Der einfachste Weg einen Shopware Shop zuinstallieren war immer, die ZIP-Datei mit dem Webinstaller downzuloaden und diese in das gewünschte Verzeichnis zu entpacken. Dann die URL aufrufen und dem Installer folgen. Das ist für automatische Deployments nicht so toll und oft wurde dort einfach die Git-Version verwendet. Die hat den extremen Nachteil, dass diese unglaublich viele Dinge mitbringt, die in einer produktiven Umgebung nichts zu suchen haben. Buildscripte, Tests, etc bringen einen wirklich nur in der Dev-Umgebung was und sollten in der produktiven Umgebung nicht mit rumliegen, weil je mehr rumliegt, desto mehr Sicherheitslücken oder ungewollte Probleme könnten mitkommen.
Seit einiger Zeit kann man Shopware aber auch sehr einfach über den Composer installieren. Dabei wird eine eher moderne Verzeichnisstruktur angelegt und auch die Basis-Konfiguration kann einfach über Env-Variablen gesetzt werden, so dass ein automatisches Deployment für einen Server damit sehr einfach wird. Im Idealfall hat man die Datenbank schon sauber und fertig vorliegen. Dann erspart man sich fast den gesamten Installationsprozess und kann direkt loslegen.
Wenn man den Composer noch nicht installiert hat, muss man diesen kurz installieren:
<Directory /var/www/your_webshop>
AllowOverride All
Require all granted
</Directory>
RewriteEngine On
</Virtualhost>
Reload des Apache und schon kann es an sich losgehen. Wenn man sehen möchte wie die DATABASE_URL verarbeitet wird, kann man einen Blick in die etwas komplexer gewordene config.php werfen die man nun unter your_webshop/app/config/config.php findet.
Sollte man noch keine fertige Datenbank auf dem Server liegen haben, muss man die ./app/bin/install.sh ausführen. Gerade für mehrere automatische Deployments, würde ich aber die Datenbank einmal local auf meiner Workstation anlegen und mit Default-Werten befüllen. Diese kommt dann auf den Datebankserver und wird beim deployment, mit den spezifischen Daten wie den Shopdaten und Admin-Zugängen versehen.
Natürlich würden Updates auch über den Composer laufen, wobei sw:migration:migrate automatisch mit aufgerufen wird, um die Datenbank mit aktuell zu halten. Das Verhalten kann man über die Deaktivierung des entsprechenden Hooks in der composer.json verhindern (aber das macht an sich nur in Cluster-Umgebungen Sinn). Ein Update über das Webinstaller-Plugin würde Probleme bereiten und sollte, wenn man es dann ,z.B. weil man eine alte Installation umgezogen hat, installiert und aktiv hat mit ./bin/console sw:plugin:uninstall SwagUpdate entfernen.
Der wirkliche Vorteil liegt jetzt darin, dass man in die composer.json seine Git-Repositories von den Plugins mit eintragen kann und die Plugins direkt über den Composer installieren und updaten kann. Man muss also nicht diese erst vom Server downloaden + entpacken oder per Git clonen (wo dann wieder viel Overhead mit rüber kommen würde).
Ich habe mir direkt den SNES Mini gekauft. Der NES Mini hat mich weniger angesprochen. Aber für den SNES hatte ich einen wirklichen Grund ihn zu kaufen: Die Spiele als Modul einzeln zu kaufen wäre einfach unglaublich teuer gewesen. Auch war Star Fox 2 in einer offiziellen Version dabei und nicht nur als ROM mit unklarer Herkunft.
Mario-Kart + Probotecotr/Contra allein hätten sicher schon das selbe gekostet wie die kleine Konsole. Turtles in Time wäre natürlich echt super gewesen, aber auch ohne hat sich der Kauf einfach gelohnt.
