Manchmal hat man einfach Scripts von anderen, die mit einem Fehlercode beendet werden und es ist vollkommen ok. Leider bricht bei so einem Fehler dann der Build-Process vom Docker-Image ab. Deswegen muss man den Fehlercode überschreiben.
RUN composer create-project shopware/composer-project my_shop --no-interaction --stability=dev; exit 0
Damit wird der Fehler wegen fehlender .env-Datei übergangen. Da man diese Datei an sich auch nicht braucht.
Mit Docker-Compose kann man sich einfach eine MinIO-Instanz erzeugen und auch gleich benötigte Buckets erstellen, so dass man das Erzeugen der Buckets nicht im Code der Anwendung erledigen muss.
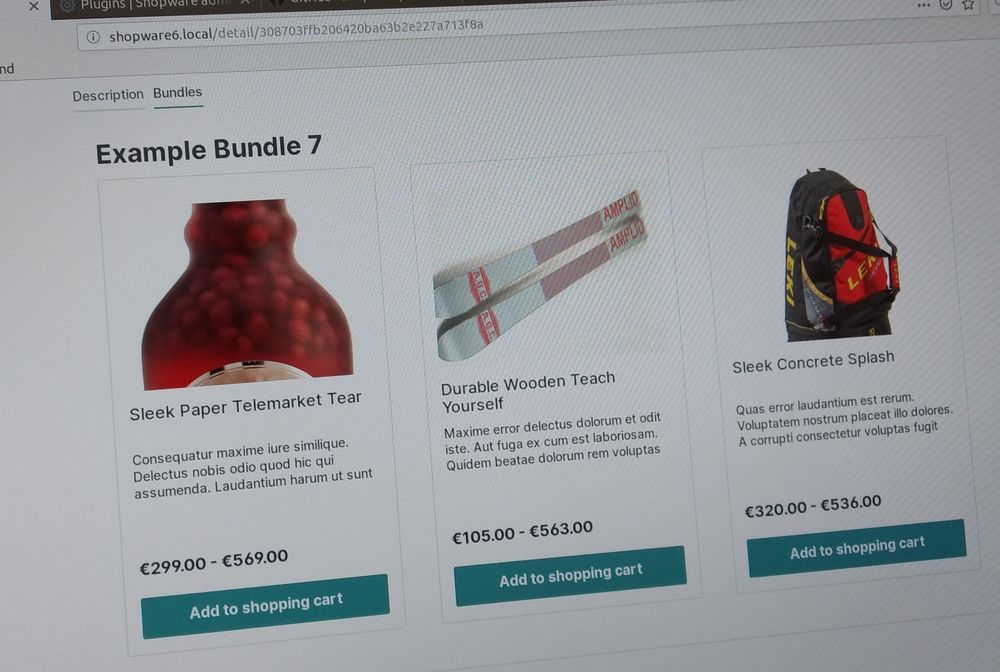
Was ich zur Plugin-Entwicklung mit Shopware 6 nach dem ersten Kennen lernen bei der Shopware AG am 1.7. zu sagen habe:
- Varianten sind nun Produkte mit Parent
- Ids in der Datenbank sind nun UUUIDs (ramsey/uuid) die binär in der DB gespeichert werden
- Ein Plugin definiert sich allein durch eine composer.json und den darin enthaltenen Typ shopware-platform-plugin (ersetzt die plugin.xml) und PSR-4 Namespace und Plugin-Class werden darin definiert
- die Metadaten zum Plugin sind in der composer.json unter extra - Changelog ist jetzte die CHANGELOG.md Datei und mit ISO-Lang Postfixes erhält man die verschiedenen Sprachen (soll wohl mal durch den Store ausgelesen werden können)
- ./bin/console plugin:create --create-config MySW6Plugin erstellt einen ein komplettes Plugin Skeleton mit Config-XML und passender composer.json
- src/Resources/views/ wird automatisch registriert (wenn man seine Views wo anders liegen hat kann man getViewPath überschreiben)
- in der Plugin-Config kann man card-Tags verwenden, um Blöcke zu bilden und alles besser strukturieren zu können
- man kann eigene Felder und View in die Plugin-Config einbringen, in dem man vor eine Vue-Component registriert hat und diese dort als <component name="MyComponent"/> angibt
- Plugin installieren: ./bin/console plugin:install --activate --clear-cache MySW6Plugin öfters ist ein refresh der Liste nötig und cache:clear sichert den liebgewonnen Workflow bei der Entwicklung mit Shopware :-)
- Es gibt kein Doctrine-ORM mehr sondern die eigene DAL die noch DBAL verwendet
- DAL ist so etwas wie ein halb fertiges ORM wo noch die Abstraktion wie Annotations fehlt und man deswegen die Beschreibung und Umwandlungen selbst per Hand vornehmen muss, so wie auch das Anlegen der DB-Tables
- Es gibt dort noch viel zu verbessern, aber das Grundgerüst funktioniert da schon sehr gut. Zu verbessern wäre z.B.: new IdField('id', 'id') auch als new IdField('id') schreiben zu können wenn DB-Column und Class-Field gleich bezeichnet sind
- die Field-Definition-Methode wird nur selten aufgerufen, deswegen kann man hier sonst auch eigene Lösungen wie CamelCase-Converter oder Annotion-Parser selbst integrieren
- Es gibt momentan immer 3 Klassen: Definition, Plain Old PHP Object und Collection (über @Method der eigenen Collection wird so etwas wie Generics versucht abzubilden... in Java wäre es nur List<MyEntity> list = ....)
