document.getElementById("blubb").onchange=func;
</script>
</body>
</html>
Privat arbeite ich ja mit Eclipse und PDT. An sich gefällt mir das auch sehr viel besser als PHPStorm. Genauso wie ich auch immer WinSCP Bitvise vorziehen würde.
Aber zurück zum Thema. Wenn man schon mit einer eigentlich auf Java ausgelegten IDE arbeitet, kommt man beim Build-System als erstes auf Apache ANT. Ich mag ANT und es funktioniert echt super.
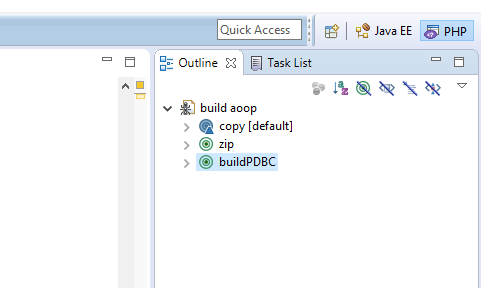
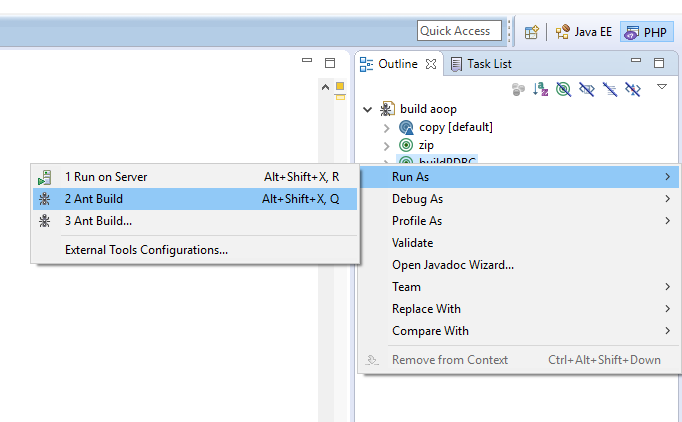
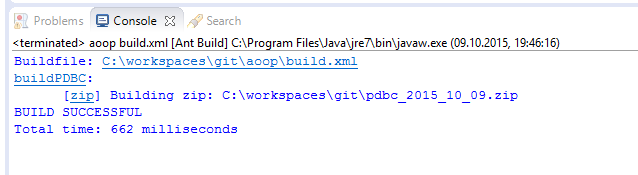
Da ich demnächst etwas über Datenbanken, Mapping und Reflections in meinem Blog verfassen will und diesmal auch direkt komplett lauffähigen Code mit liefern möchte, musste ich alles in eine Zip-Datei packen. Per Hand ist es doof, aber mit 6 Zeilen XML kann man mit ANT einfach eine Zip-Datei mit Datum im Dateinamen erstellen.
build.xml
<project name="build aoop" default="copy">
<!-- hier ist normal der Code zum Bauen von aoop.. ist hier aber uninteressant -->
<target name="buildPDBC">
<tstamp>
<format property="tstamped-file-name" pattern="yyyy_MM_dd" locale="de,DE"/>
</tstamp>
<zip destfile="../pdbc_${tstamped-file-name}.zip" basedir="system/PDBC/"/>
</target>
</project>
PS: PDBC steht für PHP DataBase Connectivity. Began vor 10 Jahren in der Berufsschule und der Name ist wie man merkt sehr an JDBC angelehnt.
Ich habe mal etwas rumgepsielt und versucht so etwas wie die Enums auf Java in PHP abzubilden. Es ist mir mehr oder weniger gut gelungen. Aber für einfache Status und Fehler-Fälle sollte es funktionieren.
<html>
<body>
<?php
class ErrorCodesEnum{
private static $instance=null;
public $code='';
public $name='';
public $message='';
public $error1 = null;
public $error2 = null;
private function __construct($code='',$name='',$message=''){
if($code!=''){
$this->code=$code;
$this->name=$name;
$this->message=$message;
}
else{
$this->error1=new ErrorCodesEnum('0001','#1','run into error 1');
$this->error2=new ErrorCodesEnum('0002','#2','run into error 2');
}
}
static public function instance(){
if(self::$instance==null){
self::$instance=new ErrorCodesEnum();
}
return self::$instance;
}
}
$test=ErrorCodesEnum::instance();
$var=$test->error1;
if($test->error1===$var){
echo '[var1] '.$test->error1->message.'<br>';
}
if($test->error2===$var){
echo '[var2] '.$test->error2->message.'<br>';
}
$test2=ErrorCodesEnum::instance();
if($test->error2===$test2->error2){
echo '[getInstance] '.$test->error2->message.'<br>';
}
?>
</body>
</html>
 bezahlt von
bezahlt von