Beim Mega Drive Mini sieht es anders aus. Ich werde mir die Konsole nicht kaufen, da ich die meistens Spiele schon habe oder aber für sehr wenig Geld auch so bekomme. Da kann ich mich dem Gamersglobal-Artikel voll anschließen. Ich habe die meistens Spiele wie Light Crusader, Sonic, Golden Axe und Comix Zone auch wenn ich mit für die Switch Sega Mega Drive Classics kaufe und das für unter 20 Euro.
Wenn man keinen Mega Drive hat und etwas in der Optik haben will, kann sich der Kauf lohnen. Wenn man schon einen hat, dazu ein Module aus China mit > 100 Spielen und noch die Classics Collection für die Switch, lohnt es sich einfach nicht und die 3 Dinge zusammen sollte man auch zu dem Preis der Mini bekommen können.
Ein Update auf 5.6 ist schnell und einfach gemacht. Alle Tests liefen super und es sah nach einer 2 Minuten Aktion aus... dann kam das SwagPaymentPaypal und nutzte Shopware::VERSION. Um genau zu sein in der Bootstrap.php in Zeile 146. Das gibt es in 5.6 aber nicht mehr und deswegen lief dann auch gar nichts mehr. Das Plugin lies sich auch nicht deaktivieren.
Wer also das Plugin noch nutzt sollte es unbedingt durch SwagPaymentPayPalUnified ersetzen. Das alte muss deinstalliert werden, weil die selben Config-Namen verwendet werden.
Wer das alte noch hat und in das selbe Problem läuft, muss dann leider die Zeile 146 per Hand ändern. In etwas wie das hier:
if (false) {
Darin wird etwas für Shopware < 4.2.0 gemacht, was wir mit 5.6 eindeutig nicht mehr brauchen.
Manchmal braucht man schnell und einfach einen HTTPS-Server um z.B. eine App auszuliefern, die auf die Kamera des PC oder Smartphones per WebRTC zugreift. Das geht an sich ganz einfach wenn man weiß, was man alles braucht.
Damit hat man direkt einen HTTPS-Server bei dem man nur noch das unsichere Zertifikat akzeptieren muss.
Wenn man Windows verwendet muss man über die Bash (WSL) OpenSSL, NodeJS und NPM installieren und dann ist es wie unter Linux.. man befindet sich dann ja auch in einem Linux....
Zeit für das Sommerloch in meinem Blog. Die Wärme, das Haus und alles mögliche benötigen gerade sehr viel Zeit, deswegen gibt es diesmal auch etwas für die Freizeit bevor es dann später wieder mit eher technischen Blog-Posts weiter geht.
Nach dem ich mir letztes Jahr eine günstige Drohne aus China geleistet habe und diese nach ganzen 5 Minuten Flug auch unglaublich warm wurde und sich dann entschied gar nicht mehr an zugehen, war es dieses Jahr mal Zeit für ein etwas besserer Drohne. Ich hatte jetzt nicht vor wirklich viel damit zu machen, weil mir da auch einfach die Zeit und die Ideen gerade fehlen.
Deswegen hielt ich eine günstige Marken-Drohne einfach für viel zu teuer. 300-400 Euro um da mal bei meinen Eltern auf dem Dorf etwas rum zu fliegen und Orte meiner Kindheit und Jugend mal von oben zu sehen sind einfach doch zu viel, gerade wenn man das Geld auch in das Haus oder eine Nintendo Switch investieren kann. Meine wundervolle Ehefrau schenkte mir dann zu Weihnachten eine Ryze Tello Drohne. Diese soll auf DJI und Intel Technoligie aufbauen, aber deckt eine Zielgruppe als die normalen DJI-Drohnen ab. Mit knapp 100 EUR auch wirklich günstig. Es ist mehr ein Spielzeug mit einer brauchbaren kleinen Kamera und es gibt ein SDK, falls man sich auch mal mit der Programmierung der Drohne beschäftigen möchte. Die Drohne ist natürlich auch eher klein und leicht.