- Es wir automatisch ein Repository für jede Entity erzeugt, das man mit Hilfe der service.xml injecten kann
- CLI, Subscriber, etc werden weiterhin über die service.xml verwaltet und implementieren nur andere Interfaces (sonst hat sich dort kaum was verändert)
- Es gibt keine Hooks mehr sondern nur noch Service-Decoration (wie die meisten wohl schon jetzt lieber verwendet haben) und eben die Events
- Es gibt mit der DAL ein Versions-Feld
- Änderungen an der Datenbank sollten über das Migration-System (Timestamp basiert) erledigt werden und nicht über die Lifecycle-Methoden des Plugins
- Es gibt Updates und destructive Update, die die Kompatibilität der DB zu älteren Plugin-Versionen zerstören. Beides kann getrennt ausgeführt werden (2 Phasen Update für Cluster-nodes)
- Die DAL unterstützt native Translated-Fields
- Extensions von Entities werden serialisiert in der DB gespeichert (ALTER TABLE, Extension, Serializer-Klasse, etc). Es gibt keine Attributes mehr.
- Gespeichert wird immer per Array (von Entity-Arrays) und es wird nicht das Object zum Speichern übergeben
- upsert (update or insert) ist da das neue merge - Der Cart hat nun LineItems, die wiederum Children haben können
- LineItems sind nun vollkommen unabhängig von Produkten, es gibt nur noch ein Type und Enrichment-Handler, die Namen und Preise für diesen Type an das Item ran dekorieren
- ... damit kann man verschiedene Bestell-Modi wie "kaufen" und "ausleihen" pro Produkt zusammen in einem Warenkorb abbilden
- Die API stellt automatisch generierte Swagger-Beschreibungen bereit
- Es gibt mehrere APIs so dass nicht nur Datenspflege bestrieben werden kann, sondern auch komplette Bestellprozesse damit abgebildet werden können (damit kann man Shopware als Backend-Lösung für In-App-Käufe oder POS-Systeme verwenden)
- Dadurch kann man Shopware auch headless verwenden (ohne Storefron und Admin, oder nur mit einem davon)
- ein Product aht ein SalesChannelProduct... man kann dort bestimmt auch eine Stock-Quantity hinzufügen und so einen Sales-Channel abhängigen Lagerbestand implementieren (Jeder POS auf einen Event oder in Disco könnte ein eigener Sales-Channel werden und dann kann man genau
monitoren wo Getränke oder Verbrauchsmaterial zu neige geht und reagieren bevor die Mitarbeiter überhaupt merkten, dass in 15min wohl die Strohhalme ausgehen werden)
Insgesamt macht Shopware 6 einen wirklich sauberen und durch dachten Eindruck. Nur die Migrations brauchen noch etwas und die DAL könnte gut einen weiteren Layer drum herum gebrauchen (ich wäre für Annotations an der Entity-Klasse)
Oft will man ja beim Speichern von Dateien flexibel bleiben. Beim Entwickeln lokal speichern, im Produktivsystem in S3 und auf einem alten Test-System vielleicht noch auf einem FTP-Server oder in Redis.