Sie kann einen ruhig auf den Kopf fallen ohne dass man Angst vor Verletzungen haben muss und deswegen auch rechtlich einfacher ist als teurere und schwerere Drohnen.
Aber erst einmal zur Ausstattung. Es gibt die Drohne, einen Akku und ein Micro-USB Kabel. Mehr nicht. Die Steuerung geschieht über das Smartphone per WLAN und App. Man soll auch Game-Controller verwenden können aber da war ich jetzt weniger motiviert das auszuprobieren. Ich habe das USB-Kabel durch ein altes Netzteil des Samsung Wave 1 (das mit OLED und Bada 2.1!) ersetzt und erst einmal den Akku lange geladen. Der Akku lädt lange und soll dann so 10-15min halten. Ich kann 5-10 Minuten bestätigen. Danach muss man wieder laaaaange laden. Also wer die Drohne auf einen Ausflug oder einen Besuch mitnehmen möchte, sollte sich ein paar Zusatzakkus und vielleicht ein zusätzliches Ladegerät dazu kaufen. Günstige Drohne aber das Zubehör ist mehr als optional!
Die App kann sich einfach über den Playstore installieren und das Smartphone verbindet sich schnell mit dem WLAN der Drohne. Alles ganz einfach. Dann kam der Start. Die alte und jetzt defekte China-Drohne machte viel Krach, stieg auf, eierte rum bis sie sich stabilisierte und flog dann recht schwerfällig und ungenau. Die Tell-Drohne wartete auf den Start-Befehl, stieg gerade nach oben und hielt sich stabil in der Luft. Die Steuerung ist auch auf dem Touchscreen sehr gut, so dass man Drehen und Bewegen mit beiden Daumen gut koordinieren kann.
Wenn man die Drohne einmal ausgerichtet hat, bleibt sie stabil, wobei bei meinen Tests jetzt nicht so viel Wind war.
Fotos kann man über eine Taste machen und sie werden als PNG direkt auf dem Smartphone gespeichert. Belichtung ist bei der Drohne nicht immer ideal, falls Licht und Schatten zu höheren Kontrasten führen. Da muss man etwas durch die Ausrichtung ausgleichen, wie man es auch von der Smartphone Kamera-App gewohnt ist. Die Bildqualität ist natürlich im Vergleich zu einem guten Smartphone oder eine DSLR eher bescheiden, aber die Schärfe und die Farben sind soweit OK, dass man die Bilder für das Web oder Dokumentationen gut gebrauchen kann. Für Aufnahmen von Ferienhäusern und Grundstücken bei EBay-Kleinanzeigen oder kleinen Events reicht die Qualität alle mal und mit etwas Nachbearbeitung sind die Fotos auch für das Fotoalbum/-Verzeichnis ausreichend.
Die Verzeichnungen an den Rändern sind da, aber für den Weitwinkel bei dem kleinen Objektiv noch recht gering.
Die Videoqualität mit 720p war jetzt nicht so wirklich berauschend. Wenn sie die Drohne bewegt, ist das Video sehr unruhig und wabbert oft etwas hin und her.
Laden ist super damit. Man fliegt den Landepunkt an bis die Drohne nicht mehr weiter runter will. Dann drückt man auf den "Landen"-Knopf und sie landet und schaltet sich ab. Die China-Drohne machte einfach immer eine Bruchlandung.
Aber für den Preis und für den privaten Gebrauch ist die Drohne wirklich sehr spaßig. SDK und EZ-Shot klingen sehr interessant und das Zweite werde ich sicher noch mal ausprobieren. Ich hoffe, dass ich auch insgesamt noch mal mehr Zeit finde mich damit zu beschäftigen :-)
Es kann dazu kommen, dass beim Aufruf der console von Shopware 5 keine kernel.environment gesetzt ist. Bei Webserver Aufrufen wird diese ja zumeist in der conf des Apache gesetzt.
Um jetzt die Environment (z.B. "production") direkt beim Aufruf der console zu setzen muss man die Option "e" setzen und schon geht alles.
Jeder kennt es sicher. Man baut eine Webanwendung, mit ein wenig HTML5, ein wenig JavaScript und was sonst so an CSS und SVG dazugehört. Firefox ist glücklich, Chrome natürlich auch und sogar Safari beschwert sich nicht. Man hat alles geschafft und und will in den Feierabend gehen. Die Sonne lacht, die Laune ist gut und draußen brüllen die Vögel. Man will gerade den PC in den Energiesparmodus versetzen und aufstehen da zieht eine leichte kühle Brise auf. Der Himmel wird dunkel und der Atmen kondensiert direkt vor einem.. Gänsehaut und alle Haare stellen sich auf. Der Geruch von Tod und Verwesung steigen einen in die Nase. Raben krächzen aufgeregt von ihren Plätzen (es ist immer ein Fehler sich ein Büro mit Raben zu teilen....). Das ungute Gefühl übernimmt die Oberhand. Das Ticket des Grauens ploppt auf. Schon der Titel verrät, dass der schlimmste anzunehmende Unfall geschehen ist. Es kommt von der typischen Art von Mitarbeitern, die aus versehen mal einen Dämon beschwören oder das Tor zur Hölle öffnen. Diesmal ist es nur ein Zombie. Gut nicht einfach ein Zombie. Es ist wieder der Zombie, der jedes mal auftaucht in solchen Situationen. Nervig, man mag ihn auch nicht einfach weg schicken. Es ist die Art von Zombie, die in dein Haus eindringen wollen und, obwohl du schon alle Türen offen gelassen hast, immer nur gegen die Außenwand rennt. Um dein Haus hat sich schon eine Traube anderer Zombies gebildet, die dem einen dummen Zombie nur ungläubig dabei zu gucken, wie er immer und immer wieder gegen die Wand rennt.
"Mit dem Internet Explorer geht das nicht...". Du versuchst am Verwesungsgeruch fest zustellen, ob es der IE11 ist oder der Mitarbeiter eine noch ältere Version ausgebuddelt hat. Es ist nur der IE11, aber trotzdem würde ein Surströmming-Deo seinen Geruch schon ungemein verbessern.
Es bleibt nur eins übrig: Den Zombie verscheuchen, dem Mitarbeiter mitteilen, dass man sich morgen gleich als Erstes darum kümmern wird und sich einreden, dass Menschen die noch einen Internet Explorer benutzen es auch verdient haben in Probleme zu laufen.
Jeder der ein Plugin verwendet, das viele Daten hin und her schaufelt und dieses auch immer protokolliert, kennt das Problem von zu großen Log-Files. Gerne hätte man schon immer Log-Files für bestimmte Anwendungsfälle geschrieben. Mit 5.6 ist es jetzt möglich wenigstens pro Plugin ein eigenes Log-File zu nutzen.
Mit dem doch sehr kompliziert einzustellen openVPN von Linux kann sich leider nicht mit einer Fritzbox verbinden. Dafür braucht man sehr simple Konsolen Programm vpnc, das auch besonders gut ist, wenn man mehrere VPN-Verbindungen managen muss, da man für jede Verbindung eine eigene Conf-Datei anlegen kann und diese auch ohne Probleme zwischen Systemen hin und her kopieren kann.
Erstmal braucht man vpnc
sudo apt-get install vpnc
Danach muss eine Config-Datei mit den Verbindungsdaten angelegt werden:
Alle Daten bekommt man nach dem Anlegen eines VPN-Benutzers in der Fritz direkt angezeigt und man sie sich in der Benutzerverwaltung immer wieder anzeigen lassen.
Der Verbindungsaufbau geschieht auch über die Konsole:
sudo vpnc ~/vpn.conf
Nun befindet man sich, wenn die Zugangsdaten richtig waren, im Netz der Fritzbox und kann auf alles im Netzwerk wie ein NAS oder MotionEye zugreifen.