Jeder hat schon mal so was geschrieben um wenigstens das native Filesystem und FTP zu abstrahieren, weil der FTP-Server nur vom produktiven System aus zu erreichen war oder so. Mein PHP Framework hat auch solche Klassen. Aber ich hatte keine Lust mehr diese noch mal anzupassen und eine brauchbare Struktur mit Factory und Interfaces dort endlich mal zu implementieren... was die Klassen (2006 geschrieben) an sich dringend nötig hätten.
Deswegen habe ich mich einige Sekunden im Internet umgeguckt und Flysystem gefunden. Das kann natives FS, FTP, S3, Redis, OneDrive, Azure File Storage.... also alles was man so braucht.
Ich habe es mal mit S3 getestet. Natürlich müsste man sich erst einmal eine brauchbare Factory schreiben, aber da kann man sicher in seinem System auf die alten Strukturen zurück greifen und muss dann nicht alles umbauen, wenn man auf Flysystem wechselt.
Danach sollte auf localhost:8000 der Shop starten.. wenn eine MySQL Auth.-Method Fehlermeldung kommt hilft die Container zu beenden. In der Docker-Compose das DB-Image von dem MySQL-Image auf das MariaDB-Image zu ändern und noch mal die Container neu zustarten und ein wieder install durchführen.
Dann sollte alles laufen und man kann sich unter localhost:8000/admin mit admin - shopware anmelden.
Wenn man die lokalen psh.phar-Aufrufe durch die direkten Docker-Befehle ersetzt, sollte es auch unter Windows funktionieren. Innerhalb des Containers kann man natürlich wieder psh.phar verwenden.
Update: manchaml kann auch helfen, dieses vorher einmal auszuführen, bevor man den Container startet und dort install aufruft:
Amazon S3 ist ein einfacher Key-Value Store, wo man auch sehr große Daten unterbringen kann. Gerade wenn man Dateien nicht auf dem selben Server speichern möchte oder ein Cluster betreiben will, ist S3 eine gute Alternative zu FTP oder NFS-Laufwerken. Der Server ist über HTTP zu erreichen und es gibt für alle möglichen Sprachen Clients. Eine S3 kompatible Implementierung ist MinIO. Ich hab hier ein kleines Beispiel gebaut, wo ich ein Bild hochlade und wieder downloade und danach alles auch wieder aufräume. Metadata habe ich auch genutzt. Wenn man komplexere Anwendungen hat wird man wohl eher nicht SaveAs verwenden sondern den mitgelieferten Stream aus dem Array verwenden.
Das Minio Docker-Image:
sudo docker pull minio/minio
sudo docker run -p 9080:9000 -e "MINIO_ACCESS_KEY=AKIAIOSFODNN7EXAMPLE" -e "MINIO_SECRET_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY" minio/minio server /data
Manchmal braucht man einfach schnell ein Mapping zwischen Dateierweiterung und Mime-Type. Besonders wenn man beliebige Dateien über eine Schnittstelle zum Download anbietet und diese aus einen FileStorage kommen oder diese dynamisch erzeugt werden. Für PHP gibt es Mimey, das einen da schnell und einfach hilft.
Sehr praktisch... durch ältere Projekte, die so etwas selber machen, sollte man sich wirklich mal durch kämpfen und dadurch ersetzen.
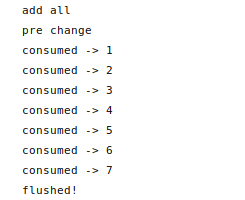
Eine Art von Queue, wo viele Items drin abgelegt werden können, aber erst wenn alle Items valide sind, alle auf einmal verarbeitet werden. Es werden Proxies benutzt, um auf Änderungen an den Items reagieren zu können. Ein hinzu gefügtes Item kann also an eine async Function weiter gereicht werden und wenn dort das Item geändert wird, wird direkt wieder versucht die Queue zu flushen.