Das Trennen der Verbindung geht auch sehr einfach:
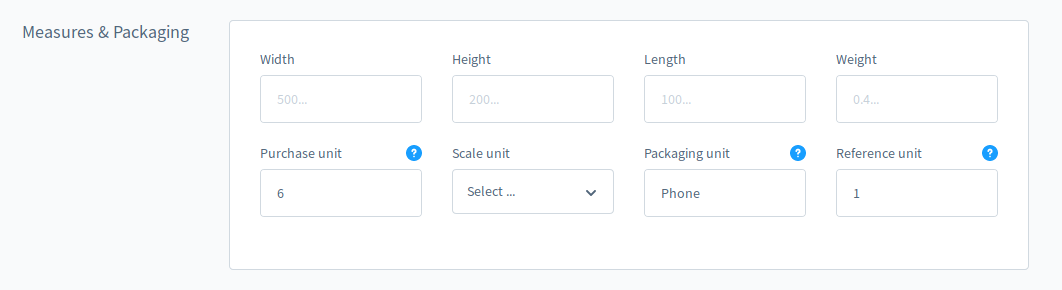
Ich habe gerade die Early Access Version von Shopware 6 installiert und erst einmal einen Hersteller und einen eigenen Artikel angelegt.
Das Problem war, dass ich keine Scale-Unit mit angeben konnte, da ich einfach noch keine angelegt hatte und nicht alle Artikeldaten nochmal neu eingeben wollte habe ich das Feld einfach leer gelassen. Speichern klappte ohne Probleme.
Die Kategorie funktionierte dann aber nicht mehr.
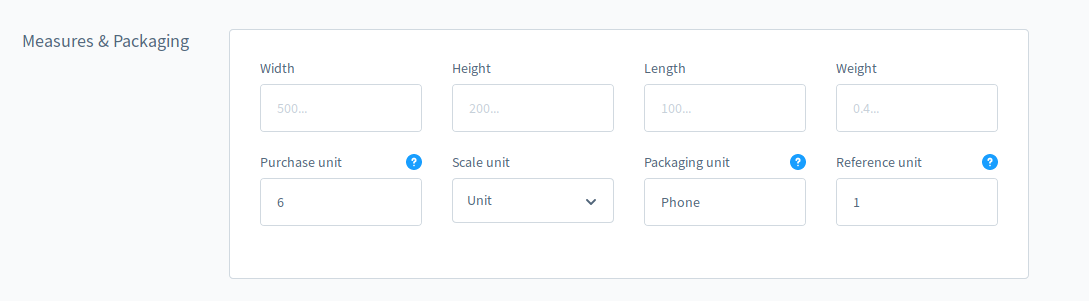
Zum Glück war mir das ja direkt aufgefallen, dass ich da was nicht eingeben konnte und habe erst einmal versucht eine Unit anzulegen und zu ergänzen.
Danach funktionierte es dann auch alles.
Da muss man also aufpassen, weil fehlende Eingaben noch viel kaputt machen können. Hab da auch gleich ein Issue dafür aufgemacht.
Hier einmal eine Default-Config für ElasticSearch unter Shopware 5. Gerade mit der Composer-Installation ist es sehr praktisch alle benötigten Felder direkt mal zu sehen.
Was hat sich eigentlich seit dem Kauf vom Alienware-Notebook (damals gebraucht für 750 EUR über Ebay-Kleinanzeigen) so getan.
Gaming-Notebooks sind meistens vergleichbar mit dem Mobile-Workstations des Herstellers, nur eben mit mehr RGB-LEDs. Das Alienware liefert immer noch gute Dienste bei Arbeit und Spielen. Es wurden nur mal die HDDs gegen eine SSD ausgetauscht.
Ich hab mit mal ein Lenovo Y520 als Vergleichsobjekt raus gesucht.