Man muss drei Functions mit geben: Validator zum prüfen der einzelnen Items, Cosumer zum Verarbeiten der einzelnen Items und onEmpty, die ausgeführt wird, wenn der Flush durch ist.
let flushQueue = {
items: [],
getChangeHandler: function(service){
return {
set: (obj, prop, newval) => {
obj[prop] = newval;
service.consume(false);
}
}
},
consumer: null, //user function
onEmpty: null, //user function
validator: null, //user function
validate: function() {
let result = true;
this.items.forEach((item) => {
if(!this.validator(item)) {
console.log(item);
result = false;
}
});
return result && this.items.length > 0;
},
consume: function(tested) {
if(tested || this.validate()) {
var item = this.items.shift();
if(this.consumer){
try{
this.consumer(item);
}
catch(e){
}
}
if(this.items.length > 0) {
this.consume(true);
}
else if(item && this.onEmpty) {
this.onEmpty();
}
}
},
add: function(itemIn) {
let item = new Proxy(itemIn, this.getChangeHandler(this));
this.items.push(item);
this.consume(false);
return item;
},
addAll: function(items) {
let out = [];
items.forEach((itemIn, key) => {
let item = new Proxy(itemIn, this.getChangeHandler(this));
this.items.push(item);
out[key] = item;
});
this.consume(false);
return out;
}
};
In letzter Zeit nehmen leider schlimme Dinge wie Sprachnachrichten und Videoanrufe über Whatsapp zu. Auch Menschen von denen man weiß, dass sie eigentlich lesen und schreiben können, scheinen eben dieses zu verlernen... Ähmm ja.. Eigentlich geht es mir darum, dass diese Art von Nachrichten für mich fast immer sehr unpraktisch und eher nervig sind als einen Mehrwert darzustellen. Deswegen hier einmal kurz, warum ich Textnachrichten vorziehe:
Sprachnachrichten sind unpraktisch, weil... - sie mehr vom Datenvolumen verbrauchen als Textnachrichten und das ist in Deutschland immer sehr begrenzt oder sehr teuer
- sie die Umgebung belästigen, weil ich sie mir laut anhören muss und vielleicht nicht möchte, dass alle in der Umgebung mithören oder sich da druch gestört fühlen
- sie sind teilweise schlecht zu verstehen, also müsste ich sie lauter machen (siehe Punkt 2) oder muss mit Stellen 2 mal anhören, was mit der kleinen Timeline und Touchbedienung, gar nicht so einfach ist, die richtige Stelle mehr mal zu treffen
- sie bei schlechten Netz teilweise nicht übertragen werden können
Sprachnachrichten sind ok, wenn... - ich wirklich eine Audioaufnahme von etwas teilen möchte
- wenn ich Auto fahre, aber dann geht auch Sprachsteuerung und vorlesen lassen
Videoanrufe sind unpraktisch, weil... - sie sofort angenommen werden müssen und ich meistens (gerade bei der Arbeit) keine Zeit dafür habe
- ich sie nicht später beantworten kann (bei Sprachnachrichten geht das ja noch)
- ich nicht voll multitasking mässig mit mehreren gleichzeitig kommunizieren kann
Videoanrufe sind ok, wenn... - wenn ich zum Beispiel bei handwerklichen Dingen Echtzeit-Hilfe brauche und die andere Person es sehen muss während ich etwas mache
- ...für private Dinge...
- Für alte Leute, weil es wie Telefonieren ist und ältere Menschen mit asynchroner Kommunikation überfordert sind.. sie wollen immer sofort antworten und auch sofort Reaktionen haben bei der Kommunikation
Mal wieder kam eine Bestellbestätigung von HD+ an. Selbes Schema, wie das letzte mal. Wirklich toll ist, dass die letzten Male sogar eine Email mit dem SEPA-Mandat mitgeschickt wurde, weil damit lässt sich sehr genau sagen, welche Daten von einem von jemanden Missbraucht werden und welche nicht. Daher kann ich jetzt schon mal sagen, dass jemand wohl regelmäßig meine Email-Adresse für Bestellungen verwendet, aber immer mit anderen Bankdaten kombiniert. Das ist an sich nicht sehr klug von dieser Person, da so Unregelmäßigkeiten schnell zu finden sein sollten. Eine Email-Adresse mit verschiedenen Kontodaten sollte sich per SQL schnell finden lassen.
Diesmal habe ich eine Email geschrieben und auch, um die Rücknahme der Bestellung gebeten. Mal gucken wie die reagieren werden.
Die Kontodaten stammen diesmal von der VR GenoBank DonauWald eG... also irgendwo aus Bayern.
Edit: HD+ hat mir geraten bei der Polizei Anzeige gegen Unbekannt zu erstatten.
Agil arbeiten ist voll in und jeder will es machen. Klingt eben cool, wenn man sagen kann, dass man Scrum macht und UserStories entwirft und danach arbeitet. Leider ist agiles Arbeiten nichts, was man den Mitarbeitern einfach mal vorschreiben kann und es dann auch so in Zukunft läuft. Agil ist viel mehr als ein Whiteboard mit ToDos und Sprints mit 2 Wochen Laufzeit, wo am Ende es Sprints alles fertig ist, was man an das Board geklebt hat.
Wenn man wirklich agil arbeiten will, muss man erst einmal sich um die Hierarchie kümmern, weil diese agilen Arbeiten meistens im Weg steht. Wer so arbeitet, dass Aufgaben durch 3-4 Schichten von Oben nach Unten herunter gereicht werden und jeder nur die Infos bekommt, die er gerade braucht, wird das ganze Vorhaben scheitern. Wichtig beim agilen Arbeiten ist, dass die Mitarbeiter, die es umsetzen sollen, auch vollumfänglich informiert sind und nicht nur das wissen, was in dem aktuellen Sprint umgesetzt werden sollen.
Oft läuft es so das der Chef seine Idee mit dem Abteilungsleiter bespricht, der guckt was zu machen ist und stimmt sich mit dem Teamleiter/Scrummaster ab was in einem Sprint abgearbeitet werden soll. Die Mitarbeiter dürfen dann noch mal die Aufwände schätzen für das was sie in der Zeit erledigen sollen. Meistens müssen, dann die Aufwände aber dann auch so geschätzt werden, dass es passt, weil der Inhalt des Sprints ja schon fest gelegt wird. Was im Backlog für die nächsten Sprints steht, wird oft nicht mitgeteilt. Damit wird den Mitarbeitern aber die Möglichkeit genommen schon mal Erkenntnisse und konkretes Wissen für die Zukunft zu sammeln. Weil.. man ist ja agil und wenn sich die Arbeit des Sprints leider als nicht zukunftssicher heraus stellt, macht man es eben nochmal. Aber Hauptsache man wird am Sprintende mit den Aufgaben fertig.
Im Grunde kennt man dieses Vorgehen schon lange. Man bekommt die Anforderungen diktiert, dann werden diese umgesetzt und am Ende wird geguckt, ob es das ist was man haben wollte. Wenn nicht fängt man wieder von vorne an. Das ist das klassische Wasserfall-Model.
Nur eben auf 2 Wochen herunter gebrochen. Das ist nicht Agil. Man blickt nicht über den Tellerrand und passt sich ändernden Anforderungen an. Wenn sich mitten drin was ändert wird es oft nicht mitgeteilt, wenn dann heißt es man müsse das Sprintziel um jeden Preis erreichen und im nächsten Sprint würde man es eben dann nochmal machen.
Planung und Konzeption wird weiterhin von der "Führungsebene" gemacht. Die Mitarbeiter arbeiten nur wieder stur nach Vorgaben ihre ToDos ab. Sollte ein ToDo in der Umsetzung nicht genau spezifiziert sein, kann dieses nicht bearbeitet werden. Ein Konzept kann sich nicht mit der Zeit entwickeln, weil es kein Feedback über Erkenntnisse und neue Erfahrungen gibt.
Hier ist aber nicht nur die "Führungsebene" schuld, sondern oft auch Mitarbeiter, die viel lieber nach festen Vorgaben arbeiten und nicht selbst die Lösung für das Problem entwickeln wollen. Die Verantwortung für ein Produkt wird da immer noch nach oben gereicht, weil der Mitarbeiter führt ja nur aus.
Wie macht man es besser. Man braucht eine direkte und vollständige Kommunikation über alle Grenzen hinweg. Die Vision muss allen klar sein und jeder muss auch bereit sein diese selbstverantwortlich um zu setzen. Jeder soll eine Lösung vorschlagen können. Bei klaren Anforderungen muss auch nicht jeder Pups besprochen werden, weil jeder ja daran interessiert ist, das Produkt fertig zu stellen, wird auch jeder die seiner Ansicht nach beste Lösung implementieren. Und wenn man ehrlich ist, kann jede andere Lösung genau so "richtig" oder "falsch" sein, wie die andere. Zu viel diskutieren bringt am Ende nichts, lieber machen und ausprobieren.