CPU: Beide haben ein i7 der damals vorletzten Generation.
RAM: Hier liegt das Alienware mit 16GB sogar vorne
GPU: GTX 1050 gegen eine nachgerüstete Quadro 3000K, da sehe ich die GTX 1050 in der gesamt Leistung + Stromverbrauch vorne
HDD/SSD: 128GB M.2 ist nicht viel, aber ok. Das Alienware war für die damalige Zeit auch gut ausgerüstet. Berücksichtig man die Zeit, liegen beide an sich gleich auf
Display: beide gleich, 15,6" halte ich sogar für etwas handlicher
Keyboard: DE gegen UK. Könnte man umbauen, aber ich habe mit UK/US Layouts nie schlechte Erfahrungen gemacht (schon seit Pentium Pro und WinNT-Zeiten)
Garantie: gibt es bei Ebay-Kleinanzeigen nicht.. deswegen musste die Quadro auch auf eigene Kosten nachgerüstet werden
Preis: 600 EUR ist da echt gut, dafür dass es von einem Händler kommt.
Im zeitlichen Kontext war das Alienware günstig und Lenovo Y520 (refurbished) noch günstiger... aber das Alienware funktioniert nicht mehr wie am ersten Tag, sondern durch SSD und Quadro sogar noch viel besser und macht einfach auch jedes Wetter mit.
Update: Das hier ist gerade auch 600 EUR teuer und gleicht alle Defizite des ersten Models aus. Y520 bekommt man also schon sehr günstig in guten Konfigurationen.. muss nicht immer Alienware/Dell sein.
Durch die Transition-Tag wird das Element eingeschlossen, dessen Änderung mit der Animation verknüpft werden soll. Der Name ist der der erste Teil des Animationsnamens.
.dialogbox-enter-active {
animation: open 0.8s;
}
.dialogbox-leave-active {
animation: open 0.4s reverse;
}
Jeder Java-Entwickler kennt es. Properties definieren und dann Setter und Getter erzeugen lassen. Wenn man was ändert, wird es nervig und wenn man was hinzufügt, muss man die fehlenden Methoden neu generieren lassen. Das geht an sich immer schnell, ist aber doch immer nervig.
Lombok übernimmt die Erzeugung dieser Methoden zur Compiling-Zeit. Die IDE benötigt ein Plugin und der Rest wird dann über Maven erledigt.
AngularJS hat beim IE (älter als Edge) ein Problem mit ng-change, wenn ein Input über eine DataList gefüllt wird. Dann wird einfach kein Event ausgelöst. Mit einer kleinen Hilf-Function und $scope.$applyAsync() in der Scope-Function kann man das aber reimplementieren.
function onChangeIE(value){
var ua = window.navigator.userAgent;
if((ua.indexOf('Trident/') > 0 || ua.indexOf('MSIE ') > 0) && ua.indexOf('Edge/') <= 0) {
angular.element(document.getElementById('my-ng-controller-element')).scope().myInputModel = value;
angular.element(document.getElementById('my-ng-controller-element')).scope().myNgChangeFunction();
Die beste Lösung wäre solche alten Browser nicht mehr zu supporten und dann vielleicht auch auf Vue.js oder eine aktuelle Angular-Version zu wechseln.
Aber für schnelles Prototypen, wo man wenig Code schreiben will, ist AngularJS noch immer sehr gut. Teilweise ist man so schnell damit, dass man während einer Diskussion die Ideen direkt nebenbei umsetzen und ausprobieren kann. Wenn man erst einmal viele Components schreiben muss, geht es nicht so gut, wie mit den AngularJS Templates und Dingen wie ng-options. Mit Vue.js ist man mit etwas Übung aber auch ähnlich schnell.
Older posts:
Möchtest Du AdSense-Werbung erlauben und mir damit helfen die laufenden Kosten des Blogs tragen zu können?
 bezahlt von
bezahlt von