Niemand wird dir das Denken dabei abnehmen. Immer mit denken und den Denkprozess und die Entscheidungen dazu immer dicht man Entwicklungsprozess halten. Bei den Meetings können Vorschläge gemacht werden, aber diese sind nicht in Stein gemeißelt sondern wie gesagt nur Vorschläge und mögliche Lösungen. Wenn es sich auf halben Wege heraus stellt, dass es nicht so geht.. abbrechen und direkt neu anfangen. Ein Sprintziel ist nie wichtiger als das Produkt. Was bringt es ein Feature zu Ende zu implementieren, wenn die Implementierung sowie so
wieder verworfen wird? Nichts.. es verbraucht nur Zeit und Kunden könnten glauben, es würde doch schon fertig sein. Wenn man etwas macht, dann richtig und dafür darf man keine Angst haben mal was aus zu probieren und dann mit dem Versuch auch zu scheitern.
Retrospektiven und Meetings sind wichtig, weil da keine nach unten gerichtete Kommunikation stattfindet, sondern alle auf Augenhöhe mit einander reden können. Auf von "unten" muss klar kommuniziert werden, was und wie viel man schafft und schaffen will. Ein Sprint ist kein Zeitraum wo man möglichst viele Aufgaben reindrückt und am Ende Crunchtime erzeugt, damit das Sprintziel auf jeden Fall erreicht wird. Lieber weniger einplanen und dem Sprintende entspannt und zufrieden entgegen sehen. Lieber die Zeit nutzen um Lösungen zu entwickeln und geplante ToDos noch mals zu analysieren und schon mal etwas auszuarbeiten.
Viele leben aber noch zu sehr in ihrer hierarchischen Wasserfall-Welt, wo Kommunikation nur in eine Richtung geht, nur konkrete Ausgaben kommuniziert werden und ein Sprint ein Timeslot ist, in dem man möglichst viel Arbeit erledigt haben will und das Sprintende eher drohend sein soll und nicht erwartet werden soll.
Agil bedeutet für mich, dass Informationen in alle Richtungen fließen und einen beim Denken und Lösungen finden immer zur Verfügung stehen. Agil ist, wenn man schnell austestet, schnell scheitert und schnell mit der mehr Erfahrung von neuen beginnen kann. Wo man neue Fehler machen kann um so zu neuen Lösungen zu kommen. Und für all dieses übernehme ich dann auch gerne die Verantwortung
Subscriber bei Shopware-Plugins sind immer so ein Problem. Sie nehmen Daten manipulieren diese und reichen sie an den nächsten Subscriber weiter. Wenn ein Subscriber in einen Fehler läuft und z.B. leere Daten in die Arguments zurück schreibt, ist am Ende alles kaputt und die Daten sind verloren gegangen. Das ist mir jetzt einmal passiert und deswegen, bin ich darauf umgeschrieben, dass Subscriber nur noch auf einer Kopie arbeiten
dürfen.
Sollte nun etwas schief gehen und die Daten verloren gehen, werden einfach die Ursprungsdaten weiter verwendet. Wenn nun zusätzliche Daten nicht dazu dekoriert werden, ist es zwar doof und man muss in das Log-File gucken, ob Fehler auftraten, aber der Ablauf funktioniert weiter und es kommen immer hin die Grunddaten weiter dort an wo sie hin sollen.
Gerade bei Exports oder Imports mit kritischen und unkritischen Daten zusammen, ist es immer besser wenigstens die kritischen Daten sicher zu haben als gar nichts zu haben. Unkritische Daten kann man meistens dann sogar per Hand nachpflegen.
HD+ Kunden, die sich ein neues Programmpaket bestellen, gehen oft nach einem bestimmten Muster vor. Sie geben eine beliebige Email-Adresse (bestimmt geht auch eine nicht existente und rein ausgedachte Email-Adresse) und dann geben sie eine beliebige Bankverbindung ein. Mehr Daten braucht man da wohl auch nicht. Dann bekommt vielleicht jemand eine Rechnung (in diesem Fall ich) und irgendwer muss bezahlen (in diesem Fall jemand auf Koblenz).
Wenn man sich als Rechnungsempfänger da meldet, interessiert es da keinen, weil ja hoffentlich der 2. dumme es nicht merkt und die Rechnung bezahlt.
Da ich schon mehrmals mit genau dem selben Vorgang bei HD+ als Rechnungsempfänger zu tun hatte, scheint es da wirklich System zu haben. Leider gibt HD+ an der Hotline auch direkt an, daran nichts ändern zu wollen.
Ich bin gespannt, wann die nächste Email bei mir aufläuft.
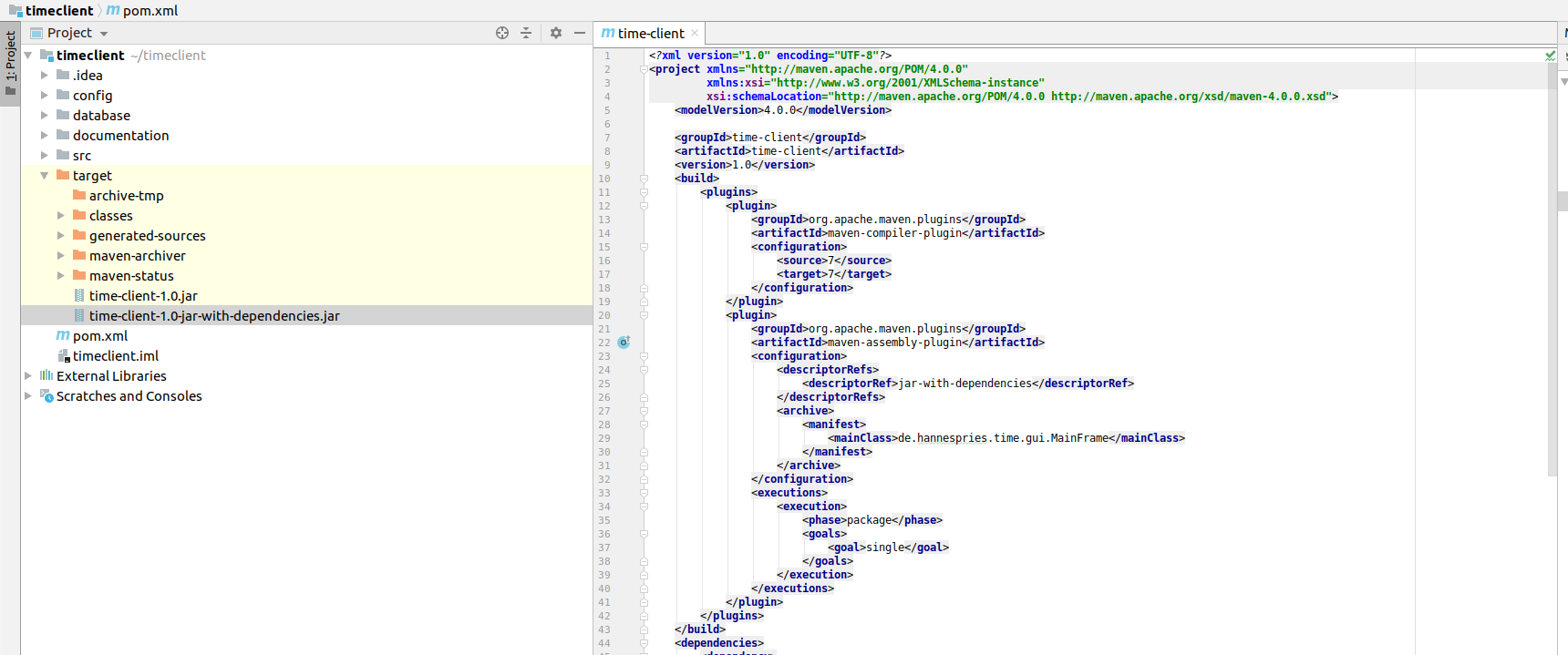
Manchmal ist es echt unpraktisch viele kleine JAR-Dateien zu haben und man hätte gerne alles in einer großen. Keine Class-Path Probleme mehr, einfaches Deployen und ein Single-Point-Of-Failure.
Mit Maven geht das zum Glück sehr einfach. Spring Boot und Meecrowave haben eigene Plugins mit denen man auch sehr gut arbeiten kann und die dem Beispiel hier vorzuziehen sind.
 bezahlt von
bezahlt von